记得大学刚毕业那年看了侯俊杰的《深入浅出MFC》,就对深入浅出这四个字特别偏好,并且成为了自己对技术的要求标准——对于技术的理解要足够的深刻以至于可以用很浅显的道理给别人讲明白。以下内容为个人见解,如有雷同,纯属巧合,如有错误,烦请指正。
因为leveldb很多类型的声明和实现分别在.h和.cc两个文件中,为了代码注释方便,我将二者合一(类似JAVA和GO类的定义方法),读者在源码中找不到我引用的部分属于正常现象。在阅读被文章之前请先阅读《深入浅出leveldb之基础知识》和《深入浅出leveldb之MemTable》
目录
言
在使用leveldb的时候,大家都知道leveldb是线程安全的,在我的认知里线程安全和高性能多半二者取其一。道理很简单,要想线程安全,一般都要有锁的参与,有锁参与很多时候无法实现较高的性能。当然这不是绝对的,无锁队列利用CPU的CAS指令实现原子操作是一种非常好设计,读写锁也是一个好用的东东,而leveldb中对于锁和原子的使用我也认为是一种非常不错的设计。
首先要强调的是leveldb的中锁和原子的使用多事基于leveldb的设计方案实现的,所以可能有些场景不适用,但是绝对是有参考价值的。
写操作的线程安全
有些东西用语言描述不清楚的时候,最好的办法就是用代码解释,下面的代码是leveldb写操作的源码,如果读者起初对于部分注释表示不清晰没有关系,继续往下看,等你把所有的注释都看完了再回头看就明白了。正所谓温故而知新~
// 代码源自leveldb/db/db_impl.cc
// 所有的leveldb写入操作最终都会变成如下代码所示的批量写入,无非是批量写一个还是写多个的问题
Status DBImpl::Write(const WriteOptions& options, WriteBatch* my_batch) {
// 此处先不要计较Writer是个什么东西,只要知道他是个结构体,用于记录此次写入的上下文(或者环境)
Writer w(&mutex_);
w.batch = my_batch; // 记录要写入的数据
w.sync = options.sync; // 记录要写入的选项,只有是否同步一个选项
w.done = false; // 写入的状态,完成或者未完成,当前肯定是未完成
// mutex_是leveldb的全局锁,在DBImpl有且只有这一个互斥锁(还有一个文件锁除外),所有操作都要基于这一个锁实现互斥
// 是不是感觉有点不可思议?MutexLock是个自动锁,他的构造函数负责加锁,析构函数负责解锁
MutexLock l(&mutex_);
// writers_是个std::deque<Writer*>,是DBImpl的成员变量,也就意味着多线程共享这个变量,所以是在加锁状态下操作的
writers_.push_back(&w);
// 看到下面的代码有意思么?这段代码保证了写入是按照调用的先后顺序执行的。
// 1.w.done不可能是true啊,刚刚赋值为false,为什么还要判断呢?除非有人改动,没错,后面有可能会被其他线程改动
// 2.刚刚放入队列尾部,此时如果前面有线程写,那么&w != writers_.front()会为true,所以要等前面的写完在唤醒
// 3.w.cv是一个可以理解为pthread_cond_t的变量,w.cv.Wait()其实是需要解锁的,他解的就是mutex_这个锁
while (!w.done && &w != writers_.front()) {
w.cv.Wait();
}
// 刚刚也提到了,虽然期望是自己线程把自己的数据写入,因为数据放入了writers_这个队列中,也就意味着别的线程也能看到
// 也就意味着别的线程也能把这个数据写入,那么什么情况要需要其他线程帮这个线程写入呢?“且听下面分解”
// 单田芳于昨日去世,作为粉丝纪念一下单田芳老爷子
if (w.done) {
return w.status;
}
// 这个就是要判断当前的空间是否能够继续写入,包括MemTable以及SSTable,如果需要同步文件或者合并文件就要等待了
// 读者自行分析那部分代码,或者等一段时间看我对这部分源码的分析
Status status = MakeRoomForWrite(my_batch == NULL);
// 获取当前最后一个顺序号,这个好理解哈
uint64_t last_sequence = versions_->LastSequence();
// 接下来就是比较重点的部分了,last_writer记录了一次真正写入的最后一个Writer的地址,就是会合并多个Writer的数据写入
// 当然,初始化是当前这个线程的Writer,因为很可能后面没有其他线程执行写入
Writer* last_writer = &w;
// 开始写入之前需要保证空间足够并且确实有数据要写
if (status.ok() && my_batch != NULL) { // NULL batch is for compactions
// 此处就是合并写入的过程,函数名字也能看出这个意思,感兴趣的读者自行看代码
WriteBatch* updates = BuildBatchGroup(&last_writer);
// 为合并后的每条记录都设置顺序号,不是什么重点,函数后面也不会展开分析
WriteBatchInternal::SetSequence(updates, last_sequence + 1);
// 更新顺序号,先记在临时变量中,等操作全部成功后再更新数据库状态
last_sequence += WriteBatchInternal::Count(updates);
// 前方高能,请读者注意
{
// 此处解锁了,也就意味着其他线程可以同时读取或者写入leveldb,写入肯定会被放到writers_队尾等待
// 那读取该如何保证线程安全性,解锁后毕竟还是要操作MemTable的,这个后面章节会有详细说明
// 这里要说明的是,因为写入操作要有文件写入,必要时还有文件同步,如果不解锁性能肯定很低
mutex_.Unlock();
// log_可以想象为一个文件,AddRecord可以想象为文件的追加(append)操作,就是所有记录是先追加到日志文件
// 因为写入的这个流程设计永远都保证一个线程操作这个日志文件,所以不会出现乱序问题,而读取是访问MemTable
// 所以不需要在加锁状态先执行
status = log_->AddRecord(WriteBatchInternal::Contents(updates));
// 如果用户配置了同步选项,那么就要执行文件同步操作,可以想象为flush(),这样比较安全,但是性能会第一点
bool sync_error = false;
if (status.ok() && options.sync) {
status = logfile_->Sync();
if (!status.ok()) {
sync_error = true;
}
}
// 写入日志文件成功,那么就要把数据同步到MemTable中了
if (status.ok()) {
status = WriteBatchInternal::InsertInto(updates, mem_);
}
// 耗时的操作都完事了,重新进入加锁状态,后面要操作共享资源
mutex_.Lock();
// 如果上面的过程失败了,那么就要唤醒所有的线程报错
if (sync_error) {
RecordBackgroundError(status);
}
}
if (updates == tmp_batch_) tmp_batch_->Clear();
// 更新最新的顺序号,因为写入操作已经成功
versions_->SetLastSequence(last_sequence);
}
// 还是比较有趣的代码,由于此次写入可能会批量的把后面的多个数据一并写入,所以此处就要逐一的告知后面写入的线程
while (true) {
// 从writers_取出一个元素
Writer* ready = writers_.front();
writers_.pop_front();
// 判断这个Writer是不是自己线程的数据,如果不是,那就告诉那个线程数据已经被写入了
if (ready != &w) {
ready->status = status;
ready->done = true; // 设置完成标记,上面的代码我们知道线程被唤醒后要判断这个标记
ready->cv.Signal(); // 唤醒这个阻塞的线程,注意:当前还没有解锁,所以线程还没有真正被唤醒
}
// 直到处理完最后一个Writer为止
if (ready == last_writer) break;
}
// 如果writers_中还有数据,那就把列表头中的那个线程唤醒,因为前面唤醒的是被这个线程一并顺带写入的数据的线程
// 这些线程唤醒后直接回返回,不会继续唤醒后面的线程
if (!writers_.empty()) {
writers_.front()->cv.Signal();
}
return status;
}如果一次没看懂没关系,那就多看几次就明白了~我这里总结一下leveldb实现写操作的几个关键点:
- 通过std::deque实现写入线程按照调用时间先后顺序执行,这就保证了写入操作的线程安全性;
- 实际写入是在无锁状体下执行的,意味着执行文件和MemTable写入的同时可以读取和继续向std::deque中追加,这样的设计就为合并多次写入操作提供了条件;比如在写第一条数据的时候因为在加锁状态下无法合并第二条及以后的数据(因为此时线程因为锁而挂起),但是第一条数据写入文件过程中第二、三、四......条数据已经在std::deque中排队了,那么开始写入第二条数据的时候就可以合并第三、四....条数据了;
- 因为数据的合并写入,使得写入性能相比于逐条写入提升不少,尤其是在有同步选项的时候;
读写操作的线程安全
上面我们分析了leveldb的写入线程安全,因为std::deque、mutex、cond的巧妙使用,使得写入线程可以排队按序执行。但是在无锁状态下读取和写入是如何保证线程安全的呢?这就是这个章节讨论的重点了。
首先,我们需要明确一点,写入操作在无锁状态下只会操作日志文件和MemTable,MemTable其实就是日志文件的内存副本,只是表现形式不同罢了。那么我们分析的切入点就变得很简单了,因为其他在有锁状态下执行也就没必要分析所谓的线程安全了。而读取操作在无锁状态只会访问MemTable和SSTable,不难看出二者的交叉点在MemTable,只要保证MemTable是线程安全的就可以了。这时候我相信大部分人第一想法是在MemTable加锁,确实又简单又方便,但是google大神可不这么认为,大神用的是原子指针实现的。看过我《深入浅出leveldb之MemTable》的读者知道,整个代码没看到任何锁的痕迹。当初我分析MemTable的时候就不理解为啥要用这老多的原子指针,直到我开始这篇博客的时候才算真正理解大神的用意。好了,整那老多臭氧层也没啥用,咱们说重点。
MemTable其实只是一个壳子(基本上就是在封装),真正的实现还是SkipList,所以SkipList才是我们真正要分析的。具体写入的代码此处不再分析了(看《深入浅出leveldb之MemTable》就可以了),我们用一个图来表达写入的过程:
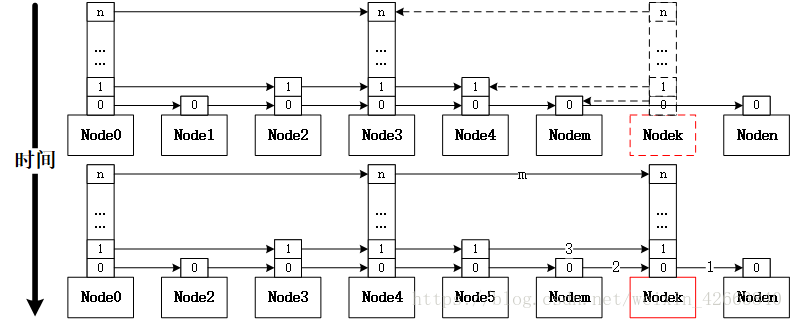
上图中,红色的是需要插入的节点(数据),虚线表示为局部变量,因为局部变量是线程安全的,所以通过局部变量记录了新节点需要插入时前向节点都是哪些(跳跃表每个节点都是有高度的,每个高度都有链表)。 然后先将节点的指针依次指向后向节点,再将Node的前向节点依次执行自己,依次的顺序是高度从低到高(如上图所示序号1、2、3.......m)。这个过程中所有获取和设置指针都是原子指针操作,所以写入和读取都不会有打断情况,也就是说保证写入和读取。有人肯定会问,难道这就能保证线程安全了么?答案是肯定的,我们来分析这个过程:
- 整个写入过程操作链表的时候有两个步骤,分别是先让节点指向后向节点,然后再让前向节点指向自己,第一步因为没有实际操作链表,所以本身就是安全的,只有第二步执行的过程如果线程切换或者同时读取(毕竟都是多核的机器)才会有可能存在不安全的可能;
- 因为节点有高度,每个高度都要操作一次指针,所以整个过程并不是原子的,如果读取时通过节点m访问下一个节点是节点n,但是因为同时执行写入实际读取却是k(因为读取要seek,先比较再偏移下一个,是一个两步操作),此时无非再通过节点k向节点n逼近一次就可以了,并不影响安全;
- 因为无论是写入还是读取(通过迭代器顺序读取除外),都是先要seek,即定位,seek是从高到低方式访问链表逐渐逼近期望节点,而节点插入是从低到高插入链表,一旦seek过程访问了还没有插入完毕的节点时,该节点的低于当前高度的链表已经插入完毕,所以也不存在安全问题;
- 如果通过迭代器遍历节点时,因为写入和读取指针都是原子的,所以也不存在安全问题;
- 所有的这一切源于一个大家可能不太在乎的关键点,那就是采用的单向链表,单向链表插入实际上只有一步操作,只要这个操作是原子的可以保证安全,这也是我在《深入浅出leveldb之MemTable》提到迭代器反向遍历效率低,MemTable没有采用双向量表的核心原因,毕竟正向遍历的使用概率还是比较高的;
- 因为MemTable没有删除操作,永远是添加操作,也进一步巩固了该设计方案,因为删除操作会存在不安全的可能,即便通过前向节点直接指向后向节点一步操作实现删除,但是问题在于本应该移动到节点k,实际确移动到了节点n,比较时节点k是小于指定键的,而实际偏移到的节点n可能大于指定键;
总结
经过系统性的分析,我们了解到leveldb实现高性能安全读写的几个关键点:
- 利用队列将写入线程排队有序执行,写操作实现了逻辑上的单线程操作;
- 在写入文件和MemTable过程是无锁状态,此时可以同时写入和读取数据,合并多个数据写入进一步提升写入性能;
- 利用原子指针代替锁避免了锁本身带来的线程切换开销;
- 能用原子指针的必要条件是单向链表和无删除操作;