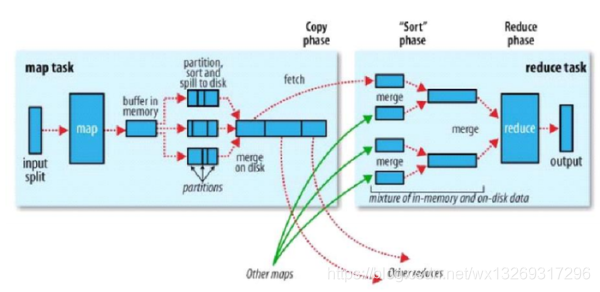
以wordcount为例,运行的详细流程图
1.split阶段
首先mapreduce会根据要运行的大文件来进行split,每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据位置的数组。输入分片(input split)往往和HDFS的block(块)关系很密切,假如我们设定HDFS的块的大小是64MB,我们运行的大文件是64x10M,mapreduce会分为10个map任务,每个map任务都存在于它所要计算的block(块)的DataNode上。
2.map阶段
map阶段就是程序员编写的map函数了,因此map函数效率相对好控制,而且一般map操作都是本地化操作也就是在数据存储节点上进行。本例的map函数如下:
1.publicclassWCMapperextendsMapperLongWritable,Text,Text,IntWritable{@Override
2.protectedvoidmap(LongWritablekey,Textvalue,Contextcontext)throwsIOException,InterruptedException{
3.Stringstr=value.toString();
4.String[]strs=StringUtils.split(str,’’);for(Strings:strs){
5.context.write(newText(s),newIntWritable(1));
6.}
7.}
8.}
根据空格切分单词,计数为1,生成key为单词,value为出现1次的map供后续计算。
3.shuffle阶段
shuffle阶段主要负责将map端生成的数据传递给reduce端,因此shuffle分为在map端的过程和在reduce端的执行过程。
先看map端:
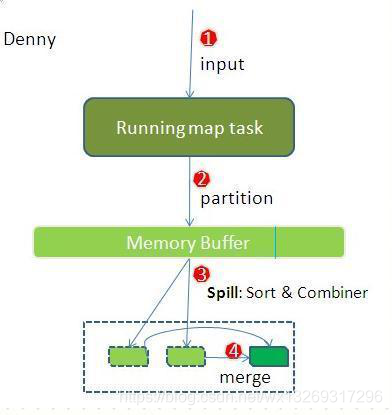
1.map首先进行数据结果数据属于哪个partition的判断,其中一个partition对应一个reduce,一般通过key.hash()%reduce个数来实现。
2.把map数据写入到Memory Buffer(内存缓冲区),到达80%阀值,开启溢写进磁盘过程,同时进行key排序,如果有combiner步骤,则会对相同的key做归并处理,最终多个溢写文件合并为一个文件。
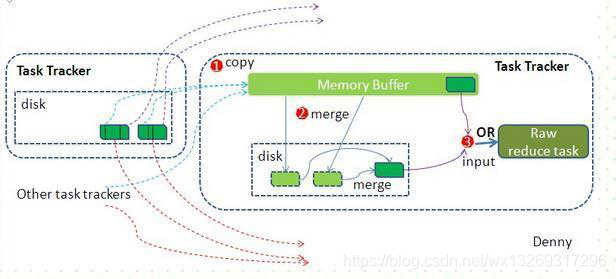
reduce端:
reduce对shuffle阶段传来的数据进行最后的整理合并
reduce节点从各个map节点拉取存在磁盘上的数据放到Memory Buffer(内存缓冲区),同理将各个map的数据进行合并并存到磁盘,最终磁盘的数据和缓冲区剩下的20%合并传给reduce阶段。
4.reduce阶段
reduce对shuffle阶段传来的数据进行最后的整理合并
大家多多关注!