MapReduce运行架构
前言
某天, 某研究机构设计了一款私人飞机图纸, 之后某公司根据该图纸制作出一架私人飞机. 然后某位有钱人士觉得这架飞机非常好, 就花高价钱买下这架飞机. 飞机要想起飞, 需要向空管局申请航线, 申请成功后, 这位富人又雇佣了一位飞行员. 最后飞行员开启飞机, 这位富人如愿坐上心仪的飞机并翱翔天际.
上述流程可以概括为:
设计图纸 --> 私人飞机 --> 空管局(申请航线) --> 雇佣飞行员(驾驶飞机) --> 开启飞机(翱翔天际).
看完上述实例, 再来看某个MapReduce应用的运行流程:
06年, MapReduce这一计算框架纳入Hadoop项目, 逐渐进入人们的眼帘. 一时间各大公司, 开发人员等都在学习使用MapReduce.
某一天, 你基于MapReduce的原理开发了一个Application(应用程序), 并将它放在服务器上运行. 运行开始后, App先向资源管理器申请资源, 资源申请成功后, App又去找任务调度器, 让它安排一个可以调度App的任务. 最后task执行App, 完成分布式计算.
上述流程可以概括为:
MapReduce框架 --> Application --> 资源调度器(申请资源) --> 任务调度器(执行App) --> 分布式并行计算.
既然程序的执行需要资源调度器和任务调度器, 那么MapReduce在各个节点上又是怎么运行的呢?
在之前的文章Hadoop简介中, 也曾提到过Hadoop两大版本的组成是不一样的, 不一样的最大区别就在于MapReduce应用程序运行时资源和任务的调度上. 接下来, 来看这两大版本是如何调度的.
Hadoop1.x版本
官方配图:
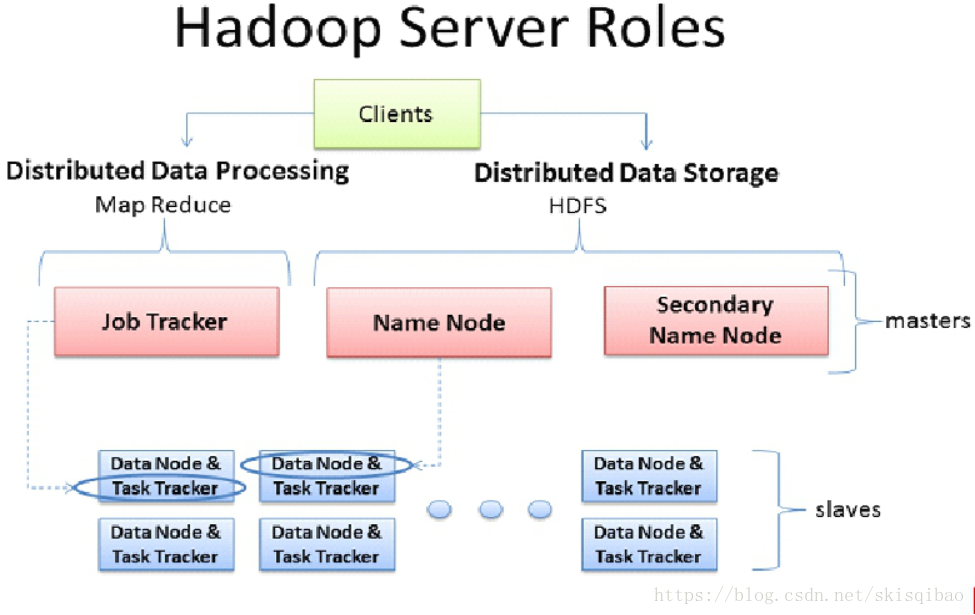
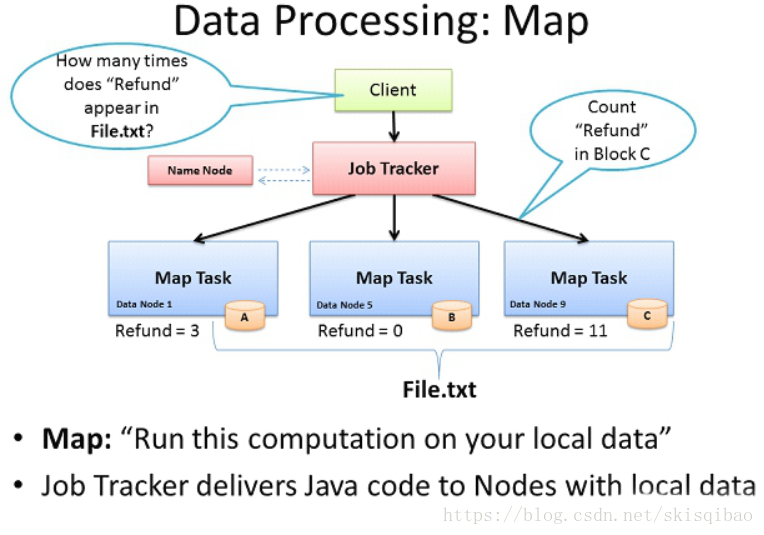
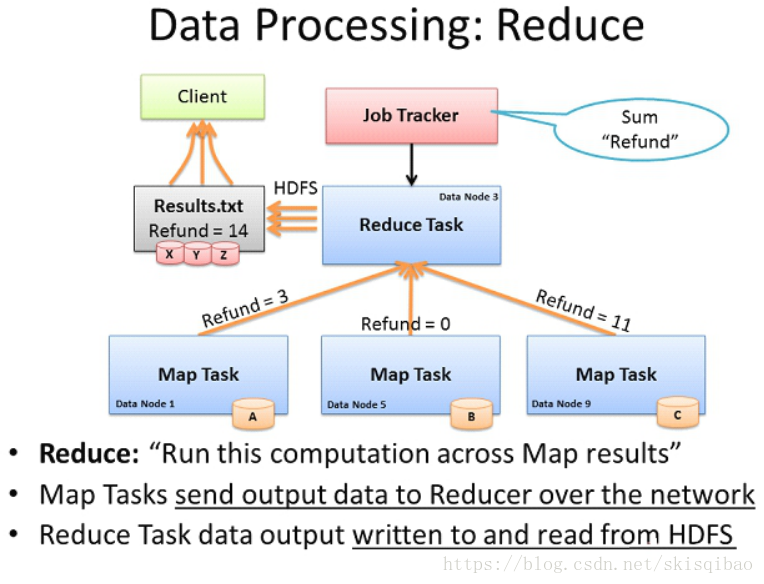
在Hadoop1.x版本, MR自带资源调度器, 资源调度器都是主从架构, 第一幅图中有两个新角色: JobTracker和TaskTracker.
上述三幅图的流程与下图相似:
再来分析这个流程图, 不难看出:
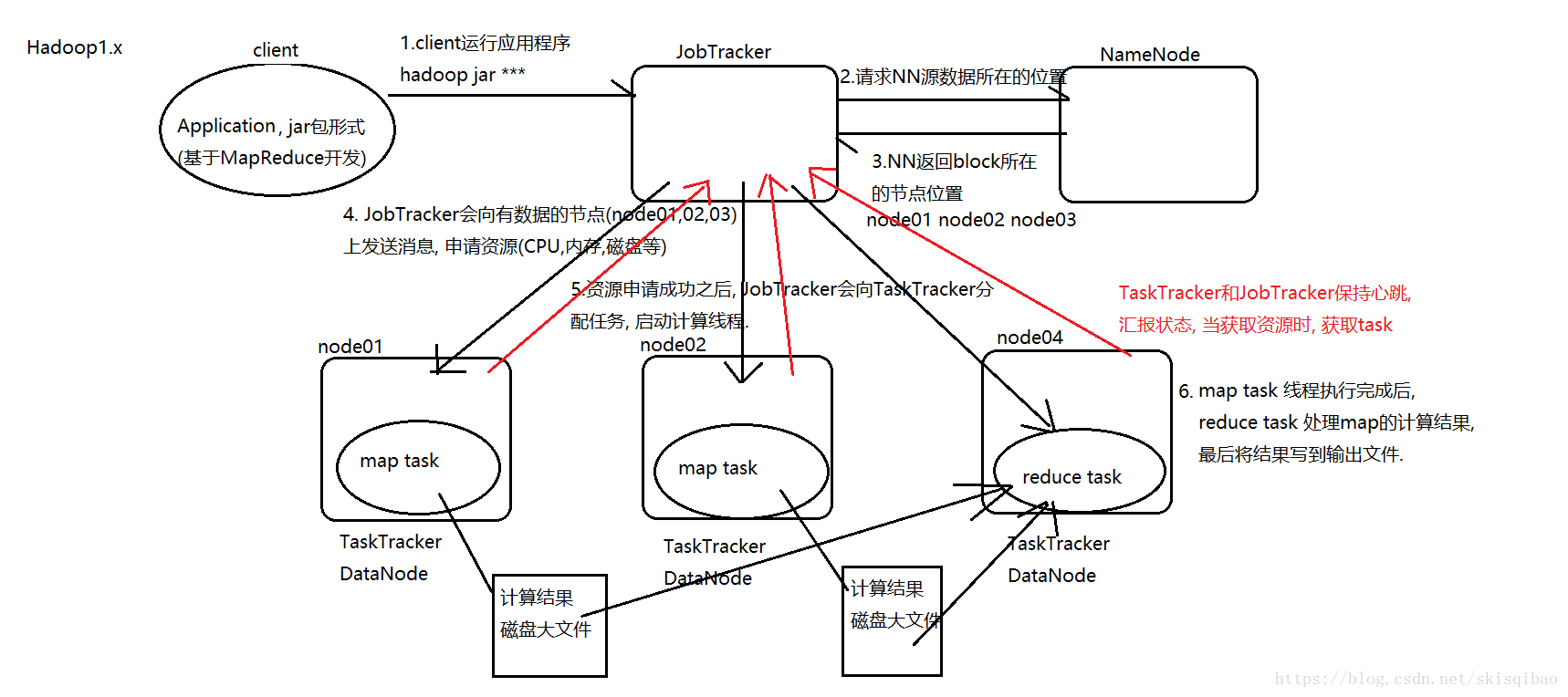
-
JobTracker的压力很大, 容易出现单点故障. JobTracker即是资源调度主节点又是任务调度主节点, 监控整个集群的资源负载.
-
TaskTracker是从节点, 管理自身节点的资源, 同时和JobTracker保持心跳, 汇报资源获取情况, 进而获取task任务.
-
资源管理与计算调度强耦合, 其他框架难以加入集群.
JobTracker, TaskTracker(以下简称JTT)是MR自带的, 如果想要在这个集群上运行Spark, 需要手动实现一套JTT, 实现之后这个集群就会有两套JTT来管理整个集群的资源.
当MR程序申请到资源 (假设申请大量资源) 开始计算时, Spark实现的JTT并不知道MR的JTT已经申请资源, Spark的JTT仍然会认为整个集群的资源是足够的, 当Spark的计算程序运行时, 也会去申请资源 (假设也申请大量资源) , 但此时集群上已经没有足够的资源, 这就会导致资源抢夺的问题, 造成资源抢夺的原因是因为资源隔离. 也就是说不同框架对资源不能全局掌控. -
MR处理思想是计算像数据移动, 或者说计算移动数据不移动, 或者说是数据本地化. 而上述流程中, reduce计算的数据"over the network"通过网络进行传输, 也就是说数据向计算移动, 这样就存在大量网络IO, 降低集群的效率.
而在Hadoop2.x版本中, 完全废除了MR自带的JTT, 引入一个新的资源管理工具 – Yarn, 下面来看Yarn是如何工作的.
Hadoop2.x版本
官方配图:
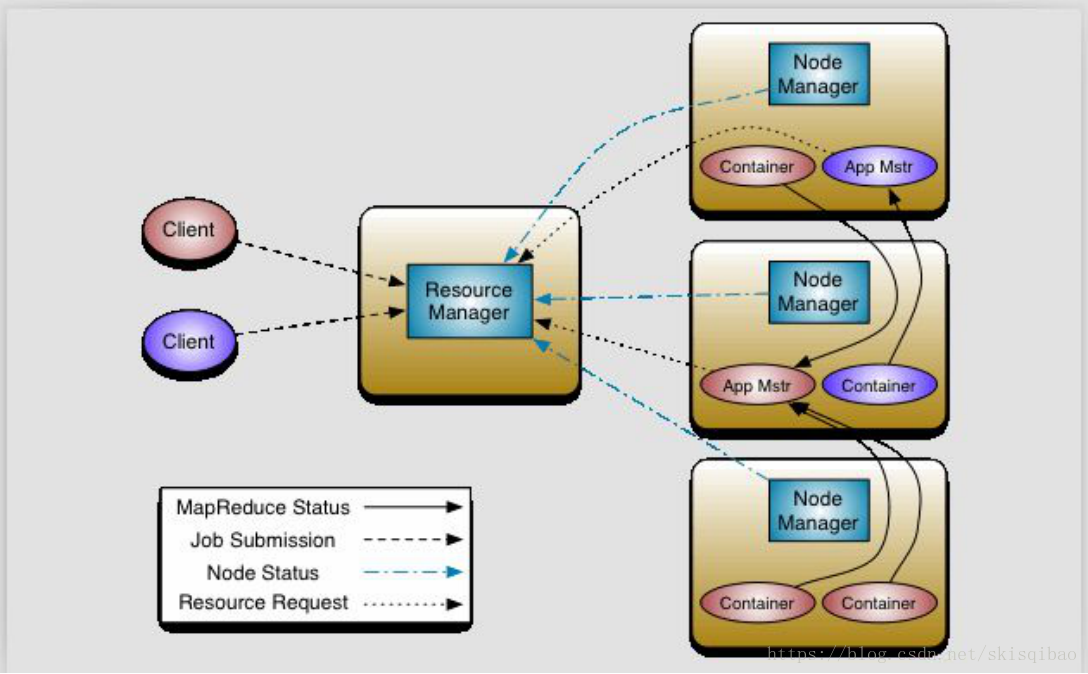
在Hadoop2.x版本, Hadoop将自带的资源调度器提取解耦形成一个独立的资源调度器 – Yarn(Yet Another Resource Negotiator), Yarn资源调度器也是主从架构. 主节点是ResourceManager, 从节点是NodeManager.
Yarn资源调度流程:
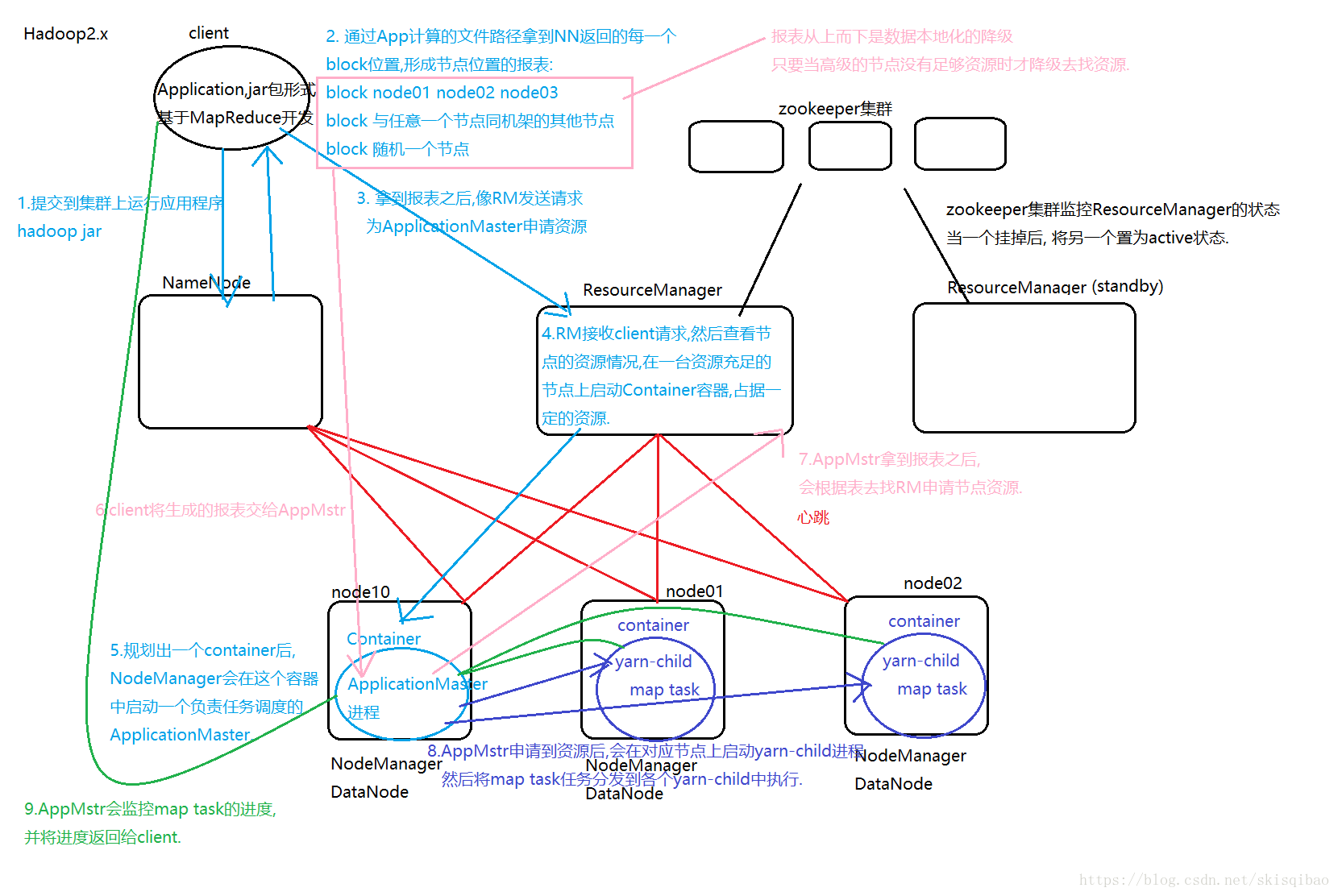
上述流程比较繁琐, 分为9步, 图中可以分析出:
- Yarn的核心思想将Hadoop1.x中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现.
- ResourceManager:负责整个集群的资源管理和调度
- ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等.
Yarn为AppMstr提供容错机制, 当AppMstr挂掉后, RM会在一台资源充足的随机节点上重新启动一个AppMstr.
每一个MapReduce作业对应一个AppMstr - NodeManager: 管理单节点上的资源, 处理来自RM的命令, 与RM保持心跳, 处理来自ApplicationMaster的命令.
- Container: NM节点上的资源抽象, 内存, CPU, 磁盘, 网络等资源的封装.
- YARN的引入,使得多个计算框架可运行在一个集群中. 每个应用程序对应一个ApplicationMaster. 目前可以运行在YARN上的计算框架有MapReduce、Spark、Storm等.