一个MapReduce的作业执行流程是:1)代码编写;2)作业配置;3)作业提交;4)Map任务的分配和执行;4)处理中间结果;5)Reduce任务的分配与执行;6)作业完成。具体如图1-1所示。下面以一个简单的单词计数例子对各个步骤做一个详细的介绍。
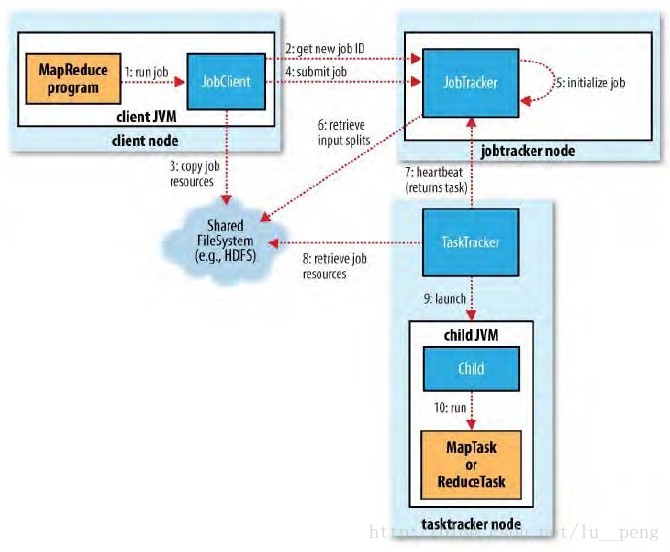
1代码编写及配置
代码编写及配置主要是在客户端进行。
1)代码编写主要是编写我们需要的map函数和Reduce函数。
map函数代码如下:
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()){
String word = itr.nextToken();
context.write(new Text(word),new IntWritable(1));
}
} Reduce函数代码如下:
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable value:values){
count+=value.get();
}
context.write(key,new IntWritable(count));
} 2)配置,主要是指定将来执行任务的map函数和Reduce函数是哪个,是否需要对map函数的输出结果做处理等等,在本例中,主要的配置如下:
job.setMapperClass(MapTest.class);
job.setCombinerClass(ReTest.class);
job.setReducerClass(ReTest.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//制定输入输出路径
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1])); 2作业提交
主要是讲作业提交到Hadoop集群上进行处理,可以通过如下方式进行作业提交:
job.waitForCompletion(true)调用waitForCompletion()方法之后,会进行判断,判断依据就是job的state,state在实例化Job对象的时候赋值为DEFINE:
Job(JobConf conf) throws IOException {
super(conf, (JobID)null);
this.state = Job.JobState.DEFINE;
this.credentials.mergeAll(this.ugi.getCredentials());
this.cluster = null;
}当判断job的state为DEFINE时,进行进一步提交,调用方法submit(),在submit()方法中会首先调用connect()方法进行初始化工作,接着调用submitJobInternal()方法进行进一步提交:
//进行初始化工作
this.connect();
//进一步提交
submitter.submitJobInternal(Job.this, Job.this.cluster);在submitJobInternal()方法中,进行相关操作获取作业ID,并且检查路径,计算作业的输入划分,将作业所需要的资源复制到以作业ID命名的目录下,调用submitJob()方法真正提交作业,代码如下:
//确定提交作业的主机地址,主机名,并且将其写入到配置conf中
this.submitHostAddress = ip.getHostAddress();
this.submitHostName = ip.getHostName();
conf.set("mapreduce.job.submithostname", this.submitHostName);
conf.set("mapreduce.job.submithostaddress", this.submitHostAddress);
//获取作业ID
JobID jobId = this.submitClient.getNewJobID();
job.setJobID(jobId);
//复制相关文件到
this.copyAndConfigureFiles(job, submitJobDir);
//根据分片信息确定map任务的数量,并将其写入到配置中
int maps = this.writeSplits(job, submitJobDir);
conf.setInt("mapreduce.job.maps", maps);
//真正提交作业
status = this.submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials()); 到这里,作业才真正的提交给MapReduce框架。
3 执行map任务
当作业提交给MapReduce框架(实际上是提交给了JobTracker)之后,并不是立刻就能够分配相关线程对对其进行处理,而是将作业放置到作业调度队列中,等待按照某种作业调度策略进行调度(如FIFO等),一旦获得调度,进行开始执行map任务。
jobTracker向TaskTracker分配一个任务,有TaskTracker来负责具体的map或Reduce任务的执行。TaskTracker会执行一个循环操作,定期向JobTracker发送心跳,报告自己的状态。
map函数通过createRecordReader(InputSplit var1, TaskAttemptContext var2)确定对分片中的数据的读取方式,在这里,因为使用的是FileInputFormat类,他重写了createRecordReader()方法,规定了对分片的数据处理方式为:以文件中的每一行数据作为value,每一行的偏移量作为key,形成一个key-value对,作为map函数的输入。有多少个key-value对,经调用多少次Map函数。
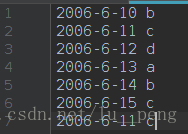
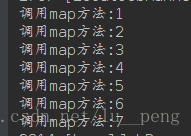
如图所示,我的输入文件有7行数据,作为一个分片对应与一个map任务,以行为单位,该文件中的数据可以听过createRecordReader()函数处理形成7个key-value对,因此将会调用7次map函数:
map函数处理完的数据会形成一个新的key-value对,map任务的输出结果会首先经过分区(Partition)函数进行分区操作,通常情况下按照key值通过Hash函数进行Hash之后对应到一个Reduce任务上,有R个Reduce任务就将这些key-value分成R个分区,并且进行排序。
之后这些数据会被写入到缓冲区中,当达到一定数量后,会写入到本地磁盘中的某个文件中,TaskTracker会把文件的地址报告给JobTracker,当map任务结束后,JobTracker会通知reduce任务去哪里读取该Reduce对应的输入数据,进行Reduce任务处理阶段。
4执行Reduce任务
执行Reduce任务分成三个阶段:shuffle阶段,merge阶段,Reduce函数处理阶段
shuffle阶段
Reduce启动一个复制线程,根据JobTracker传过来的地址,将对应的映射到自己任务上的数据复制过来
merge阶段
Reduce复制过来的数据会首先放入到内存缓冲区中,当缓冲区中的数据达到一定程度之后会进行内存缓冲区到本地磁盘的merge,实际上也是spill过程。
ps:实际上merge和shuffle是可以同时进行的,即边复制边merge。
Reduce处理
merge之后,会形成一个文件,这个文件可能存放在内存中(文件小),也可能存放在本地磁盘中(文件很大),文件中的数据形式为key-list对,这个文件就是作为reduce函数的输入,文件中有多少个key-list对,就执行多少次reduce函数。
5案例分析
就像1小节的例子,假设输入数据为两个文件t1,t2:
分别为:
| 文件名 | 文件内容 |
|---|---|
| t1 | Hello world Hello Hadoop |
| t2 | Bye world GoodBye Hadoop |
启动了2个map任务记为map1和map2和1个reduce任务,即map的所有输出都映射到同一个reduce任务上。
map任务的输出结果为
| map编号 | 输出结果 |
|---|---|
| map1 | hello 2,world 1,Hadoop 1 |
| map2 | Bye 1,world 1,GoodBye 1,Hadoop 1 |
map输出结果在reduce端进行shuffle和merge之后,形成一个临时文件,里面的数据为:
- hello [2]
- world [1,1]
- Hadoop [1,1]
- Bye [1]
- GoodeBye [1]
一共5条key-values对,因此会调用5次reduce函数。
输出结果为:
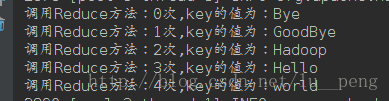
Bye 1
GoodBye 1
Hadoop 2
Hello 2
world 2而已可以看出reduce的输出结果是无序的,另外要知道每一个reduce任务都会对应一个输出文件,我这里只启动一个Reduce任务,所以只有一个输出文件。
此篇文章,是我个人对MapReduce执行流程的理解,可能会存在一些理解不到位的地方,或者是错误的地方,如发现,请指出,共同学习