目录
前言
个人认为,高并发是一个程序猿最基本的要解决的问题,如何让程序在高并发下良好运行是考验一个程序猿功力深厚与否的标尺。而锁往往是解决高并发,线程同步的利器,博主根据自己的理解,参考了网上的许多面经、和文章加上自己的理解写下了这篇博客。
1. 锁类型
- 乐观锁/悲观锁:悲观锁认为对同一个数据的并发操作,其他线程一定会修改数据。因此对于同一个数据的并发操作,悲观锁采取加锁的形式。悲观的认为,不加锁的并发操作一定会出问题。而乐观锁对同一数据进行并发操作,总是认为其他线程不会对数据进行修改。在更新数据的时候,会采用尝试更新,不断重新的方式更新数据。乐观的认为,不加锁的并发操作是没有事情的。
- 可重入锁:在执行对象中所有同步方法不用再次获得锁
- 可中断锁:在等待获取锁过程中可中断
- 公平锁:按照获取锁等待的时间进行获取,等待时间长的可以优先获取
- 读写锁:对资源读取和写入的时候拆分为2部分处理,读的时候可以多线程一起读,写的时候必须同步地写。类似于数据库的X锁和S锁
- 偏向锁/轻量级锁/重量级锁
下面将从乐观锁和悲观锁说起:
2. 悲观锁VS乐观锁
-
悲观锁适合写操作多的场景,先加锁可以保证写操作时数据正确。
-
乐观锁适合读操作多的场景,不加锁的特点能够使其读操作的性能大幅提升。
2.1 悲观锁代表Synchronize关键字
由于Synchronize是关键字,我们没办法通过鼠标点点点就知道其内部结构,只能通过反编译的手段来看看synchronize是怎么实现的。
Synchronize关键字具体的请看这位前辈写的,这里我就简写了
一个简单的demo
public class SynchronizedThis {
public void method() {
synchronized(this) {}
}
}
//使用命令:javap -v 进行反编译,得到如下结果
public void method();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter
4: aload_1
5: monitorexit
6: goto 14
9: astore_2
10: aload_1
11: monitorexit
12: aload_2
13: athrow
14: return
java对象头:
|--------------------------------------------------------------|
| Object Header (64 bits) |
|------------------------------------|-------------------------|
| Mark Word (32 bits) | Klass Word (32 bits) |
|------------------------------------|-------------------------|
其中的Mark Word包含hashcode、gc分代年龄等等,而monitor就存在Mark Word中。
2.1.1. Synchronize关键字实现方法
Synchronize关键字是通过monitorenter和monitorexit来实现,monitor可实现监视器的功能,调用monitorenter就是尝试获取这个对象,获取成功则+1,离开则-1,如果是线程重入,则继续+1,即synchronize是可重入的。既然是悲观锁,就证明用Synchronize修饰的方法或者属性,在多线程下只能被一个线程访问到。
2.2乐观锁代表CAS操作:
CAS是Compare and Swap(比较并交换) 的简写,CAS的思想很简单:三个参数,一个当前内存值V、一个内存旧值A还有一个是新值B,当且仅当A==V时,即认为其他线程没有对数据进行修改则将B(新值)设置为内存值,并返回true,否则什么都不做 JVM中的CAS操作正是利用了处理器提供的CMPXCHG指令实现的;CAS操作会引起ABA带来的问题,可以通过版本号来解决。
2.2.1. CAS带来的ABA问题:
抽象一个场景,小明有一百元,需要转给妈妈五十,来到银行ATM机,输入50,点击转账,由于不可避免因素,小明又重试了一次,而此时,小明的妈妈也给小明转了50,那么此时就有三个线程:
线程一:小明原有100,小明转账五十,新余额应有50
线程二:小明原有100,小明转账五十,新余额应有50//由于不可避免因素导致线程二阻塞,最后进行
线程三:预期小明应有50,妈妈转账五十,小明应有余额100
那么我们来分析一下,
首先线程一知道了银行卡原有一百,转账五十后发现没问题,确认
线程三预期和实际值一致,转账成功,此时小明应有100
线程三预期值、旧值一致,直接将余额赋值为50,此时小明痛哭
加了版本号呢,就是:1A,2B,3A,这时ABA问题得到解决。
2.2.2. CAS带来的循环时间长开销大问题
自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令,那么效率会有一定的提升。pause指令有两个作用:第一,它可以延迟流水线执行指令,使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零;第二,它可以避免在退出循环的时候因内存顺序冲突而引起CPU流水线被清空,从而提高CPU的执行效率。
2.2.3. CAS带来的只能保证一个共享变量的原子操作问题。
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。还有一个巧取的办法,就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij=2a,然后用CAS来操作ij。从JDK1.5开始提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作。
2.2.4. CAS是如何保证原子操作的
JVM的CAS操作是利用了处理器提供的CMPXCHG指令实现的。CAS通过调用JNI(Java native Interface本地C方法)的代码实现的。程序会根据当前处理器的类型来决定是否为COMPXCHG指令添加lock前缀:多CPU的情况下加lock前缀
cmpxchg是汇编指令
作用:比较并交换操作数.
如:CMPXCHG r/m,r 将累加器AL/AX/EAX/RAX中的值与首操作数(目的操作数)比较,如果相等,第2操作数(源操作数)的值装载到首操作数,zf置1。如果不等, 首操作数的值装载到AL/AX/EAX/RAX并将zf清0
该指令只能用于486及其后继机型。第2操作数(源操作数)只能用8位、16位或32位寄存器。第1操作数(目地操作数)则可用寄存器或任一种存储器寻址方式。
2.2.5. 引申出来的问题: AtomticXXX实现的原理:
核心代码:即CAS操作,AtomticXXX所有的类都是基于CAS(比较并交换实现的),即使用了Unsafe.compareAndSwapInt进行更新,其内部主要是维护了一个用volatile修饰的·int类型的value
private volatile int value;
//比较并交换
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
我的理解:CAS能使其保证原子性,所以得到的AtmoticInteger也是一个原子数,而volatile关键字保证其可内存可见性。
2.3 引申出来的:volatile关键字
变量修饰符,可以使用内存屏障保证变量的内存可见性以及禁止指令重排序,但是volatile不能保证原子性。
2.3.1 内存可见性的原因
随着科技发展,为了提高处理器的执行速度,在处理器和内存之间增加了多级缓存来提升。但是由于引入了多级缓存,就存在缓存数据不一致问题。但是,对于volatile变量,当对volatile变量进行写操作的时候,JVM会向处理器发送一条lock前缀的指令,将这个缓存中的变量回写到系统主存中。
2.3.2 禁止指令重排序的原因
先看一段代码:
public class Singleton {
private volatile static Singleton singleton;
private Singleton() {}
public static Singleton getInstance() {
if (singleton == null) { // 1
sychronized(Singleton.class) {
if (singleton == null) {
singleton = new Singleton(); // 2
}
}
}
return singleton;
}
}
上述代码是一个典型的单例模式中的懒汉模式, singleton = new Singleton(); 可分三步:
- 给 singleton 分配内存
- 调用 Singleton 的构造函数来初始化成员变量
- 将 singleton 对象指向分配的内存空间(执行完这步 singleton 就为非 null 了)
假设虚拟机存在指令重排序优化,2、3调换位置。如果A线程率先进入同步代码块并先执行了3而没有执行2,此时因为singleton已经非null。这时候线程B到了1处,判断singleton非null并将其返回使用,因为此时Singleton实际上还未初始化,(并未有实际内容,我的理解),自然就会出错。sychronized可以解决内存可见性,但是不能解决重排序问题。
2.3.3 volatile关键字不能保证原子操作的原因
volatile的Integer自增i++,分成三步:
- 读取volatile变量到local
- 增加变量的值
- 把local的值写回
这三步的机器指令为:
mov 0xc(%r10),%r8d ; Load
inc %r8d ; Increment
mov %r8d,0xc(%r10) ; Store
lock addl $0x0,(%rsp) ; StoreLoad Barrier //内存屏障以确保一些特定的操作顺序和影响一些数据的可见性
从Load到store到内存屏障,一共4步,其中最后一步jvm让这个最新的变量的值在所有线程可见,也就是最后一步让所有的CPU内核都获得了最新的值,但**中间的几步(从Load到Store)**是不安全的,中间如果其他的CPU修改了值将会丢失。
2.3.4. 关于volatile关键字的讨论:
在群里我忽然看到了这样一个点,volatile是可以解决内存可见性的问题,那么这个可见性到底是针对的CPU Cache而言即CPU的缓存导致的内存不可见还是基于JMM(java内存模型)而言呢?
从操作系统的角度来说,CPU 的执行效率会比内存的取指效率快的多,所以 CPU 会在内部设立缓存机制,就是为了弥补内存工作慢的原因,所以一般访问的时候会先从 CPU 自己的缓存访问,而 volatile 关键字是刷新缓存保证可见性,我认为应该是会让 CPU 强制从内存取出值,应该保证的是 JMM 内存可见
3. 可重入锁、 可中断锁、公平锁、读写锁
我决定把这几个放到一起,因为有个叫ReentrantLock的锁可以很好的去包容上述特性。首先源码:
public class ReentrantLock implements Lock, java.io.Serializable
可以看到看到ReentrantLock实现了lock,而说lock呢,又不得不说一个东西:AQS
3.1 谈谈对AQS的理解:
图解如下:
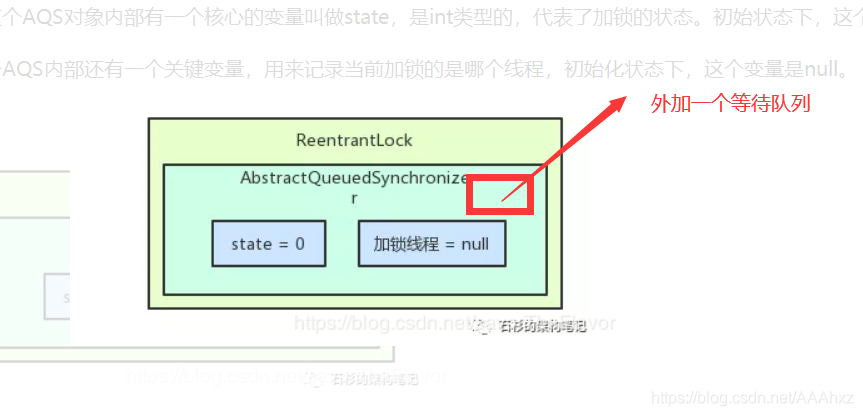
- AQS全称AbstractQueuedSynchronizer,是java并发包中的核心类,诸如ReentrantLock,CountDownLatch等工具内部都使用了AQS去维护锁的获取与释放
- 内部维护了一个state,state为0时代表内有线程持有锁,大于0时(可重入,每次获取锁都会加一)表示线程持有锁。通过tryacquire(int arg)获取独占锁。
- head和tail表示当前持有锁的线程和未持有锁的线程,一个线程尝试获取锁,如果失败则加入等待队列末尾
- AQS内部通过**一个CLH阻塞队列(一个FIFO线程等待队列)**去维持线程的状态,并且使用LockSupport工具去实现线程的阻塞和和唤醒,同时里面大量运用了无锁的CAS算法去实现锁的获取和释放,这个CLH阻塞序列是一个Node的双向链表,也就是类似于JDK1.8的HashMap。
- AQS 定义了两种资源共享的方式 Exclusive(独占,一时间只有一个线程能访问该资源)、Share (共享,一时间可以有多个线程访问资源).
- AQS源码中帮我们做好了线程排队、等待、唤醒等操作我们只需要重写决定如何获取和释放的锁,这是典型的模板方法。
回过头来,我试着用比较Synchronize和lock的区别的方法:
- synchronize自动释放锁,而Lock必须手动释放,并且代码中出现异常会导致unlock代码不执行,所以Lock一般在Finally中释放,而synchronize释放锁是由JVM自动执行的。即一个表现为API层面的互斥锁,一个表现为原生语法层面的互斥锁。
- Lock有共享锁的概念,所以可以设置读写锁提高效率,synchronize不能。(两者都可重入)
- Lock可以让线程在获取锁的过程中响应中断,而synchronize不会,线程会一直等待下去。lock.lockInterruptibly()方法会优先响应中断,而不是像lock一样优先去获取锁。
- Lock锁的是代码块,synchronize还能锁方法和类。
- Lock可以知道线程有没有拿到锁,而synchronize不能。
- 在竞争很激烈的情况下,lock性能明显优于synchronize关键字
说完了这些,再回到上面的概念:
3.2 可重入锁:
广义上的可重入锁指的是可重复可递归调用的锁,在外层使用锁之后,在内层仍然可以使用,并且不发生死锁(前提得是同一个对象或者class),这样的锁就叫做可重入锁。ReentrantLock和synchronized都是可重入锁
那么不可重入锁就反之了
3.3 可中断锁:
顾名思义,就是可以相应中断的锁。synchronized就不是可中断锁,而Lock是可中断锁。
如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长或其他原因,线程B中断等待,去做其他事情,那么就称该锁是可以中断的。
3.4 公平锁:
公平锁,就是公平的锁。。。。
即根据等待获取锁时间而优先获得对象的锁的一种锁
ReentrantLock可以设置为公平锁,默认情况下不是公平锁的:

3.5 读写锁
读写锁,类似于数据库的S(共享)锁,即只允许一个线程去写,多个线程去读,这样可以提高并发度
ReentrantReadWriterLock就是一个可以同时读又可以同时写的一种锁
public class ReentrantReadWriteLock implements ReadWriteLock, java.io.Serializable {
private static final long serialVersionUID = -6992448646407690164L;
/** Inner class providing readlock */
private final ReentrantReadWriteLock.ReadLock readerLock;
/** Inner class providing writelock */
private final ReentrantReadWriteLock.WriteLock writerLock;
/** Performs all synchronization mechanics */
final Sync sync;
4. 偏向锁/轻量级锁/重量级锁
4.1 注意
首先声明一下,这三个锁并不是Java语言中的锁,而是针对Synchronize关键字进行优化的三种方式,因为Synchronize关键字过于笨重,所以jdk对关键字进行了优化。
在此引申到对象头中MarkWord的内容:

其中:
lock:2位的锁状态标记位,由于希望用尽可能少的二进制位表示尽可能多的信息,所以设置了lock标记。该标记的值不同,整个mark word表示的含义不同。
| biased_lock | lock | 状态 |
|---|---|---|
| 0 | 01 | 无锁 |
| 1 | 01 | 偏向锁 |
| 0 | 00 | 轻量级锁 |
| 0 | 10 | 重量级锁 |
| 0 | 11 | GC标记 |
4.2 锁的状态:
- 无锁状态
- 偏向锁状态
- 轻量级锁状态
- 重量级锁状态即Synchronize
偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会自动升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。
5. 补充
5.1 自旋锁
上面提及了自旋锁的概念,自旋锁顾名思义自己旋转获取锁,这样的好处是避免了上下文切换,但是由于一直自旋,会一直占用CPU,使用不当还会使CPU飚。而自旋锁本身无法保证公平性,同时也无法保证可重入性。基于自旋锁,可以实现具备公平性和可重入性质的锁。
5.2 分段锁
这个其实就有点牵强了,这个应用到的地方我知道的(恕我才疏学浅)就只有ConcurrentHashMap,JDK1.7的ConcurrentHashMap是基于分段锁,jdk1.7中采用Segment + HashEntry的方式进行实现,结构如下:

所谓的分段,顾名思义,将一个个Entry分成数段,每一段进行加锁,这样既保证了较为理想的并发度,而且保证了线程安全
