小总结一下Inception v1——Inception v4的发展历程
1.Inception V1
通过设计一个系数网络结构,但是能够产生稠密的数据,既能增加神经网络的表现,又能保证计算资源的使用效率。
通过Split-Merge包含了1 * 1,3 * 3,5 * 5的卷积,3*3的池化,可以增加网络对多尺度的适应性,当然,增加了网络的宽度。
这里v1网络给人眼前一亮的是有一个Bottleneck layer,就是使用了NiN的1*1的卷积进行了特征降维,减少了维度,还能修正非线性激活relu,还提高了CNN的局部感知区域,降低了计算量。以上就是1 * 1卷积核的作用。
首次提出了取消全连接层,这样参数量就不会很大,取而代之的是全局平均池化。当然,这里最后好像还有一层全连接层,因为最后要softmax分类嘛。
还提出了辅助分类器的结构,为的是解决前几层梯度消失的问题。下面是Inception Architecture:

论文:https://arxiv.org/abs/1409.4842
2.Inception V2
这个版本其实是出现了Batch Normalization才定义的,是为了解决Internal Covaviate Shift问题(内部neuron数据分布发生变化)
白化:使每一层的输出都规范化到N(0,1),而且允许较高的学习率,可以取代部分dropout
首次提出了5 * 5卷积核可以被两个3 * 3的卷积核取代。
下面是详细的优势,借鉴:http://blog.csdn.net/happynear/article/details/44238541
论文中将Batch Normalization的作用说得突破天际,好似一下解决了所有问题,下面就来一一列举一下:
(1) 可以使用更高的学习率。如果每层的scale不一致,实际上每层需要的学习率是不一样的,同一层不同维度的scale往往也需要不同大小的学习率,通常需要使用最小的那个学习率才能保证损失函数有效下降,Batch Normalization将每层、每维的scale保持一致,那么我们就可以直接使用较高的学习率进行优化。
(2) 移除或使用较低的dropout。 dropout是常用的防止overfitting的方法,而导致overfit的位置往往在数据边界处,如果初始化权重就已经落在数据内部,overfit现象就可以得到一定的缓解。论文中最后的模型分别使用10%、5%和0%的dropout训练模型,与之前的40%-50%相比,可以大大提高训练速度。
(3) 降低L2权重衰减系数。 还是一样的问题,边界处的局部最优往往有几维的权重(斜率)较大,使用L2衰减可以缓解这一问题,现在用了Batch Normalization,就可以把这个值降低了,论文中降低为原来的5倍。
(4) 取消Local Response Normalization层。 由于使用了一种Normalization,再使用LRN就显得没那么必要了。而且LRN实际上也没那么work。
(5) 减少图像扭曲的使用。 由于现在训练epoch数降低,所以要对输入数据少做一些扭曲,让神经网络多看看真实的数据。
上面这个博主的文章中还写道了配对使用scale & shift。

3.Inception V3
V2有两3 * 3的卷积核代替了一个55的,但是有没有可能分解的更加彻底呢?有,
那就是N * N分解为1 * N和N * 1,不仅降低了参数的数量,还降低了计算量。
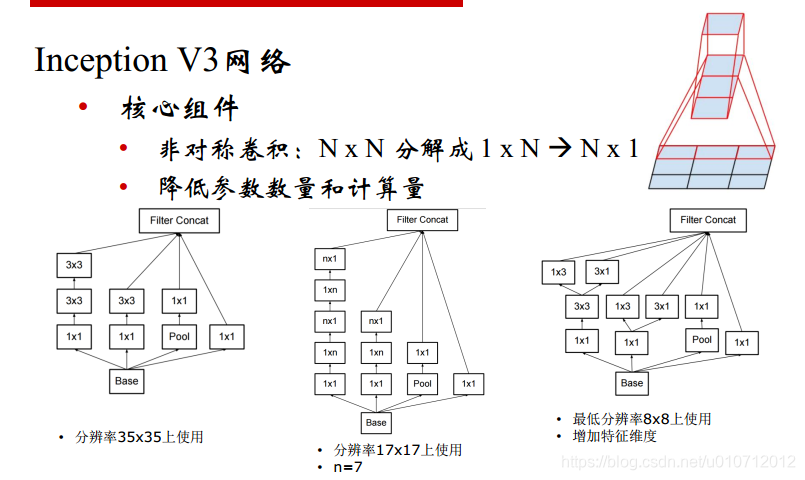
这么做工程味儿很浓。最重要的还是卷积的分解。

一共有三种网络结构,如下:好处多多。
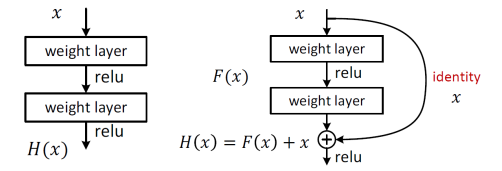
4.ResNet登场
在V1—>V3之后,ResNet残差网络出场了,下图左边的叫Plain net,映射他可以拟合出任意目标映射H(x),出来了一个Residual net,右下图拟合出F(x),H(x) = F(x)+x,其中F(x)残差映射,当H(x)最优映射接近identity时,很容易捕捉到小的扰动。

根据bootleneck优化残差映射网络。
可以优化的更好。

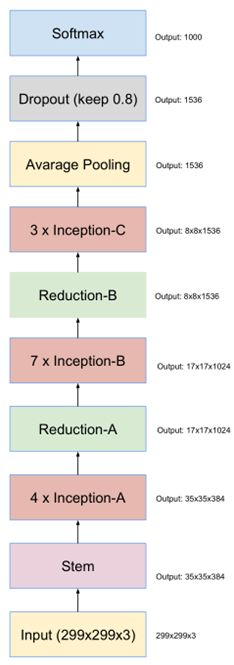
5.Inception V4
其实,做到现在,inception模块感觉已经做的差不多了,再做下去准确率应该也不会有大的改变。但是谷歌这帮人还是不放弃,非要把一个东西做到极致,改变不了inception模块,就改变其他的。
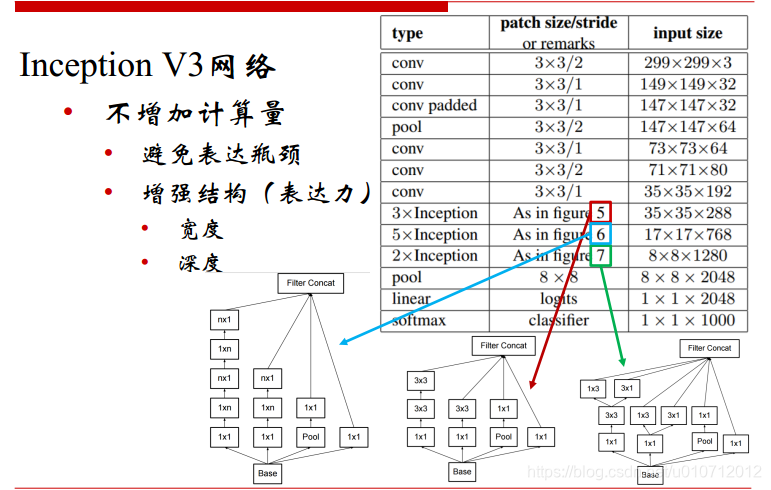
因此,作者Christian Szegedy设计了inception v4的网络,将原来卷积、池化的顺次连接(网络的前几层)替换为stem模块,来获得更深的网络结构。stem模块结构如下

stem之后的,同v3,是inception模块和reduction模块,如下图:


最终结构
6.Inception-ResNet-v2
ResNet的结构既可以加速训练,还可以提升性能(防止梯度弥散);Inception模块可以在同一层上获得稀疏或非稀疏的特征。有没有可能将两者进行优势互补呢?
Christian Szegedy等人将两个模块的优势进行了结合,设计出了Inception-ResNet网络。(inception-resnet有v1和v2两个版本,v2表现更好且更复杂,这里只介绍了v2)inception-resnet的成功,主要是它的inception-resnet模块。inception-resnet v2中的Inception-resnet模块如下图:

Inception-resnet模块之间特征图尺寸的减小如下图。(类似于inception v4)

最终得到的Inception-ResNet-v2网络结构如图(stem模块同inception v4)。
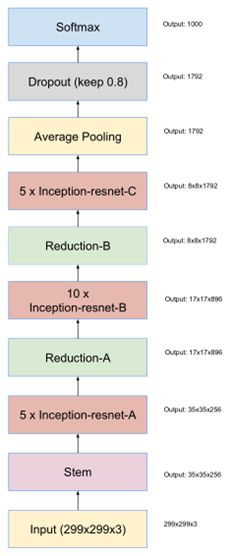
经过这两种网络的改进,使得模型对图像识别的错误率进一步得到了降低。Inception、resnet网络结果对比如表所示。
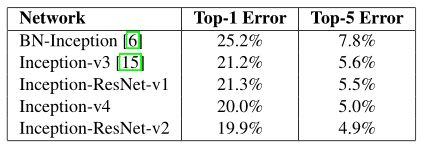
如表,Inception V4与Inception-ResNet-v2网络较之前的网络,误差率均有所下降。