由于博主很弱,只会打板子,请见谅
配对堆
一种极其好写又极其快速的堆
先看复杂度
空间复杂度:
时间复杂度:
插入:
合并:
查询最值:
删除元素:
修改元素:
反正就是
玄学
在进操作之前,先看看配对堆的结构
不熟练的面向对象及封装警告
配对堆是一种堆有序多叉树。根据要完成的操作,可以给出对该类的定义
template<typename T>
class pairing_heap
{
private:
struct Node;
Node* _root;
pairing_heap(Node*);
int s;
public:
struct iterator;
pairing_heap():_root(NULL),s(0) {}
pairing_heap(const pairing_heap<T>& hp):_root(hp._root),s(hp.s) {}
~pairing_heap() {}
iterator insert(const T&);
iterator join(pairing_heap<T>&);
bool modify(const iterator&,const T&);
T top();
void pop();
bool empty();
int size();
};
对每个结点,需维护其父亲及所有的儿子。为了方便在修改元素时将结点分离出来,这里采用双向链表来维护其儿子。具体地讲,父亲的son指针指向第一个儿子,同时每个节点又带有指向左右兄弟的指针域。
结点的结构体
template<typename T>
struct pairing_heap<T>::Node
{
Node* ftr;
Node* son;//子结点链表头
Node* prednode;//兄弟链表中的前驱
Node* nextnode;//后继
T val;
Node(T v=T(),Node* f=NULL):val(v),ftr(f),son(NULL),prednode(NULL),nextnode(NULL) {}
};
由于删除时要以每个儿子为根建树,再写一个特殊的构造函数
template<typename T>
pairing_heap<T>::pairing_heap(Node* rt):
_root(rt),s(0) {}
为了修改权值,再写出指向元素的迭代器
template<typename T>
struct pairing_heap<T>::iterator
{
private:
Node* _real__node;
public:
T operator*()const{return _real__node->val;}
iterator operator++()
{
return _real__node=_real__node->son;
}
iterator operator++(int)
{
iterator temp=*this;
_real__node=_real__node->son;
return temp;
}
iterator operator--()
{
return _real__node=_real__node->ftr;
}
iterator operator--(int)
{
iterator temp=*this;
_real__node=_real__node->ftr;
return temp;
}
bool operator==(const iterator& it)const
{
return _real__node==it._real__node;
}
bool operator==(const void* ptr)
{
return _real__node==ptr;
}
iterator(pairing_heap hp):_real__node(hp._root) {}
iterator(Node* ptr=NULL):_real__node(ptr) {}
iterator(const pairing_heap<T>::iterator& iter):_real__node(iter._real__node) {}
friend bool pairing_heap<T>::modify(const iterator&,const T&);
};
前置结构知识完
下面进操作
1.合并两个配对堆
很简单,直接比较两个根的大小,把大根接到小根的儿子表里就好辣!
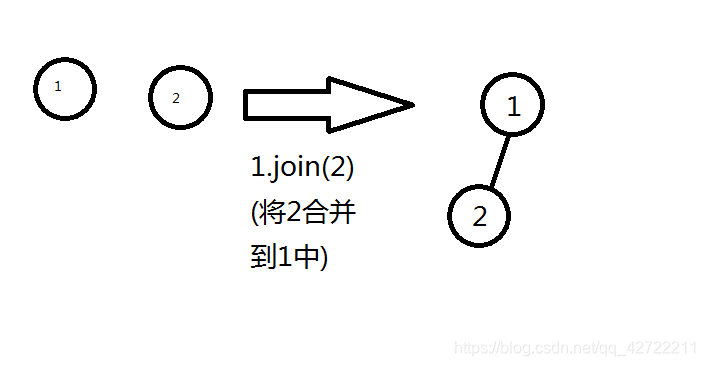
为什么不先讲插入?因为插入就是把只有一个元素的堆合并进去emm
为了能够修改任意元素,在这里返回出一个指向该元素的迭代器
template<typename T>
typename
pairing_heap<T>::iterator pairing_heap<T>::join(pairing_heap<T>& hp)
{
if(!_root||!hp._root) //注意特判,不然会炸!!!
{
_root=_root?_root:hp._root;
hp._root=NULL;
return iterator(_root);
}
if(hp._root->val>_root->val)
{
hp._root->ftr=_root;
hp._root->nextnode=_root->son;
if(_root->son)_root->son->prednode=hp._root;
_root->son=hp._root;
hp._root=NULL;
}
else
{
_root->ftr=hp._root;
_root->nextnode=hp._root->son;
if(hp._root->son)hp._root->son->prednode=_root;
hp._root->son=_root;
_root=hp._root;
hp._root=NULL;
}
s+=hp.s;
hp.s=0;
return iterator(_root);
}
显然,比较是
的,链表插入也是
的,因此整个合并操作也是
的。
更简单的计算:你看我根本没用循环和递归对不对?
2.插入
新建一个大小为1的堆,直接合并,不解释
template<typename T>
typename
pairing_heap<T>::iterator pairing_heap<T>::insert(const T& v)
{
if(!_root){_root=new Node(v);s=1;return iterator(_root);}
pairing_heap<T> temp;
temp.insert(v);
iterator iter(temp);
join(temp);
return iter;
}
3.查询最值
由于每个配对堆都是堆有序的,因此直接返回根值就行了。
复杂度显然也是
template<typename T>
T pairing_heap<T>::top()
{
return _root->val;
}
4.删除堆顶元素
一种显而易见的方法:直接暴力合并所有子树,单次复杂度
,最高
。
然而这样真的好吗?
用这种方法删除,最坏状况下新堆的根结点的儿子数仍是
,而这将导致后续删除操作的复杂度大大提高,显然与开始说均摊复杂度
不符。
那么如何优化呢?
下面是配对堆的灵魂所在,也是其名字的来源。
将儿子两两合并至原先数目的一半,再重复这个过程直至只剩1个堆,即为删除堆顶后的新堆。
复杂度最高
似乎没有变快?
但是新堆根结点的儿子个数少了!!!
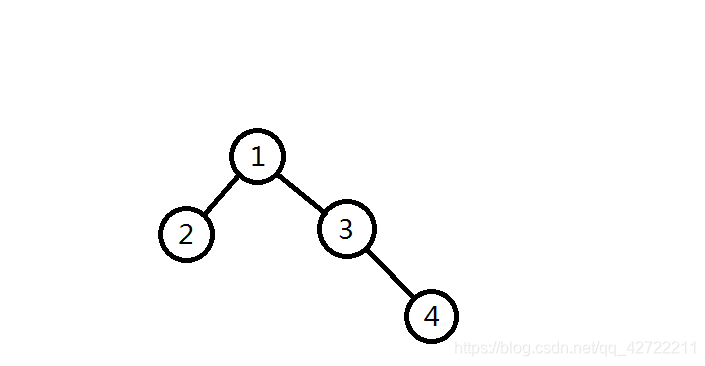
来这么考虑:
假设共
棵需合并的子树
从
开始

什么也不用做,新根的儿子数
手动滑稽

儿子数
儿子数
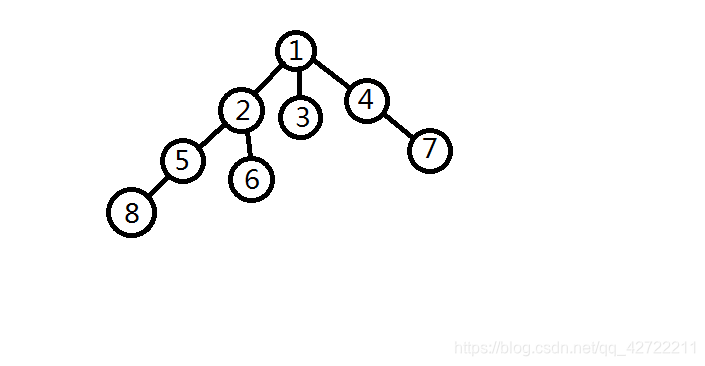
儿子数
发现了什么?
用这种方法,儿子数变成了
!
正是因为要一对一对地合并,这个骨骼清奇的数据结构才被冠以“配对堆”的诨号。
直接合并比较麻烦,我们把所有儿子放进队列里,每次取队首两个儿子合并,合并出的新儿子放入队尾,直至队列中只剩一个元素即可
template<typename T>
void pairing_heap<T>::pop()
{
if(!_root)return;
if(!_root->son){delete _root;_root=NULL;--s;return;}//注意特判堆为空或只有根的情况
int size_of_this=s;//由于不维护子树大小,因此要把开始的大小存起来
queue<pairing_heap> q;
for(Node* i=_root->son;i;i=i->nextnode)
{
q.push(pairing_heap(i));
}
while(q.size()>1)
{
pairing_heap<T> a(q.front());
q.pop();
pairing_heap<T> b(q.front());
q.pop();
a.join(b);
q.push(a);
}
*this=q.front();
q.pop();
s=size_of_this-1;
}
5.【神级操作】修改元素值
略过不提,以后讲。
为什么不提?因为我tmd写挂了
6.两个附加接口
就是STL里最常用的,很简单的辣!
template<typename T>
bool pairing_heap<T>::empty()
{
return _root?0:1;
}
template<typename T>
int pairing_heap<T>::size()
{
return s;
}
完结撒花!ヾ(◍°∇°◍)ノ゙
后记:
博主在学配对堆的前一天刚学了左偏树。本来以为已经是最好用的可并堆了,却在题解中偶然看到了配对堆,瞬间被它易懂的思想、简短的代码貌似被封装过也不短了和优异的时间复杂度震撼了,因此进行了学习。这里挂出所有我参考过的博文
博文1(似乎并不是OIer)
博文2(似乎是奆佬)
博文3(似乎还是奆佬)