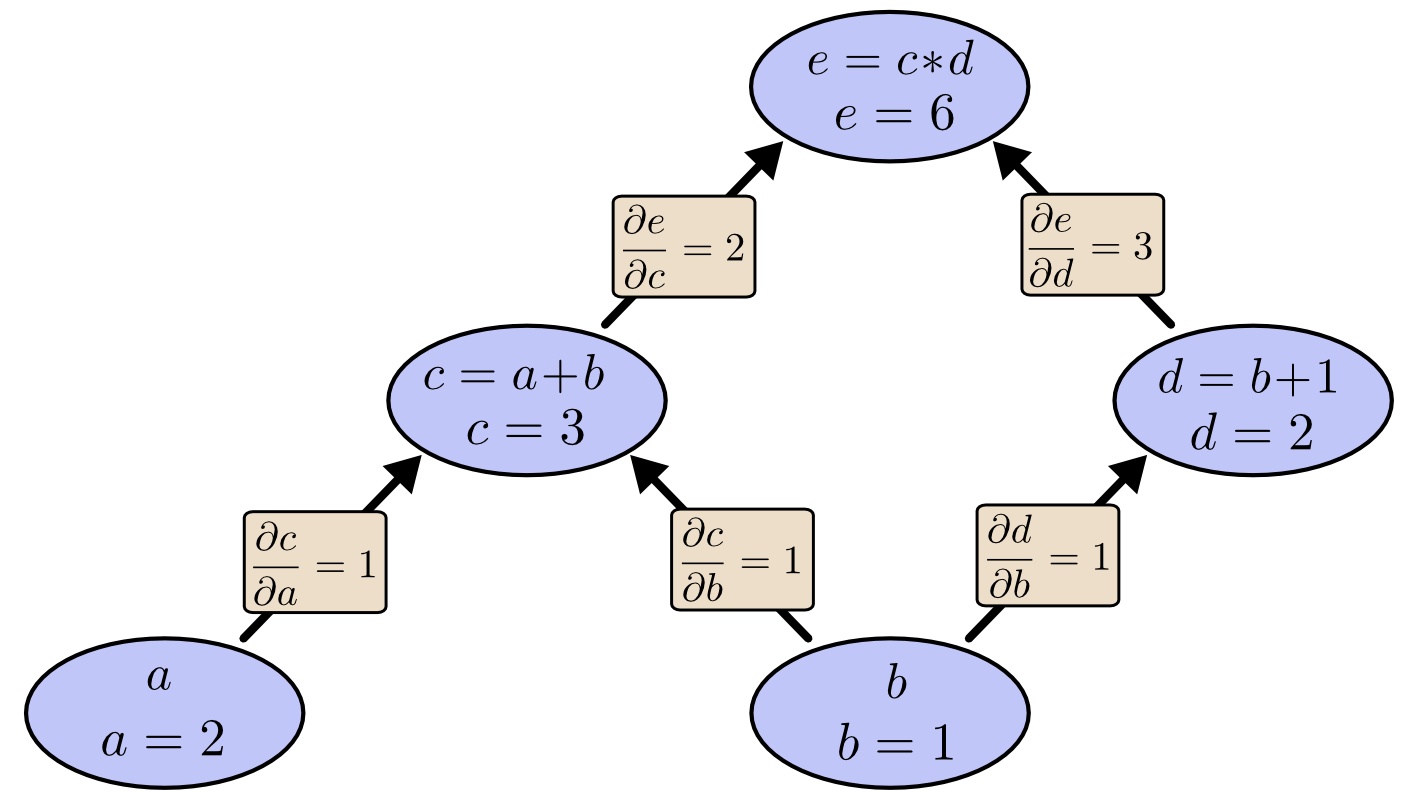
1、反向传播
简单的理解,反向传播的确就是复合函数的链式法则,但其在实际运算中的意义比链式法则要大的多。
链式求导十分冗余,因为很多路径被重复访问了,对于权值动则数万的深度模型中的神经网络,这样的冗余所导致的计算量是相当大的。
同样是利用链式法则,BP算法则机智地避开了这种冗余,它对于每一个路径只访问一次就能求顶点对所有下层节点的偏导值。正如反向传播(BP)算法的名字说的那样,BP算法是反向(自上往下)来寻找路径的。
2、反向传播理解举例
一个展示反向传播的例子。加法操作将梯度相等地分发给它的输入。取最大操作将梯度路由给更大的输入。乘法门拿取输入激活数据,对它们进行交换,然后乘以梯度。
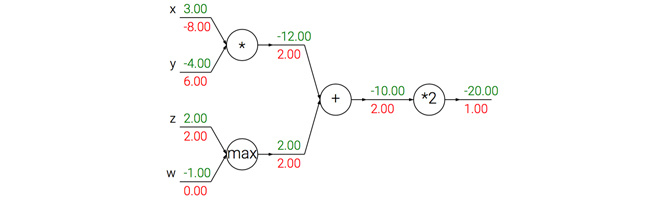
(1)加法门单元把输出的梯度相等地分发给它所有的输入,这一行为与输入值在前向传播时的值无关。这是因为加法操作的局部梯度都是简单的+1,所以所有输入的梯度实际上就等于输出的梯度,因为乘以1.0保持不变。上例中,加法门把梯度2.00不变且相等地路由给了两个输入。
(2)取最大值门单元对梯度做路由。和加法门不同,取最大值门将梯度转给其中一个输入,这个输入是在前向传播中值最大的那个输入。这是因为在取最大值门中,最高值的局部梯度是1.0,其余的是0。上例中,取最大值门将梯度2.00转给了z变量,因为z的值比w高,于是w的梯度保持为0。
(3)乘法门单元相对不容易解释。它的局部梯度就是输入值,但是是相互交换之后的,然后根据链式法则乘以输出值的梯度。上例中,x的梯度是-4.00x2.00=-8.00。
非直观影响及其结果。注意一种比较特殊的情况,如果乘法门单元的其中一个输入非常小,而另一个输入非常大,那么乘法门的操作将会不是那么直观:它将会把大的梯度分配给小的输入,把小的梯度分配给大的输入。在线性分类器中,权重和输入是进行点积,这说明输入数据的大小对于权重梯度的大小有影响。例如,在计算过程中对所有输入数据样本
乘以1000,那么权重的梯度将会增大1000倍,这样就必须降低学习率来弥补。这就是为什么数据预处理关系重大,它即使只是有微小变化,也会产生巨大影响。对于梯度在计算线路中是如何流动的有一个直观的理解,可以帮助读者调试网络。
转载自:https://zhuanlan.zhihu.com/p/21407711?refer=intelligentunit
https://www.zhihu.com/question/27239198/answer/89853077