深度学习与计算机视觉入门系列(上)
数据嗨客最近发布了一个深度学习系列,觉得还不错,主要对深度学习与计算机视觉相关内容由浅入深做了系统的介绍,看了一遍,在这里做一下笔记。
目录
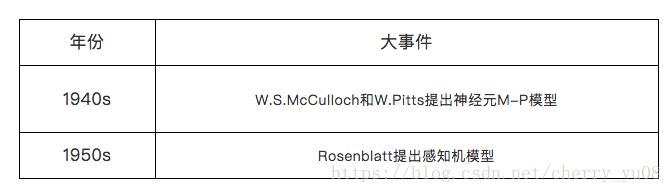
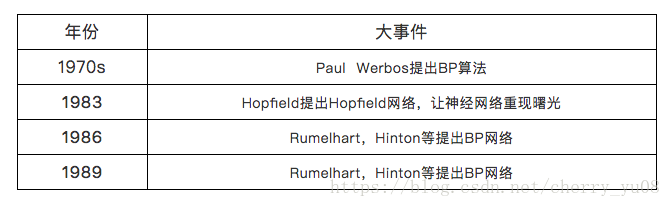
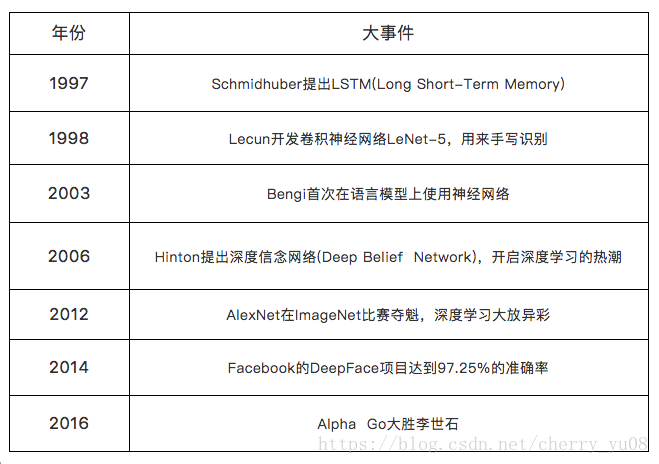
深度学习第1期:深度学习的历史与现状
文中介绍了深度学习的发展史,对于理解神经网络的一些基础知识有帮助:
感知机是线性的:
形式为:f(x)=sign(w·x+b),虽然也有激活函数,但是其决策面仍然是一条直线,是线性的;
深层网络是非线性的:
线性函数wx+b外面套了个非线性函数,即激活函数
深度学习第2期:人工神经网络
这一节非常基础,粗略看一下。
非线性的S(激活函数)进行线性组合、或者再符合S函数之后,得到的就不再是一个S函数。它会呈现为一个更加回环曲折的曲面形状。
神经网络是复杂多元函数的拟合器。
训练神经网络的过程就是在求解一个极值表达式。在这个极值表达式中,X是固定的参数,而w和b是可变的自变量。
而神经网络采取的方法是用线性组合与非线性函数不断地复合。这样可以使其在不至于太复杂的情况下模拟出复杂的函数。
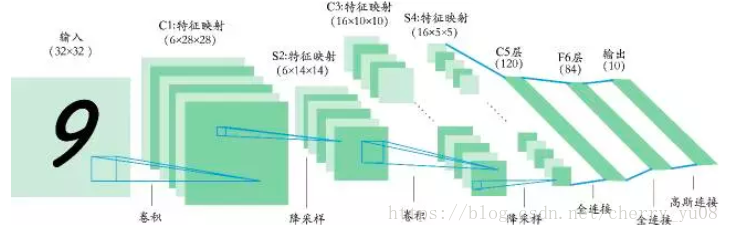
注意降采样的概念,以及最后一个全联接层也可以成为高斯连接层。
深度学习第3期:自编码器
自编码器可以理解为一个试图去还原其原始输入的系统:
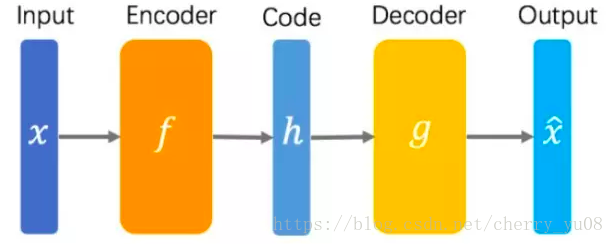

自编码器是一种特殊的网络结构,输入与输出相同,使用反向传播算法对输入进行重构的无监督学习模型(模型中不需要数据的标签y)。
对于自编码器,我们不关心输入层和输出层,而关心中间的隐含层,隐含层能提供一种新的特征表达,好的特征是一个成功的学习模型的重要因素。
一个例子,在训练完毕之后,如图所示,隐藏层不同隐藏单元学会了在图片的不同位置和方向进行边缘检测,提取图片的边缘特征。(一般在前面的几个隐藏层能看到一些可解释的代表图片信息的结构,但是随着层数加深,不稳定性增加,中间层的输出信息不太具有肉眼可见的解释性)

自编码器还包括稀疏自编码器、去噪自编码器、收缩自编码器等。
一些自己的理解:
在神经网络中最小化损失函数的过程,可以理解为,神经网络希望输出的内容与输入图像表达同一个意思,也即自编码器中的要求的输入与输出是同一个信息,这是一样的意思。在神经网络中,我们并不是要输出与输入图片一样的图片,而是输出的内容在经过中间隐藏层处理之后,表达的意思(信息或者信号)与输入图片一样。
深度学习第4期:卷积神经网络
目前在图像处理领域,卷积神经网络可以很好地解决各种问题。本文在介绍卷积神经网络结构的同时,还解释了为什么它对于图像数据具有如此强大的威力。
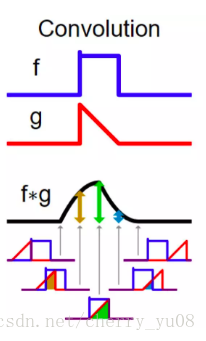
从例子中看, 是一个方形的函数, 是一个三角形的函数。将它们卷积在一起得到的 同时具有了 与 的特点,向左偏后又被向右“拧正”了一下。
(为什么上述卷积图像中g是反过来的?)
卷积是线性的。
卷积与傅立叶变换:
一段时域上的信号 进行傅里叶变换之后可以得到这段信号在频域上的频谱 ,卷积的重要性质是两个信号在频域上的卷积等价于时域上的乘积,而同理它们在时域上的卷积也等价于频域上的乘积。
对于一段时域上的信号 ,它的频谱是 。我们希望挑出指定频率范围内的信号,这就相当于要在频域上为它加一个窗口,即求出 ,再对其进行傅里叶变换,求出它在时域上的模样。
卷积的数学性质为我们提供了另一套解决方案。我们把频域上方块形状的 进行一个傅里叶变换,得到它在时域的样子 ,这是一个波浪的形状。然后,我们直接在时域上求出信号 与 的卷积 ,就相当于直接把信号 中在指定频率范围的部分给“挑了出来”。
卷积与图像处理:
与一维向量相同,多维的卷积也可以视作是一个线性变换。而且这种线性变换也在一定程度上利用了多维输入信号的顺序性与结构性,使得我们能够从中提取出信号中有效信息。这无疑十分适合用来处理图像数据,因为图像各个像素之间显然是具有结构性与顺序性的。打断一幅图像各个像素的位置,无疑就损失了图像中主要的信息。
神经网络是一个高度非线性结构。
全连接层:
神经网络的本质是万能的函数拟合器,其重点在于拟合能力要足够强。增加全连接层可以充分保证网络能够拟合各种各样复杂的函数。
深度学习第5期:CNN高级结构
目前CV各个方向的主流方法都是以CNN为主。可以说,目前的CV就是在各个领域上应用不同的结果的CNN。
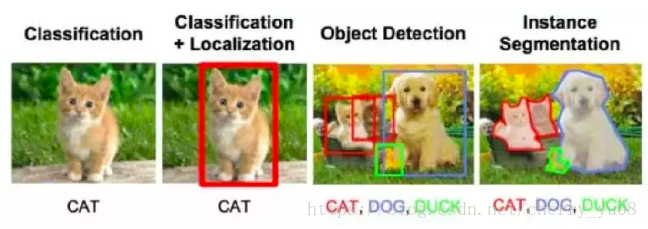
计算机视觉处理的主要问题:
CV的主要问题有:
分类;
目标识别;
图像分割(类似于FCN网络实现的功能);
还有去噪声、恢复等等。
对于不同的问题,训练集与预测集的形式将会有很大的不同,而解决问题所能用的CNN在结构上也有很大的差异。CV的主要几类问题及其目标如下图所示:
例如AlexNet,输入的图片经历一系列卷积提取特征,以及pooling不断降维之后,进入全连接层(FC)与softmax后输出。这是最常见、最基本的CNN的组织方式。而在下面,我们还要介绍几种特殊的组织方式。针对某些特殊问题,用这些特殊的trick组织CNN的基本构建之后,将会使得模型的性能有明显提升。
我们下面要介绍的trick可以笼统地分为两类:
一类是Inception与Xception,它们可以通俗地理解为在网络的“宽度”上做文章,即在同一层加入更多种多样的卷积核,或是对卷积核进行更细的拆分;
另一类是skip connection,residual block等,它们可以通俗地理解为在网络的“深度”上做文章,即为层与层之间提供更多、更丰富的联系,帮助信息高效地传递。
1. Inception
在传统的CNN中,要自己凭着感觉设计,这样很难保证设计出来的结构是最合理的。 而Inception则采用这样一种思路——让网络来自己选择架构。具体而言,它对于一个feature map同时采用的,的,以及的卷积核得到三个不同的feature map(调整zero padding的值使得三个输出大小一致),然后再将各个feature map线性组合起来,得到最终输出。a1,a2,a3也是可学习的参数。
GoogleNet采用Inception结构。
2. Xception
Xception:extreme Inception,即极端的Inception。
对于厚度(通道数)这个维度而言,输入的三个通道代表的是红黄蓝三种颜色的强度,而中间的feature map的各个通道则代表上一层各个卷积核卷积的结果。
也可以说,feature map的各个通道里装的是不同卷积核提取出的不同的特征。无论如何,feature map在厚度这一维度上的数据是不具有顺序关系的。因此,卷积核不应该在厚度的维度上进行滑动,而应该将各个通道同等对待。这也正是为什么一般卷积核的厚度与输入的通道数相同的原因。
由于feature map中各个通道具有独立性与无序性,我们很自然会想到,一个卷积核不必要同时承担空间上的信息提取与通道间的信息整合这两种任务。我们应该分别设计两种卷积核,一种对于指定通道进行空间上的信息提取,而另一种针对各个通道的信息进行整合。这样既有利于提取纯度更高的信息,也有利于将这些基本的信息整合为有用的信息。这也正是Xception的主要思想。
ception具有如下的形式:对于输入的feature map,它先用许多长宽不一,但是厚度均为1的卷积核分别对输入各个通道进行卷积(采用half padding)得到大量长宽一致,厚度为1的输出。它们代表用不同卷积核在不同通道上提取出的不同信息。然后,我们再使用k个长宽为1×1,但是很厚的卷积核,以将这些不同的信息以不同的方式组合。最后,我们可以得到长宽与输入一致,并且厚度为k的输出。
总的来说,Xception中主要体现了两种思想:第一是把经典的卷积对于空间与通道之间的整合区分开,分成为空间部分的卷积与通道部分的卷积;第二是要让网络具有更充分的,自己选择结构的能力。此外,Xception这种进一步将大卷积核拆开为几个小的卷积核乘积的做法有利于节省参数,即能够在只使用较少的参数时达到同样的表达能力,故而更加有利于网络在移动端等内存比较有限的场景下使用。MobileNet、SqueezeNet等模型都在一定程度上借鉴了这种思想。
3. 残差网络
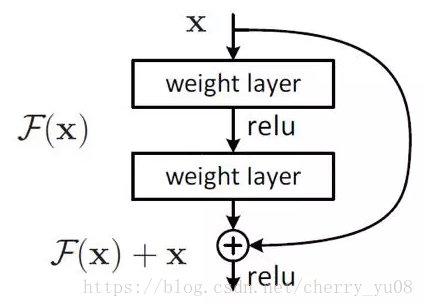
4. 跳连接与密集网络
ResNeXt:Inception与ResNet两种思想结合在一起。