记得大学刚毕业那年看了侯俊杰的《深入浅出MFC》,就对深入浅出这四个字特别偏好,并且成为了自己对技术的要求标准——对于技术的理解要足够的深刻以至于可以用很浅显的道理给别人讲明白。以下内容为个人见解,如有雷同,纯属巧合,如有错误,烦请指正。
因为leveldb很多类型的声明和实现分别在.h和.cc两个文件中,为了代码注释方便,我将二者合一(类似JAVA和GO类的定义方法),读者在源码中找不到我引用的部分属于正常现象。在阅读被文章之前请先阅读《深入浅出leveldb之基础知识》
前言
众所周知,leveldb之所以有level这个单词就是因为数据存储分层管理,而日志和内存表处于第0层,我们这篇文章探究的就是这个内存表(memtable)的实现。因为memtable比较大,如果在一个代码页把memtable全部注释会非常乱,而且没有结构性。所以我们先浏览一遍memtable类型,然后每个章节分析一部分,能够较大提升阅读性。
// 代码源自leveldb/db/memtable.h
class MemTable {
public:
// 构造函数,需要提供InternalKeyComparator的对象,InternalKeyComparator在《深入浅出leveldb之基础知识》里有介绍
// 这表明在MemTable中是通过InternalKey进行排序的,否则要InternalKeyComparator干什么用呢?
explicit MemTable(const InternalKeyComparator& comparator);
// 自己实现了智能指针
void Ref() { ++refs_; }
void Unref() {
// 看到没有,没有任何同步造作,说明MemTable的使用者必须做了同步,请记住这点!
--refs_;
assert(refs_ >= 0);
if (refs_ <= 0) {
delete this;
}
}
// 评估一下当前的内存使用量,总不能无限制的使用下去不是,到了一定量就要写入sst了。
size_t ApproximateMemoryUsage();
// 创建迭代器,用来遍历MemTable中的对象,迭代器的定义在《深入浅出leveldb之基础知识》里有介绍
Iterator* NewIterator();
// 向MemTable中添加对象,提供提供了用户指定的键和值,同时还提供了顺序号和值类型,说明顺序号是上级(leveldb)别产生的
// 如果是删除操作,value应该没有任何值
void Add(SequenceNumber seq, ValueType type, const Slice& key, const Slice& value);
// 有写就得有读,提供的是查询键(在《深入浅出leveldb之基础知识》里有介绍),输出对象值和状态,并且返回是否成功
bool Get(const LookupKey& key, std::string* value, Status* s);
private:
// 私有的析构函数,要求使用者只能通过Unref()释放对象
~MemTable() { assert(refs_ == 0); }
// 自定义了比较器,说明在InternalKey基础上又进行了扩展,但最终还是通过InternalKeyComparator实现的比较
struct KeyComparator {
const InternalKeyComparator comparator;
explicit KeyComparator(const InternalKeyComparator& c) : comparator(c) { }
// 这里可以看出来进入比较的已经不是Slice,是一个buf,所以需要比较器解析buf
int operator()(const char* a, const char* b) const;
};
// 表是用SkipList(跳跃表)实现的
typedef SkipList<const char*, KeyComparator> Table;
// 成员变量包括:比较器、引用计数、内存管理和跳跃表
KeyComparator comparator_;
int refs_;
Arena arena_;
Table table_;
// 定义在私有域,禁止拷贝构造和赋值操作
MemTable(const MemTable&);
void operator=(const MemTable&);
};好了,初步对MemTable有了了解,即便有一些内容还不理解,接下来我们就要逐一攻破了。在开始之前我们需要先统一概念:
- 用户键:通过leveldb的接口操作对象时的对象键,类型为Slice,此处指的是Slice里面的值;
- 用户值:和用户键对对应的对象的值;
- 内部键:主要是的是InternalKey所存储的内容;
- 跳跃表建:跳跃表定义的键,后面章节会有详细说明;
正因为MemTable内部对键做个多种类型转换,所以在类型转换中需要有更加准确的定义来区分差异,所以统一概念很有必要。
KeyComparator
KeyComparator定义在MemTable类内,属于私有类型。从名字上看不难理解是比较Key,在《深入浅出leveldb之基础知识》我们介绍过InternalKeyComparator,此处的KeyComparator又有什么不同呢?
// 代码源自leveldb/db/memtable.h
// 在浏览MemTable类的时候我们简单过了一下KeyComparator ,现在我们要进行详细说明
struct KeyComparator {
// 需要内部键比较器的支持
const InternalKeyComparator comparator;
// 构造函数需要传入内部键比较器
explicit KeyComparator(const InternalKeyComparator& c) : caomparator(c) { }
// 重载了运算符(),比较的两个对象是const char*类型,这里一个buf存储着一条记录
// 记录的存储格式是[内部键长度(varint32)][internalkey][值长度(varint32)][value]
int operator()(const char* a, const char* b) const {
// 比较前就要先提取内部键然后在用InternalKeyComparator比较就可以了,提取函数键下面代码
Slice a = GetLengthPrefixedSlice(a);
Slice b = GetLengthPrefixedSlice(b);
return comparator.Compare(a, b);
}
};
// 代码源自leveldb/db/memtable.cc
static Slice GetLengthPrefixedSlice(const char* data) {
uint32_t len;
const char* p = data;
p = GetVarint32Ptr(p, p + 5, &len); // +5是因为Varint32最长是5个字节,这样比较保险
return Slice(p, len);
}从这里可以看出用户传入leveldb的key和value经过InternalKey封装了key之后,InternalKey和value统一存在一个buf内,并在MemTable中管理(后面SkipList章节就会看到存储的过程,这里提前介绍了),所以重新实现了比较器。所以,真正比较的还是InternalKey。
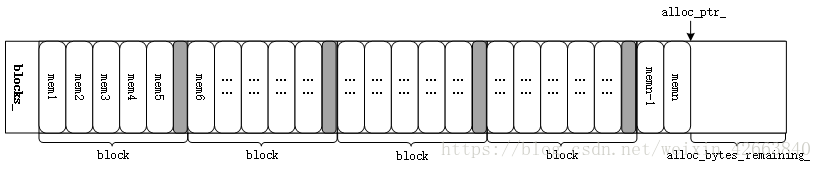
Arena
MemTable是内存表,有自己的内存管理方式,Arena就是负责内存管理的。我们现在就来看看Arena提供了哪些能力:
// 代码源自leveldb/util/arena.cc
static const int kBlockSize = 4096; // 定义了一个内存块的大小
// 代码源自leveldb/util/arena.h
// Arena类定义
class Arena {
// 把成员变量提到前面注释,否则好多函数没法注释了
private:
// Arena管理的内存是由一个个的内存块组成,每个内存块大小由常数kBlockSize定义,当申请的内存超过一个阈值时
// 则直接申请一个相应大小的内存块给使用者,否则多次申请的内存会复用一个内存块,只是每个人使用的是内存块上的不同地址而已
char* alloc_ptr_; // 指向最新内存块剩余空间的首地址
size_t alloc_bytes_remaining_; // 记录最新内存块还有多少剩余空间可用
std::vector<char*> blocks_; // 所有申请的内存块都通过std::vector管理
port::AtomicPointer memory_usage_; // 内存使用量统计,采用原子指针实现,其实就是原子操作整型数据
public:
// 构造函数,因为初始化的时候没有内存块,指针为空,剩余可用的大小为0
Arena() : memory_usage_(0) {
alloc_ptr_ = NULL;
alloc_bytes_remaining_ = 0;
}
// 析构函数
~Arena() {
// 释放所有的内存块
for (size_t i = 0; i < blocks_.size(); i++) {
delete[] blocks_[i];
}
}
// 申请一个bytes大小的内存空间
char* Allocate(size_t bytes) {
assert(bytes > 0);
// 看看最新申请的内存块中剩余空间是否够用?
if (bytes <= alloc_bytes_remaining_) {
// 如果够用,那就在最新的内存块中拨相应大小的内存出去,操作很简单,指针偏移,剩余空间减去申请量
char* result = alloc_ptr_;
alloc_ptr_ += bytes;
alloc_bytes_remaining_ -= bytes;
return result;
}
// 最新的内存块剩余空间不够那就只能重新申请内存块了,下面会对AllocateFallback()进行详细说明
return AllocateFallback(bytes);
}
// 相比于Allocate(),申请地址要对齐,其实我们用new()/malloc()申请的内存一般都是8字节对齐的
// 所以有些情况是需要按照地址对齐方式申请内存的。
char* AllocateAligned(size_t bytes) {
// 默认是8字节对齐,当然如果64位以上的指针那就按照系统提供的方式对齐
const int align = (sizeof(void*) > 8) ? sizeof(void*) : 8;
// 对齐长度必须是2的指数值,比如8、16、32
assert((align & (align-1)) == 0);
// 获取当前最新内存块可用空间的首地址现对于对齐地址偏移了多少
size_t current_mod = reinterpret_cast<uintptr_t>(alloc_ptr_) & (align-1);
// 因为分配的地址要对齐,所以要计算出来要将当前可用地址再偏移多少才能对齐
size_t slop = (current_mod == 0 ? 0 : align - current_mod);
// 所以实际申请的内存大小要加上对齐偏移量
size_t needed = bytes + slop;
char* result;
// 下面的部分和Allocate()一样了。
if (needed <= alloc_bytes_remaining_) {
result = alloc_ptr_ + slop; // 要把地址偏移到对齐的地方
alloc_ptr_ += needed;
alloc_bytes_remaining_ -= needed;
} else {
// 因为申请新的内存块的首地址肯定是对齐的,所以大小就要调整回来了
result = AllocateFallback(bytes);
}
assert((reinterpret_cast<uintptr_t>(result) & (align-1)) == 0);
return result;
}
// 获取内存使用量,还记得MemTable.ApproximateMemoryUsage()么?就是通过这个函数实现的
// 上面的各种申请函数貌似我们没有看到memory_usage_的统计,其实这个统计是在申请内存块的时候统计的
size_t MemoryUsage() const {
return reinterpret_cast<uintptr_t>(memory_usage_.NoBarrier_Load());
}
private:
// 最新内存块剩余空间已经不够用了就需要调用这个函数申请内存
char* AllocateFallback(size_t bytes) {
// 申请空间比内存块的四分之一还大,就直接分配一个内存块给他,没必要复用内存块了
if (bytes > kBlockSize / 4) {
// AllocateNewBlock()后面有详细说明
char* result = AllocateNewBlock(bytes);
return result;
}
// 申请一个新的内存块
alloc_ptr_ = AllocateNewBlock(kBlockSize);
alloc_bytes_remaining_ = kBlockSize;
// 新内存块的首地址就是要返回的内存地址
char* result = alloc_ptr_;
// 可用的内存地址就改到最新的内存块上,当然,要刨除刚刚分配出去的那点内存
alloc_ptr_ += bytes;
alloc_bytes_remaining_ -= bytes;
return result;
}
// 申请新的内存块
char* AllocateNewBlock(size_t block_bytes) {
// 申请内存块
char* result = new char[block_bytes];
// 地址放入vector中析构的时候用于释放内存
blocks_.push_back(result);
// 累计内存使用量,注意没有为什么加了个sizeof(char*)?我认为这个值是为了把vector使用内存也统计进去
memory_usage_.NoBarrier_Store(reinterpret_cast<void*>(MemoryUsage() + block_bytes + sizeof(char*)));
return result;
}
// 禁止拷贝构造函数和赋值操作
Arena(const Arena&);
void operator=(const Arena&);
};看来代码,Arena没什么高深的内容,只是把内存用块的方式管理,然后再把内存块一点一点的分配出去。有没有发现这个内存管理只负责申请不负责重复利用,也就是只有malloc()没有free()。这主要原因是MemTable本身就是持续的追加操作,当内存量超过阈值后整体要写入文件,所使用的内存一并释放掉,所以Arena也就比较简单。但是Arena有一个缺点,就是当申请的内存大小频繁的比最新块的剩余空间大时,就会出现一些内存浪费。这些内存浪费相比于每次都从系统堆上申请带来的开销(浪费的内存和性能损失)要更值得,所以leveldb选择了Arena。
SkipList
有了Arena基本知道了MemTable每个对象的键、值的内存是如何管理的了,接下来就要看MemTable是将对象如何有效的组织成一个可以快速插入和检索的数据结构的。
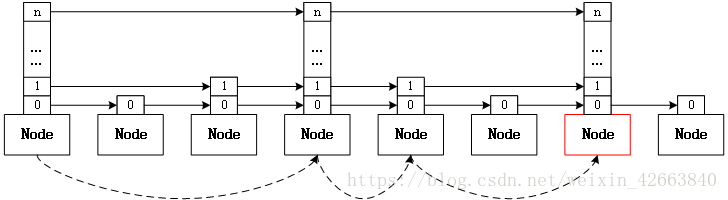
SkipList(跳跃表)检索复杂度为log(n),同时实现复杂度要比std::map要简单,关于跳跃表的原理请参看《算法:C语言实现(第1~4部分)》一书的13.5章节。本章节直接从代码上看leveldb跳跃表的实现,如下图所示,如果想找到红色的节点,从表头开始高度从高到低逐渐逼近目标节点,效果如同下面虚线一样,这就是所谓的跳跃。
SkipList
SkipList相对来说也是一个比较重要类型,内部包含了多种类型的数据,所以我们从总分的方式对SkipList进行分析,所以先预览一下这个类型:
// 代码源自leveldb/db/skiplist.h
// 这是个模板类,需要提供键类型和比较器,在预览MemTable类的时候传入的是什么类型还记得么?
// 键类型是const char*,比较器是MemTable.Comparator
template<typename Key, class Comparator>
class SkipList {
// 老规矩,先介绍成员变量
private:
Comparator const compare_; // 比较器,就是MemTable.Comparator的实例对象
Arena* const arena_; // 内存管理器,就是&MemTable.arena_
Node* const head_; // 链表头,类型定义会在后面的章节介绍
port::AtomicPointer max_height_; // 跳跃表的当前最大高度
Random rnd_; // 随机数生成器
public:
// 构造函数,需要传入比较器和内存管理器Arena
explicit SkipList(Comparator cmp, Arena* arena)
: compare_(cmp),
arena_(arena),
// 关于Node、Skiplist相关的内容后面会有介绍,这里只是做了初始化
head_(NewNode(0 /* any key will do */, kMaxHeight)),
max_height_(reinterpret_cast<void*>(1)),
rnd_(0xdeadbeef) {
for (int i = 0; i < kMaxHeight; i++) {
head_->SetNext(i, NULL);
}
}
// 向跳跃表中插入一条记录,我更倾向于叫记录而不是key,因为这个key是用户指定的key和value的编码后的值
void Insert(const Key& key) {
// 这个临时变量用于记录所找到节点在各个高度的前向节点的指针
Node* prev[kMaxHeight];
// 找到第一个大于等于key的节点,因为我们要把新的记录插入到这个节点前面
Node* x = FindGreaterOrEqual(key, prev);
assert(x == NULL || !Equal(key, x->key));
// 这个是leveldb比较有意思的地方,插入一个节点的高度是一个随机值,当然不是一个想象的随机值
// 否则高度为10的节点和高度为1的节点数量相同,这本身就不符合跳跃表的特性,该随机函数高度越高
// 生成的概率越低,近似成跳跃表对于节点高度的要求,我没有对随机算法做深入研究,这种用计算实现的策略算是比较好的
// 但凡能用计算解决的就不要用各种if else,因为这样代码更优雅,就是可读性差一点
// 虽然算法上实现比较优雅,但是可能存在一些风险,比如高度比较高的节点可能并没有分散开
int height = RandomHeight();
// 是否已经超过了当前最大高度,由于跳跃表初始没有节点,所以最大高度可能为0,随着记录增多,高度慢慢提升
if (height > GetMaxHeight()) {
// 超过了最大高度的话,具备此高度的节点只有头结点,所以把高出来的那部分前一个节点都指向头结点
for (int i = GetMaxHeight(); i < height; i++) {
prev[i] = head_;
}
// 更新最高高度
max_height_.NoBarrier_Store(reinterpret_cast<void*>(height));
}
// 创建新的节点对象
x = NewNode(key, height);
// 把节点连接到跳跃表中,当然是每个高度都是单独连接的
for (int i = 0; i < height; i++) {
// 按照单项链表的方式指向:curr->prev.next, prev->curr
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
prev[i]->SetNext(i, x);
}
}
// 判断跳跃表中是否有指定的数据,等同于std::map.find()
bool Contains(const Key& key) const {
// 实现方式是利用查找方式,找到的如果等于就返回true,否则返回false
Node* x = FindGreaterOrEqual(key, NULL);
if (x != NULL && Equal(key, x->key)) {
return true;
} else {
return false;
}
}
// 迭代器声明,详情请看迭代器章节,里面对迭代器做了详细的解析
class Iterator {
......
};
private:
// 跳跃表最高高是12
enum { kMaxHeight = 12 };
// 获取当前跳跃表的当前最大高度
inline int GetMaxHeight() const {
return static_cast<int>(reinterpret_cast<intptr_t>(max_height_.NoBarrier_Load()));
}
// 节点的构造函数,后面的Node章节有详细分析
Node* NewNode(const Key& key, int height);
// 随机的获取一个高度,本文不打算对这个"随机"做分析,所以暂时做到了解就可以
int RandomHeight();
// 判断两个件是否相等,实现比较简单,没什么可以解释的
bool Equal(const Key& a, const Key& b) const { return (compare_(a, b) == 0); }
// 判断key是不是大于节点n的key,也就意味着如果存在key的节点,那么就会在节点n的后面
bool KeyIsAfterNode(const Key& key, Node* n) const {
// 所以实现方式就是键的比较
return (n != NULL) && (compare_(n->key, key) < 0);
}
// 找到第一个大于等于给定的键的节点,通过跳跃的方式查找
Node* FindGreaterOrEqual(const Key& key, Node** prev) const {
Node* x = head_; // 从表头开始
int level = GetMaxHeight() - 1; // 从最高高度开始
while (true) {
// 如果节点的key小于指定的key,那就从这节点继续往后逐渐向目标逼近,因为节点是从小到大有序的
Node* next = x->Next(level);
if (KeyIsAfterNode(key, next)) {
x = next;
} else {
// 走到这里,当前高度的下一个节点已经比指定的键笑了,所以要降低一个一个高度继续搜索,输出当前高度的前一个节点指针
if (prev != NULL) prev[level] = x;
// 到了最底层了,那就直接返回下一个节点就可了,因为当前节点x的key要比给定的key小
if (level == 0) {
return next;
} else {
// 否则就下降一个高度继续逼近
level--;
}
}
}
}
// 返回第一个比key小的节点,通过跳跃的方式查找
Node* FindLessThan(const Key& key) const {
Node* x = head_; // 从表头开始
int level = GetMaxHeight() - 1; // 从最高高度开始,逐渐降低高度,减少跨度
while (true) {
assert(x == head_ || compare_(x->key, key) < 0);
// 相应高度的下一个节点
Node* next = x->Next(level);
// 如果没有节点或者节点比给定的键大,那就降低一个高度
if (next == NULL || compare_(next->key, key) >= 0) {
// 如果已经是最低高度了,那当前的节点就是要找的节点了
if (level == 0) {
return x;
} else {
level--;
}
} else {
// 如果当前节点比指定的键小,那么就从当前节点继续向指定的键逼近
x = next;
}
}
}
// 找到最后一个节点,通过跳跃的方式查找
Node* FindLast() const {
Node* x = head_; // 从表头开始
int level = GetMaxHeight() - 1; // 从最高高度开始
while (true) {
// 下一个节点如果为空,就代表当前这层的到结尾了
Node* next = x->Next(level);
if (next == NULL) {
// 最底层的话当前节点就是最后一个了
if (level == 0) {
return x;
} else {
// 否则的话就继续下降高度
level--;
}
} else {
// 继续完后找,直到当前层的结尾
x = next;
}
}
}
// 避免拷贝构造函数和赋值操作
SkipList(const SkipList&);
void operator=(const SkipList&);
};Node
Node是SkipList的元素类型,leveldb每插入一个记录对应SkipList的一个Node对象。那我们看看Node的实现:
// 代码源自leveldb/db/skiplist.h
template<typename Key, class Comparator>
struct SkipList<Key,Comparator>::Node {
// 构造函数只有Key类型,这个类型是const char*(定义在MemTable中),其实包含了key和value,只存储指针,内存谁管理?
// 肯定是Arena啊,MemTable通过Arena申请内存存储key和value,在把指针交给SkipList
explicit Node(const Key& k) : key(k) { }
// 一个Node负责一条记录,这个记录就是通过key指向
Key const key;
// 采用内存屏障的方式获取下一个Node,其中n为高度
Node* Next(int n) {
assert(n >= 0);
// next_是一个原子指针(参看《深入浅出levevldb之基础知识》)的数组,这个数组长度就是跳跃表的最大高度
return reinterpret_cast<Node*>(next_[n].Acquire_Load());
}
// 采用内存屏障的方式设置节点高度为n的下一个Node
void SetNext(int n, Node* x) {
assert(n >= 0);
next_[n].Release_Store(x);
}
// 无内存屏障的方式获取下一个Node,其中n为高度
Node* NoBarrier_Next(int n) {
assert(n >= 0);
return reinterpret_cast<Node*>(next_[n].NoBarrier_Load());
}
// 无内存屏障的方式设置节点高度为n的下一个Node
void NoBarrier_SetNext(int n, Node* x) {
assert(n >= 0);
next_[n].NoBarrier_Store(x);
}
// 定义成员变量
private:
// 很多人看到这里懵逼了把?怎么只有一个元素的数组,上面的访问可都是按照最高高度访问的,这个是一个非常有意思的地方了
// 在C++中,new一个对象其实就是malloc(sizeof(type))大小的内存,然后再执行构造函数的过程,delete先执行析构函数再free内存
// 有没有发现这是一个结构体?next_[1]正好在结构体的尾部,那么申请内存的时候如果多申请一些内存
// 那么通过索引的方式&next_[n]的地址就是多出来的那部分空间,所以可知Node是不是通过普通的new出来的
port::AtomicPointer next_[1];
};既然上面代码注释中提到了Node的创建不是一个普通的new,在SkipList中提供了专门的构造函数,那我们就来看看是怎么实现的:
// 代码源自leveldb/db/skiplist.h
// 看到没有,构造Node需要传入最大高度,这样申请的内存大小就会略有不同
template<typename Key, class Comparator>
typename SkipList<Key,Comparator>::Node* SkipList<Key,Comparator>::NewNode(const Key& key, int height) {
// 首先内存申请不是malloc,而是通过arena申请的,每个Node的大小很小,非常适合arena
// sizeof(port::AtomicPointer) * (height - 1)就是为了扩展指针数组用的
char* mem = arena_->AllocateAligned(sizeof(Node) + sizeof(port::AtomicPointer) * (height - 1));
// 调用构造函数
return new (mem) Node(key);
}看过代码的人可能第一时间估计会有疑问,为什么只有构造Node的函数却没有析构Node的函数,主要原因如下:
- SkipList只有添加没有删除操作,这个我们在前面提到过,自然在过程中没有释放Node的过程;
- 即便SkipList整体释放掉,只需要把arena释放掉就可以了,因为Node内部本身没有内存申请操作,所以也就没必要执行析构函数了;
Iterator
跳跃表的迭代器通过跳跃表的高度为0的链表形成了一个单项链表,只要获取头结点就可以正向的遍历所有的节点,但如果要反向遍历或者定位到某一个节点,就需要依赖跳跃表的查找能力了。
// 代码源自leveldb/db/skiplist.h
class Iterator {
private:
const SkipList* list_; // 指向跳跃表
Node* node_; // 迭代器当前的指向的节点
public:
// 构造函数,传入跳跃表指针,至少
explicit Iterator(const SkipList* list) {
list_ = list;
node_ = NULL;
}
// 判断当前迭代器是否有效的借口
bool Valid() const {
// 唯一能判断的只有node_指针了,迭代器每次操作都会更新node_指针
return node_ != NULL;
}
// 返回迭代器当前指向的节点的键,切记这个键不是用户指定的键,而是把key和value编码到一个内存块的值
const Key& key() const const {
// 从这里来看,需要使用者再使用前必须通过Valid()判断一下,否则就要接受崩溃的后果了
assert(Valid());
return node_->key;
}
// 指向下一个节点,同样的使用者要保证Valid()返回true
void Next() {
assert(Valid());
node_ = node_->Next(0); // 跳跃表的第0层所有节点的距离是1,所以通过第0层找下一个节点
}
// 指向前一个节点,使用者要保证Valid()返回true
void Prev() {
assert(Valid());
node_ = list_->FindLessThan(node_->key);
if (node_ == list_->head_) {
node_ = NULL;
}
}
// 根据key定位到指定的节点
void Seek(const Key& target) {
// 这个就要通过SkipList实现了,具体的实现前面介绍SkipList我们介绍了
node_ = list_->FindGreaterOrEqual(target, NULL);
}
// 定位到第一个节点,直接访问跳跃表的表头的下一个节点就是第一个节点
void SeekToFirst() {
node_ = list_->head_->Next(0);
}
// 定位到最后一个节点
void SeekToLast() {
// 通过SkipList找到最后一个节点
node_ = list_->FindLast();
// 如果返回的是表头的指针,那就说明链表中没有数据
if (node_ == list_->head_) {
node_ = NULL;
}
}
};从代码上不难看出,跳跃表遍历器的反向遍历(从大到小)效率非常低,远低于正向遍历(从小到大)。
MemTable
了解了Arena、Skiplist、KeyComparator后,再来看MemTable的实现就会更容易理解。
MemTableIterator
前面我们了解了SkipList的迭代器,MemTableIterator主要功能还是依靠SkipList::Iterator实现,但是有两个接口与SkipList::Iterator不同,就是key()和value()。对于MemTable中存储的key是InternalKey,value是用户指定的值,而SkipList只有key没有value,而且这个key是InternalKey和用户指定value编码后的值。
// 代码源自leveldb/db/memtable.cc
class MemTableIterator: public Iterator {
public:
// 需要注意的是MemTable::Table就是SkipList<const char*, KeyComparator>,从定义书写会方便很多
// MemTableIterator构造函数需要跳跃表的指针,毕竟遍历MemTable等同于遍历SkipList
explicit MemTableIterator(MemTable::Table* table) : iter_(table) { }
// 下面的接口就是用SkipList::Iterator实现的,没啥好多说的
virtual bool Valid() const { return iter_.Valid(); }
virtual void Seek(const Slice& k) { iter_.Seek(EncodeKey(&tmp_, k)); }
virtual void SeekToFirst() { iter_.SeekToFirst(); }
virtual void SeekToLast() { iter_.SeekToLast(); }
virtual void Next() { iter_.Next(); }
virtual void Prev() { iter_.Prev(); }
// 获取值,GetLengthPrefixedSlice()这个函数在KeyComparator章节介绍过,这里就不多说了
virtual Slice key() const { return GetLengthPrefixedSlice(iter_.key()); }
// 获取值
virtual Slice value() const {
// 在内存中跳过键的部分后面就是值
Slice key_slice = GetLengthPrefixedSlice(iter_.key());
return GetLengthPrefixedSlice(key_slice.data() + key_slice.size());
}
// 这个迭代器永远返回争取是怎么个意思?估计这个接口没用
virtual Status status() const { return Status::OK(); }
private:
MemTable::Table::Iterator iter_; // 功能需要SkipList::Iterator,自然需要相应的成员变量
std::string tmp_; // 由于SkipList的键是const char*,所以需要一个临时缓存做类型转换
// 禁止拷贝构造和赋值操作
MemTableIterator(const MemTableIterator&);
void operator=(const MemTableIterator&);
};Add
// leveldb/db/memtable.cc
// 向MemTable添加记录
void MemTable::Add(SequenceNumber s, ValueType type, const Slice& key, const Slice& value) {
// 我们前面提到过在SlipList存储的内容是把用户的键和值进行编码后的值,下面就是具体实现编码的部分
size_t key_size = key.size();
size_t val_size = value.size();
// InternalKey的长度是用户指定键+(顺序ID<<8|值类型),所以长度是用户指定键的长度+8
size_t internal_key_size = key_size + 8;
// 编码后的数据[InernalKey长度(Varint32)][InternalKey][value长度(Varint32)][value]
// 所以整体编码后需要的内存长度就下面的算法
const size_t encoded_len = VarintLength(internal_key_size) + internal_key_size + VarintLength(val_size) + val_size;
// 内存是从arena申请的
char* buf = arena_.Allocate(encoded_len);
// 先存放InternalKey的长度,编码成Varint32
char* p = EncodeVarint32(buf, internal_key_size);
// 接着存放内部键
memcpy(p, key.data(), key_size);
p += key_size;
EncodeFixed64(p, (s << 8) | type);
p += 8;
// 继续存放至长度,编码成Varint32
p = EncodeVarint32(p, val_size);
// 最后存放值
memcpy(p, value.data(), val_size);
assert((p + val_size) - buf == encoded_len);
// 插入跳跃表
table_.Insert(buf);
}Get
// leveldb/db/memtable.cc
// 从MemTable获取对象,此时的键是LookupKey类型
bool MemTable::Get(const LookupKey& key, std::string* value, Status* s) {
// 获取MemTable的键
Slice memkey = key.memtable_key();
// 构造MemTable的迭代器
Table::Iterator iter(&table_);
// 定位到键的位置,那么问题来了,我们知道存储在MemTabled的键是InternalKey,而InternalKey里面包含顺序号
// 在前面代码中我们知道,InternalKey的比较顺序号是参与比较的,那么获取对象的时候如何知道对象的顺序号的呢?
// 其实LookupKey里面的保存的顺序号是“顺序号最大值”,而MemTable迭代器Seek定位的是第一个比指定件大或者等于的对象
// InternalKey的比较顺序号越大越靠前,所以需要找的对象肯定会排在迭代器指的位置,所以需要接下来就要校验用户键
iter.Seek(memkey.data());
if (iter.Valid()) {
// 获取对象键
const char* entry = iter.key();
// 通过Varint32解码Internal键的长度
uint32_t key_length;
const char* key_ptr = GetVarint32Ptr(entry, entry+5, &key_length);
// 接下来就用用户提供的键比较器(BytewiseComparator)比较用户键,因为SkipList的Seek不是准确定位
// 毕竟他也没法准确定位,因为他不知道顺序号,所以要比较一下用户键是否相同
if (comparator_.comparator.user_comparator()->Compare(Slice(key_ptr, key_length - 8), key.user_key()) == 0) {
// 把顺序号+值类型取出来
const uint64_t tag = DecodeFixed64(key_ptr + key_length - 8);
// 即便用户键相同,很有可能值类型是删除,也就是说这个对象已经被删除了
switch (static_cast<ValueType>(tag & 0xff)) {
// 如果是有效的值,那么直接提取用户值
case kTypeValue: {
Slice v = GetLengthPrefixedSlice(key_ptr + key_length);
value->assign(v.data(), v.size());
return true;
}
// 如果是删除的对象,那么返回的就是没有找到的状态
case kTypeDeletion: {
*s = Status::NotFound(Slice());
return true;
}
}
}
}
return false;
}