反向传播
以下资料来自李宏毅老师《机器学习》2020春季-Back propagation
结合自己的学习笔记整理而成
在梯度下降的基础上,我们来看一下如何求出梯度,从而进行梯度下降,实现对参数的优化。
背景知识
背景知识很简单,只有链式法则:

如图,利用小学二年级学习的链式求导法则,实现对复合函数的求导,那么在我们的神经网络中,也是一样的道理。每一次的计算,都是一批样本(一个batch)的计算,那么Loss就是每一个Ln的加和,而加和不影响求导,所以下面的运算都将L视为加和后的L,Loss的选取有多种,例如MSE或者交叉熵,只要是可微分的形式就好。

我们知道一个神经元就是上面的样子(假设本层是输入层,有2个输入),那么利用链式法则将L(L是最终的损失函数)对w的偏导数写成L对z的偏导数和z对w的偏导数,显然z对w的偏导数就是输入x的数值,故很容易得到;之后,z通过一个激活函数就得到神经元的输出,故L对z的偏导数可以就是如下形式(假设激活函数为Sigmoid函数):

于是问题转化为了求L对a(a是本层的输出,也就是下一层的输入)的偏导数,继续利用链式法则,我们可以将L对a的偏导数写成L对下一层z的偏导数乘以z对a的偏导数的乘积的总和(总个数就是下一层神经元的个数),如下图:

这个式子中w是知道的,未知的只是L对下一层z的偏导数,我们发现这个问题就转化为上面的问题了,最终的求解形成了一个递归,递归的次数就是神经网络的层数,那么不如直接跳到最后的输出层:
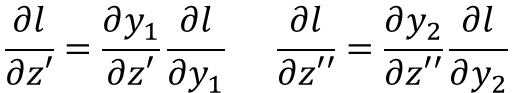
注意:这里假设了上图中的 z’和z’’ 通过激活函数就是输出y了,于是链式法则展开如上式,变成了激活函数的导数乘以L对y的偏导数,而L就是y和y-hat的函数,很容易就可以求出来。于是,结束了。
那么反向传播的反向体现在什么地方了呢?
Backward Pass
这是整个算法最精髓的部分!
这是整个算法最精髓的部分!
这是整个算法最精髓的部分!
我们在上面推导出如下式子:

即:
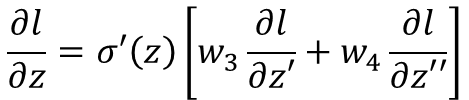
(σ’(z)是激活函数的导数)
这样子可能看不出来,将其表示成如下形式:

换了一种方向看问题,突然世界都变了!
我们将最初的

分为了两部分:
- ∂ z / ∂ w:这部分是前向传播(forward pass),因为在求导的时候是顺着神经网络输入的方向观察问题的,很容易求出值就是输入;
- ∂ L / ∂ z:这部分是后向传播(backward pass),因为在求导的时候是逆着神经网络输入的方向观察问题的,将这一步求偏导数需要用到的结果一步步转移到最终的输出层,于是变成了从后向前逐步计算此处的偏导数值;

以上讨论的问题是对第一层神经元对应参数的梯度的计算,也就是在第一层的空间更新参数的方向,其他层的情况可以类比。