原文地址:http://blog.csdn.net/hjimce/article/details/50866313
转载自:https://blog.csdn.net/u010402786/article/details/51233854(因为感觉这个作者的排版比较好看 )
)
关于归一化部分的理解参考资料:神经网络之家 www.nnetinfo.com
http://www.nnetinfo.com/nninfo/showText.jsp?id=37
本文是在总结以上三篇博文的基础上加上一些知乎上的优秀回答融合而成,如有不足之处,欢迎指正
| 一、背景意义 |
本篇博文主要讲解2015年深度学习领域,非常值得学习的一篇文献:《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》,这个算法目前已经被大量的应用,最新的文献算法很多都会引用这个算法,进行网络训练,可见其强大之处非同一般啊。
近年来深度学习捷报连连、声名鹊起,随机梯度下架成了训练深度网络的主流方法。尽管随机梯度下降法对于训练深度网络简单高效,但是它有个毛病,就是需要我们人为的去选择参数,比如学习率、参数初始化、权重衰减系数、Drop out比例等。这些参数的选择对训练结果至关重要,以至于我们很多时间都浪费在这些的调参上。那么学完这篇文献之后,你可以不需要那么刻意的慢慢调整参数。BN算法(Batch Normalization)其强大之处如下:
(1)你可以选择比较大的初始学习率,让你的训练速度飙涨。以前还需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性;
(2)你再也不用去理会过拟合中drop out、L2正则项参数的选择问题,采用BN算法后,你可以移除这两项了参数,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性;
(3)再也不需要使用使用局部响应归一化层了(局部响应归一化是Alexnet网络用到的方法,搞视觉的估计比较熟悉),因为BN本身就是一个归一化网络层;
(4)可以把训练数据彻底打乱(防止每批训练的时候,某一个样本都经常被挑选到,文献说这个可以提高1%的精度,这句话我也是百思不得其解啊)。
开始讲解算法前,先来思考一个问题:我们知道在神经网络训练开始前,都要对输入数据做一个归一化处理,那么具体为什么需要归一化呢?归一化后有什么好处呢?原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
关于归一化的作用如下:
1、数值问题
无容置疑,归一化的确可以避免一些不必要的数值问题。输入变量的数量级未致于会引起数值问题吧,但其实要引起也并不是那么困难。因为tansig的非线性区间大约在[-1.7,1.7]。意味着要使神经元有效,tansig( w1*x1 + w2*x2 +b) 里的 w1*x1 +w2*x2 +b 数量级应该在 1 (1.7所在的数量级)左右。这时输入较大,就意味着权值必须较小,一个较大,一个较小,两者相乘,就引起数值问题了。
假如你的输入是421,你也许认为,这并不是一个太大的数,但因为有效权值大概会在1/421左右,例如0.00243,那么,在matlab里输入 421*0.00243 == 0.421*2.43

可以看到两者不相等了,说明已经引起数值问题了。
2、求解需要
我们建立了神经网络模型后,只要找到的解足够好,我们的网络就能够正确的预测了。在训练前我们将数据归一化,说明数据归是为了更方便的求解
那么,究竟给求解带来了什么方便呢?
这个问题不能一概而论,不同的算法,在归一化中得到的好处各不相同。假若有一个很牛B的求解算法,那完全用不着归一化,不过目前大部算法,都比较需要归一化,特别是常用的梯度下降法(或梯度下降的衍生方法),归一化和不归一化,对梯度下降法的影响非常大。不同的算法,对归一化的依赖程序不同,例如列文伯格-马跨特算法(matlab工具箱的trainlm法)对归一化的依赖就没有梯度下降法(matlab里的traingd)那么强烈。
既然不同的算法对归一化有不同的理由,篇幅有限,本文就仅以梯度下降法举例。
重温一下梯度法,梯度法一般初始化一个初始解,然后求梯度,再用新解=旧解-梯度*学习率 的方式来迭代更新解。直到满足终止迭代条件,退出循环。
先看归一化对初始化的好处:
(1)初始化
过初始化的同学会发现,输入数据的范围会影响我们初始化的效果。例如,某个神经元的值为tansig(w1*x1+w2*x2+b),由于tansig函数只有在[-1.7,1.7]的范围才有较好的非线性,所以w1*x1+w2*x2+b的取值范围就要与 [-1.7,1.7]有交集(实际上需要更细腻的条件),这个神经元才能利用到非线性部分。
我们希望初始化的时候,就把每个神经元初始化成有效的状态,所以,需要知道w1*x1+w2*x2+b的取值范围,也就需要知道输入输出数据的范围。
输入数据的范围对初始化的影响是无法避免的,一般讨论初始化方法时,我们都假设它的范围就是[0,1]或者[-1,1],这样讨论起来会方便很多。就这样,若果数据已经归一化的话,能给初始化模块带来更简便,清晰的处理思路。
注:matlab工具箱在初始化权值阈值的时候,会考虑数据的范围,所以,即使你的数据没归一化,也不会影响matlab工具箱的初始化
(2)梯度
以输入-隐层-输出这样的三层BP为例,我们知道对于输入-隐层权值的梯度有2e*w*(1-a^2)*x的形式(e是誤差,w是隐层到输出层的权重,a是隐层神经元的值,x是输入),若果输出层的数量级很大,会引起e的数量级很大,同理,w为了将隐层(数量级为1)映身到输出层,w也会很大,再加上x也很大的话,从梯度公式可以看出,三者相乘,梯度就非常大了。这时会给梯度的更新带来数值问题。
(3)学习率
由(2)中,知道梯度非常大,学习率就必须非常小,因此,学习率(学习率初始值)的选择需要参考输入的范围,不如直接将数据归一化,这样学习率就不必再根据数据范围作调整。
隐层到输出层的权值梯度可以写成 2e*a,而输入层到隐层的权值梯度为 2e *w*(1-a^2)*x ,受 x 和 w 的影响,各个梯度的数量级不相同,因此,它们需要的学习率数量级也就不相同。对w1适合的学习率,可能相对于w2来说会太小,若果使用适合w1的学习率,会导致在w2方向上步进非常慢,会消耗非常多的时间,而使用适合w2的学习率,对w1来说又太大,搜索不到适合w1的解。
如果使用固定学习率,而数据没归一化,则后果可想而知。
不过,若果像matlab工具箱一样,使用自适应学习率,学习率的问题会稍稍得到一些缓和。
(4)搜索轨迹
前面已说过,输入范围不同,对应的 w 的有效范围就不同。假设 w1 的范围在 [-10,10],而w2的范围在[-100,100],梯度每次都前进1单位,那么在w1方向上每次相当于前进了 1/20,而在w2上只相当于 1/200!某种意义上来说,在w2上前进的步长更小一些,而w1在搜索过程中会比w2“走”得更快。这样会导致,在搜索过程中更偏向于w1的方向。

抛开哪种路线更有效于找到最佳解的问题不谈,两点之间直线距离最短,这种直角路线明显会更耗时间,所以不归一化,时间会明显增加。
从上面的分析总结,除去数值问题的影响,最主要的影响就是,每一维的偏导数计算出来数量级会不一致。下面我们来个试验。
假设我们有两个输入变量,x1范围是[-1,1],但x2是[-100,100],输出范围是[-1,1]。x2在输入数据上没有做归一化,怎么修改训练过程,才能让训练结果如同数据归一化了一样呢。
通过上面的讨论,我们知道x2增大了,会使w2的梯度也很大,因此我们在计算w2梯度时,需要把它的梯度除以100.才能得到它的梯度数量级与w1的一致。然后在更新w步长的时候,w1的有效取值范围(1/1)是w2的有效取值范围(1/100)的100倍,因此w2走的时候,应该以1/100的步去走。所以w2的学习率也需要除以100。
这样,若果不考虑数值问题,会和数据作了归一化的结果是一样的。这里就不展示实验的代码了,因为需要涉及整个BP代码。有兴趣研究的同学在自己的编写的代码上动下刀。
这是一个案例分析,说明不考虑数值问题的话,只是影响了这两个地方。假设,x2的输入范围是[100,300],那肯定不是除以100就可以了,需要更复杂一些的变换,这里不再深入纠结。
3、总结
下面是网友关于为什么要归一化的一些回答(欢迎补充):
1.避免数值问题。
2.使网络快速的收敛。
3.样本数据的评价标准不一样,需要对其量纲化,统一评价标准
4.bp中常采用sigmoid函数作为转移函数,归一化能够防止净输入绝对值过大引起的神经元输出饱和现象 。
5.保证输出数据中数值小的不被吞食 。
对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。
我们知道网络一旦train起来,那么参数就要发生更新,除了输入层的数据外(因为输入层数据,我们已经人为的为每个样本归一化),后面网络每一层的输入数据分布是一直在发生变化的,因为在训练的时候,前面层训练参数的更新将导致后面层输入数据分布的变化。以网络第二层为例:网络的第二层输入,是由第一层的参数和input计算得到的,而第一层的参数在整个训练过程中一直在变化,因此必然会引起后面每一层输入数据分布的改变。我们把网络中间层在训练过程中,数据分布的改变称之为:“Internal Covariate Shift”。Paper所提出的算法,就是要解决在训练过程中,中间层数据分布发生改变的情况,于是就有了Batch Normalization,这个牛逼算法的诞生。
| 二、初识BN(Batch Normalization) |
| 1、BN概述 |
就像激活函数层、卷积层、全连接层、池化层一样,BN(Batch Normalization)也属于网络的一层。在前面我们提到网络除了输出层外,其它层因为低层网络在训练的时候更新了参数,而引起后面层输入数据分布的变化。这个时候我们可能就会想,如果在每一层输入的时候,再加个预处理操作那该有多好啊,比如网络第三层输入数据X3(X3表示网络第三层的输入数据)把它归一化至:均值0、方差为1,然后再输入第三层计算,这样我们就可以解决前面所提到的“Internal Covariate Shift”的问题了。
而事实上,paper的算法本质原理就是这样:在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理,然后再进入网络的下一层。不过文献归一化层,可不像我们想象的那么简单,它是一个可学习、有参数的网络层。既然说到数据预处理,下面就先来复习一下最强的预处理方法:白化。
| 2、预处理操作选择 |
说到神经网络输入数据预处理,最好的算法莫过于白化预处理。然而白化计算量太大了,很不划算,还有就是白化不是处处可微的,所以在深度学习中,其实很少用到白化。经过白化预处理后,数据满足条件:a、特征之间的相关性降低,这个就相当于pca;b、数据均值、标准差归一化,也就是使得每一维特征均值为0,标准差为1。如果数据特征维数比较大,要进行PCA,也就是实现白化的第1个要求,是需要计算特征向量,计算量非常大,于是为了简化计算,作者忽略了第1个要求,仅仅使用了下面的公式进行预处理,也就是近似白化预处理:
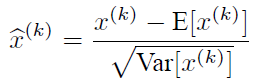
公式简单粗糙,但是依旧很牛逼。因此后面我们也将用这个公式,对某一个层网络的输入数据做一个归一化处理。需要注意的是,我们训练过程中采用batch 随机梯度下降,上面的E(xk)指的是每一批训练数据神经元xk的平均值;然后分母就是每一批数据神经元xk激活度的一个标准差了。
| 三、BN算法实现 |
| 1、BN算法概述 |
经过前面简单介绍,这个时候可能我们会想当然的以为:好像很简单的样子,不就是在网络中间层数据做一个归一化处理嘛,这么简单的想法,为什么之前没人用呢?然而其实实现起来并不是那么简单的。其实如果是仅仅使用上面的归一化公式,对网络某一层A的输出数据做归一化,然后送入网络下一层B,这样是会影响到本层网络A所学习到的特征的。打个比方,比如我网络中间某一层学习到特征数据本身就分布在S型激活函数的两侧,你强制把它给我归一化处理、标准差也限制在了1,把数据变换成分布于s函数的中间部分,这样就相当于我这一层网络所学习到的特征分布被你搞坏了,这可怎么办?于是文献使出了一招惊天地泣鬼神的招式:变换重构,引入了可学习参数γ、β,这就是算法关键之处:
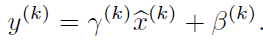
每一个神经元xk都会有一对这样的参数γ、β。这样其实当:
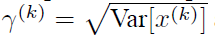
是可以恢复出原始的某一层所学到的特征的。因此我们引入了这个可学习重构参数γ、β,让我们的网络可以学习恢复出原始网络所要学习的特征分布。最后Batch Normalization网络层的前向传导过程公式就是:
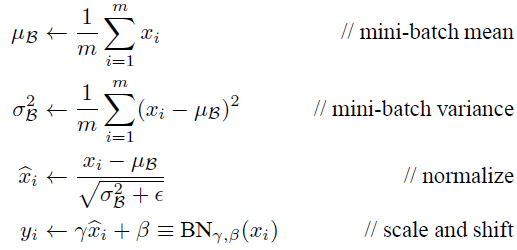
上面的公式中m指的是mini-batch size。
下面是我在学习过程中就batch_normalization做了normalization后为什么要变回来?这个问题在知乎上找到的答案
链接:https://www.zhihu.com/question/55917730/answer/154269264
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这就是Batch Normalization强大的地方,如果只做normalize在某些情况下会出现问题,比如对象是Sigmoid函数的output,而且output是分布在Sigmoid函数的两侧,normalize会强制把output分布在Sigmoid函数的中间的非饱和区域,这样会导致这层网络所学习到的特征分布被normalize破坏。而上面算法的最后一步,scale and shift可以令零均值单位方差的分布(normalize之后的分布)通过调节gamma和beta变成任意更好的分布(对于喂给下一层网络来说)。因为这个gamma和beta是在训练过程中可以学习得到参数。
最极端的情况就是当gamma = sqrt(var(x)) 和 beta = mean(x)的时候,就是题主所说的“打回原形”了,这种原来的论文中,Sergey说的是至少能够使特征分布回到normalize之前的分布,并不是每一层学习到的gamma和beta都会抵消之前的normalize的操作。我的理解是完整的BN通过normalize和scale & shift两步的操作提供更高的flexibility,对于每层的output既可以是零均值单位方差的分布,也可以是分布于Sigmoid两端饱和区域的分布,或者其他任意的分布。
Reference:
链接:https://www.zhihu.com/question/55917730/answer/292893183
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
| 2、源码实现 |
m = K.mean(X, axis=-1, keepdims=True)#计算均值
std = K.std(X, axis=-1, keepdims=True)#计算标准差
X_normed = (X - m) / (std + self.epsilon)#归一化
out = self.gamma * X_normed + self.beta#重构变换 - 1
- 2
- 3
- 4
上面的x是一个二维矩阵,对于源码的实现就几行代码而已,轻轻松松。
| 3、实战使用 |
(1)可能学完了上面的算法,你只是知道它的一个训练过程,一个网络一旦训练完了,就没有了min-batch这个概念了。测试阶段我们一般只输入一个测试样本,看看结果而已。因此测试样本,前向传导的时候,上面的均值u、标准差σ 要哪里来?其实网络一旦训练完毕,参数都是固定的,这个时候即使是每批训练样本进入网络,那么BN层计算的均值u、和标准差都是固定不变的。我们可以采用这些数值来作为测试样本所需要的均值、标准差,于是最后测试阶段的u和σ 计算公式如下:
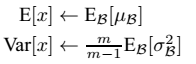
上面简单理解就是:对于均值来说直接计算所有batch u值的平均值;然后对于标准偏差采用每个batch σB的无偏估计。最后测试阶段,BN的使用公式就是:
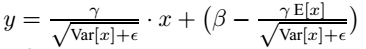

| 四、Batch Normalization在CNN中的使用 |
通过上面的学习,我们知道BN层是对于每个神经元做归一化处理,甚至只需要对某一个神经元进行归一化,而不是对一整层网络的神经元进行归一化。既然BN是对单个神经元的运算,那么在CNN中卷积层上要怎么搞?假如某一层卷积层有6个特征图,每个特征图的大小是100*100,这样就相当于这一层网络有6*100*100个神经元,如果采用BN,就会有6*100*100个参数γ、β,这样岂不是太恐怖了。因此卷积层上的BN使用,其实也是使用了类似权值共享的策略,把一整张特征图当做一个神经元进行处理。
卷积神经网络经过卷积后得到的是一系列的特征图,如果min-batch sizes为m,那么网络某一层输入数据可以表示为四维矩阵(m,f,p,q),m为min-batch sizes,f为特征图个数,p、q分别为特征图的宽高。在cnn中我们可以把每个特征图看成是一个特征处理(一个神经元),因此在使用Batch Normalization,mini-batch size 的大小就是:m*p*q,于是对于每个特征图都只有一对可学习参数:γ、β。说白了吧,这就是相当于求取所有样本所对应的一个特征图的所有神经元的平均值、方差,然后对这个特征图神经元做归一化。下面是来自于keras卷积层的BN实现一小段主要源码:
input_shape = self.input_shape
reduction_axes = list(range(len(input_shape)))
del reduction_axes[self.axis]
broadcast_shape = [1] * len(input_shape)
broadcast_shape[self.axis] = input_shape[self.axis]
if train:
m = K.mean(X, axis=reduction_axes)
brodcast_m = K.reshape(m, broadcast_shape)
std = K.mean(K.square(X - brodcast_m) + self.epsilon, axis=reduction_axes)
std = K.sqrt(std)
brodcast_std = K.reshape(std, broadcast_shape)
mean_update = self.momentum * self.running_mean + (1-self.momentum) * m
std_update = self.momentum * self.running_std + (1-self.momentum) * std
self.updates = [(self.running_mean, mean_update),
(self.running_std, std_update)]
X_normed = (X - brodcast_m) / (brodcast_std + self.epsilon)
else:
brodcast_m = K.reshape(self.running_mean, broadcast_shape)
brodcast_std = K.reshape(self.running_std, broadcast_shape)
X_normed = ((X - brodcast_m) /
(brodcast_std + self.epsilon))
out = K.reshape(self.gamma, broadcast_shape) * X_normed + K.reshape(self.beta, broadcast_shape) - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
个人总结:2015年个人最喜欢深度学习的一篇paper就是Batch Normalization这篇文献,采用这个方法网络的训练速度快到惊人啊,感觉训练速度是以前的十倍以上,再也不用担心自己这破电脑每次运行一下,训练一下都要跑个两三天的时间。另外这篇文献跟空间变换网络《Spatial Transformer Networks》的思想神似啊,都是一个变换网络层。
参考文献:
1、《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
2、《Spatial Transformer Networks》
3、https://github.com/fchollet/keras