前言
本篇是论文《Learning representations by back-propagating errors》的译文,论文原地址位于:http://www.iro.umontreal.ca/~pift6266/A06/refs/backprop_old.pdf ,虽然只有短短四页,但十分值得读。
正文
本篇文章的核心公式是本科时期高数书上的链式法则,如图:
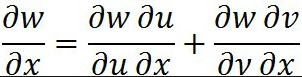
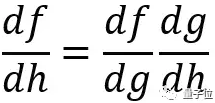
接下来我们用这个法则解释反向传播原理。
下面,我们使用最简单的神经网络来说明。这个网络只有3层,分别是蓝色的输入层、绿色的隐藏层和红色的输出层。上一层中的每个单元都连接到下一层中的每个单元,而且每个连接都具有一个权重,当某个单元向另一个单元传递信息时,会乘以该连接的权重得到更新信息。某个单元会把连接到它的上一层所有单元的输入值相加,并对这个总和执行Logistic函数并向下一层网络传递该值。
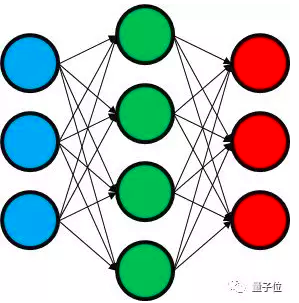
假设输入的样本数为m,第i个输入输出对为:(xi,yi)
其中,x和y是3维向量。对于输入x,我们把g称作神经网络的预测(输出)值,它也是一个3维向量,每个向量元素对应一个输出单元。所以,对于每个训练样本来说,有:

给定输入x,我们要找到使得预测值g与输出值y相等或比较相近的一组网络权重。因此,我们加入了误差函数,定义如下:
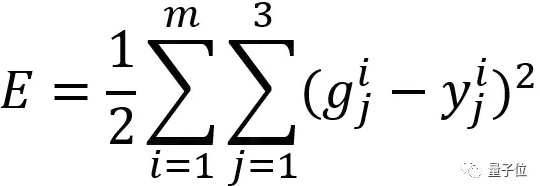
为了计算总误差,我们使用了训练集中的所有样本,并对红色输出层中的每个单元计算该单元预测值与真实输出间的平方误差。对每个样本分别计算并求和,得到总误差。
由于g为网络的预测值,取决于网络的权重,可以看到总误差会随权重变化而变化,网络的训练目标就是找到一组误差最小的权重。
这一点可以利用梯度下降法做到,但是梯度下降法要求算出总误差E对每个权重的导数,这也是结合反向传播要实现的目标。
现在,我们推广到一般情况,而不是之前的3个输出单元。假设输出层有任意数量的输出单元,设为n,对于这种情况此时的总误差为:
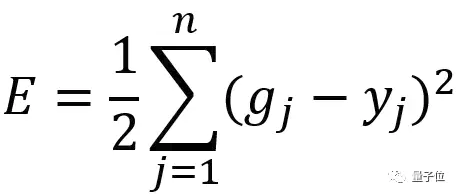
这里为了简洁,删去了上标i,因为它是不变的。
你可能会有疑问,这个误差值是怎么随着某个输出单元的预测值变化而变化的?我们通过求导得到总误差随着某个输出单元的预测值的变化关系。

我们发现随着预测值的变化,总误差会根据预测值与真实值之间的差值,以同样的速率在变化。
这里你可能还有疑问,当某个输出单元的总输入变化时,误差会如何变化。还是利用导数,用z来代表某个输出单元的总输入,求出下面公式的值:
![]()
但是发现g是关于z的函数,所以利用链式法则,把该式重写为:
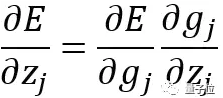
要记住,在每个单元中,先使用Logistic函数处理输入后再把它向前传递。这意味着,g作为Logistic函数,z是它的输入,所以可以表示为:
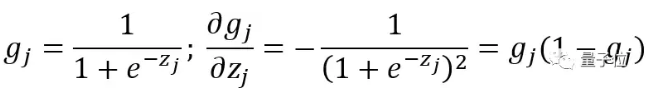
进而得到:
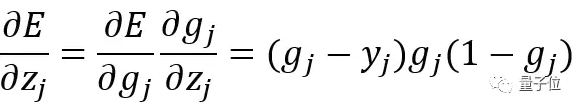
到了这步,已经计算得到总误差与某个输出神经元总输入的变化规律。
现在,我们已经得到了误差相对于某个权重的导数,这就是所求的梯度下降法。
aaaa