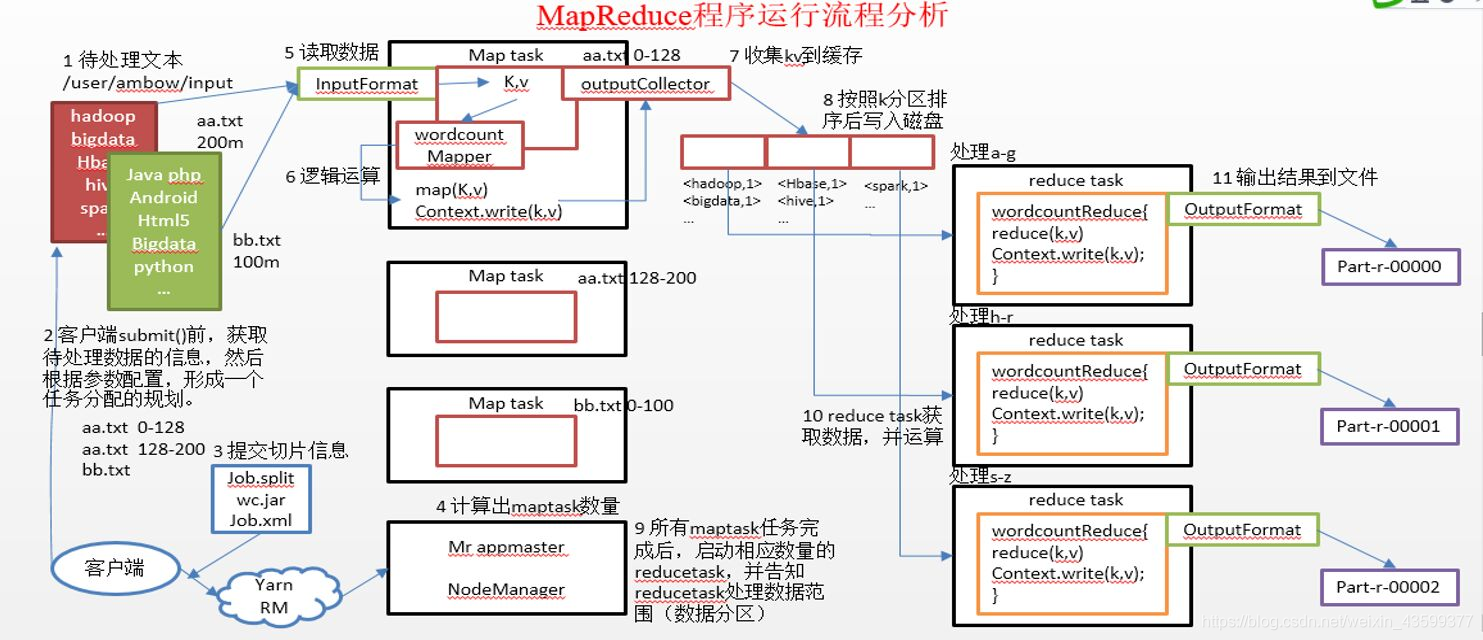
mapreduce运算过程分为两个过程:map阶段和reduce阶段
1.在进行数据计算时,首先通过DistributeInputStream对象进行获取数据
2.然后对数据块进行通过一定的偏移量进行切片,切片大小为默认128mb,然后每个切片对应着一个map集合,对于对单词的计数来说,map集合中的key是每个偏移量的数据,而value是默认是1
3.然后对map进行快速排序,其他工作的节点上的工作流程也是这样的 ,这样通过排序将key值相同的数据放置到了一起
4 .然后reduce判断如果map执行的任务完成了80%则reduce就开始执行任务,通过http的方式从已经排好序的数据集中去获取数据.获取数据的依据:MapReduce原语:“相同”key值的键值为一组,调用一次Reduce的方法,在这个方法内进行迭代计算这一组数据。进行获取数据集时,将相同key值的map结合中的数据进行获取(包括获取其他并行处理数据的节点上的数据),如果map任务找那个还有未执行完毕的任务,则reduce会先进行实时计算,进行归并排序,等待其他执行map节点上的任务完毕后,进行reduce的计算,reduce在进行计算时,将相同的key值相同的进行计算统计(数单词),然后将计算完毕的数据结果进行输出到HDFS进行储存。
Reducce是通过http按照分区号获取map输出文件的数据。map端有一个http服务处理该reducer的HTTP请求。该HTTP服务最大线程数有maperduce。shuffle.Max.threads属性指定。这个属性指定nodemanager的线程数,而不是对map任务的线程数,因为nodemanager上有可能运行着好多个任务,默认值是0,表示最大线程数是核心线程数的两倍。
map输出文件是位于本地磁盘的,一个reduce任务需要从集群中多个map任务获取指定该map任务的分区数据。多个map任务有可能是在不同时间完成的。每当map任务完,reduce就会从该map任务中获取指定分区的数据,为了高效率,reduce会以多线程的方式获取指定分区的数据。默认线程数是5,可以通过配置文件进行指定。
文件的溢写:当reduce从map任务完成去拷贝制定分区的文件时,如果内存缓冲区大大小达到了阈值(mapreduce.reduce.shuffle.merge.percent),或者map输出文件达到阈值,(mapreduce.reduce.merge.inmem.threshold)这时文件就会溢写在磁盘上。如果指定combiner合并,此处也会进行combiner
当reduce从所有的map拷贝了分区数据之后,reduce进入了合并阶段,那么合并多少次就是个问题,如果有50个文件,合并因子为10(mapreduce.task.io.sort.factor,默认是10),则需要5轮得到5个中间文件就不再合并直接输出。
给reduce的数据一般是内存和磁盘混合输出的形式。
