深度卷积神经网络
2.1 为什么要进行实例化
实际上,在计算机视觉任务中表现良好的神经网络框架,往往也适用于其他任务。
2.2 经典网络
- LeNet-5
- AlexNet
- VGG
LeNet-5
主要针对灰度图像
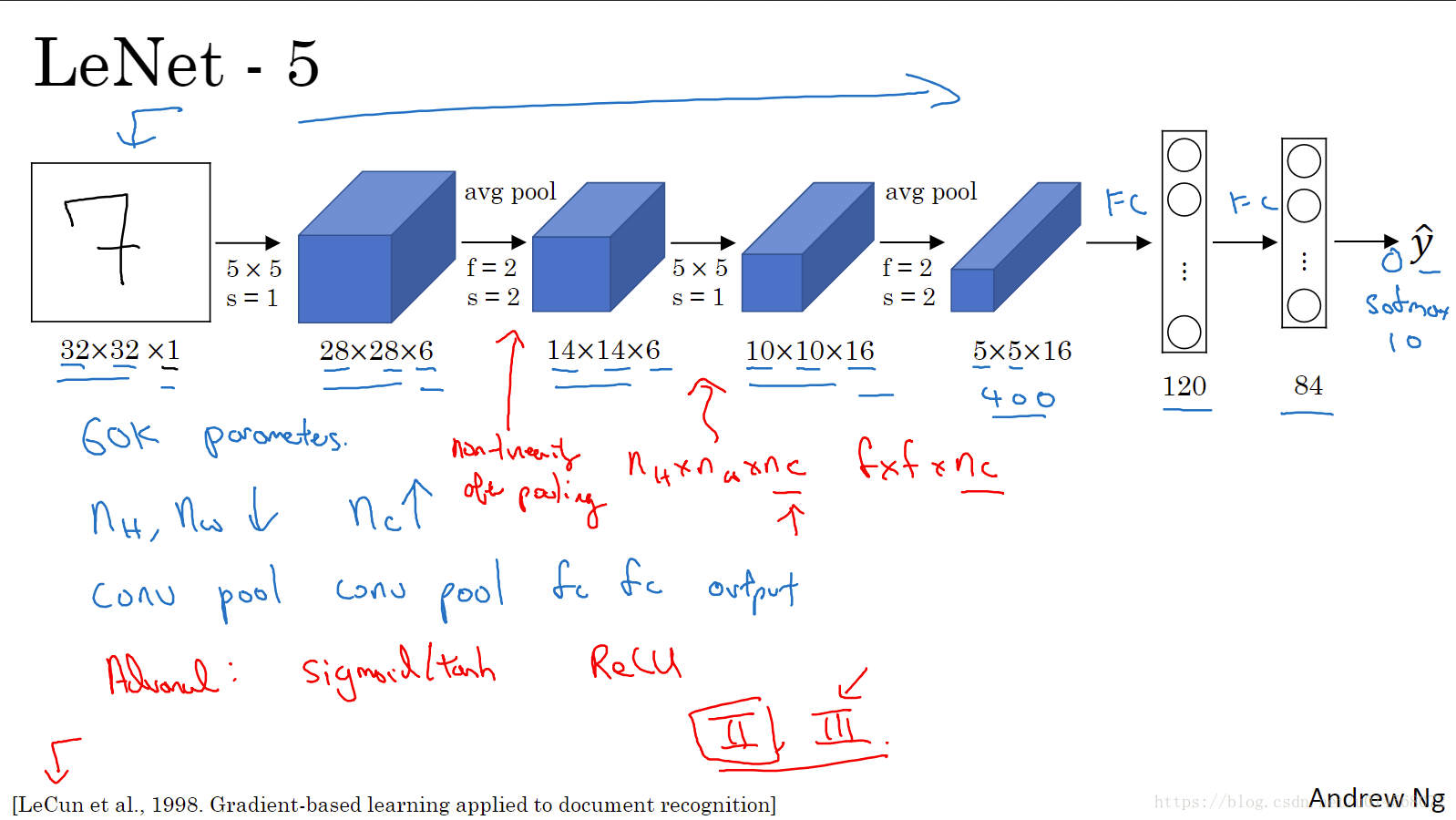
随着神经网络的加深,图像的高度
和宽度
在减小,信道数
一直在增加。
该神经网络中有一个至今仍在使用的模式:
AlexNet
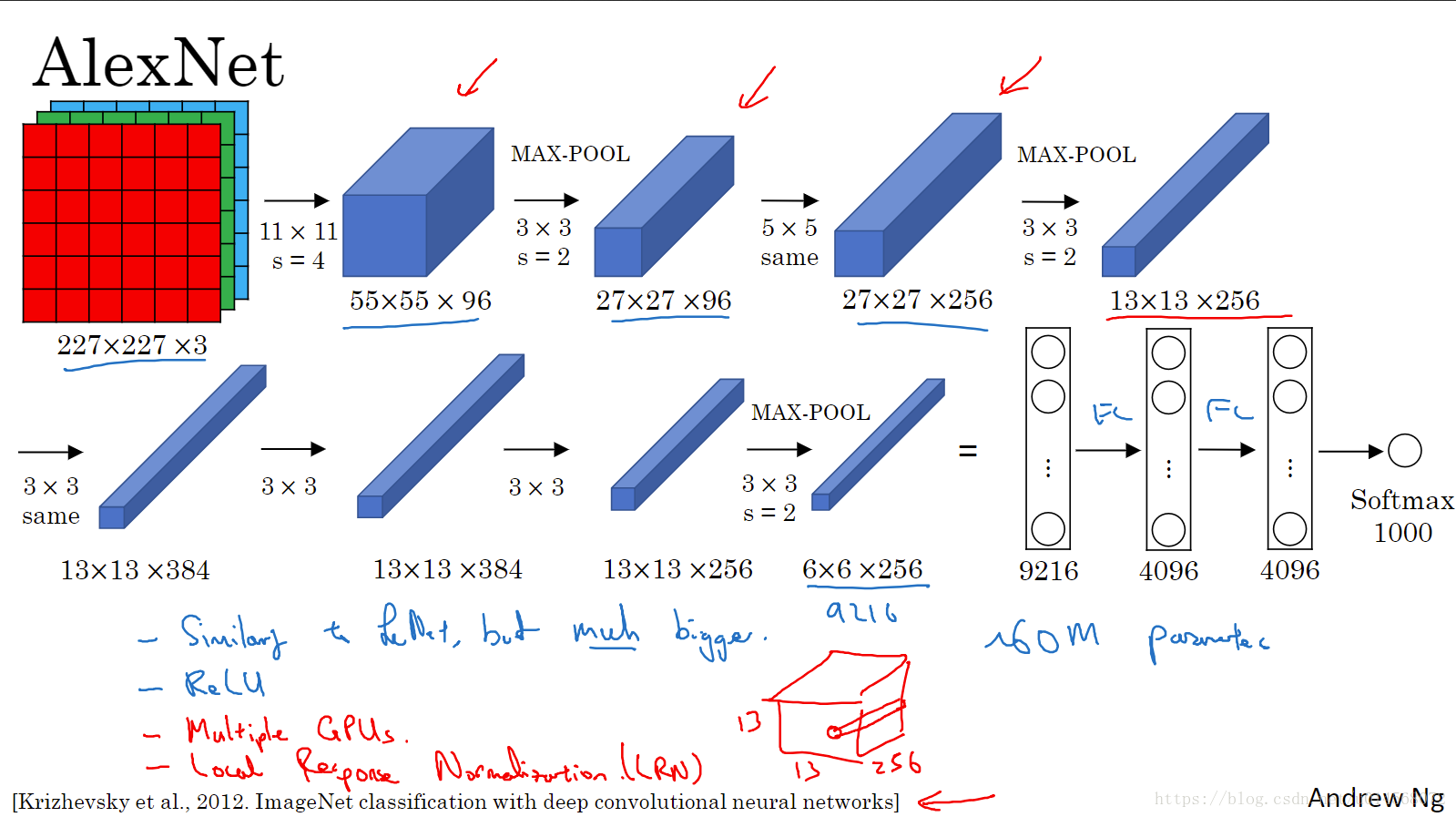
AlexNet大约包含6000w个参数,当用于训练图像和数据集时mAlexNet**可以处理非常相似的基本构造模块**,这些模块往往包含着大量的隐藏单元。另外,使用ReLU激活函数也使其性能更加出色。
VGG-16
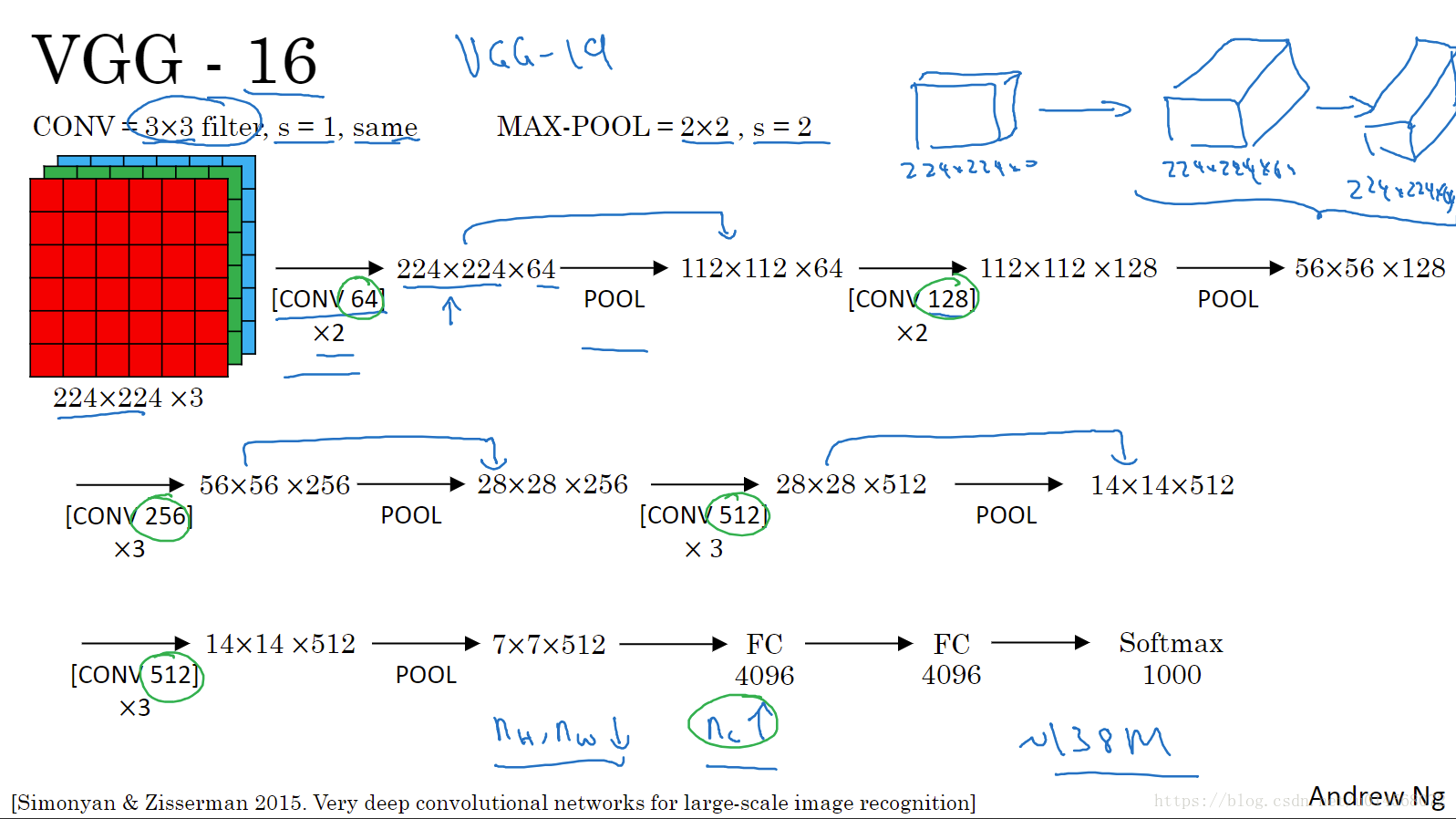
这是一种只需要专注构建卷积层的简单网络。16表示在这个网络中包含16个卷积层和全连接层。总共包含约1.38亿个参数,但是VGG-16结构并不复杂,包含一定规律:
- 几个卷积层后面跟着一个池化层,用于压缩图像大小。
- 卷积层的过滤器数量翻倍增加。
优点:简化了网络结构。
缺点:需要训练的参数巨大。
2.3 残差网络 Residual Network
非常深非常深的神经网络是很难训练的,因为存在梯度消失和梯度爆炸的问题。
解决方法:跳远连接,可以从某一网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。我们可以利用跳远连接构建能够训练深度网络的ResNets。
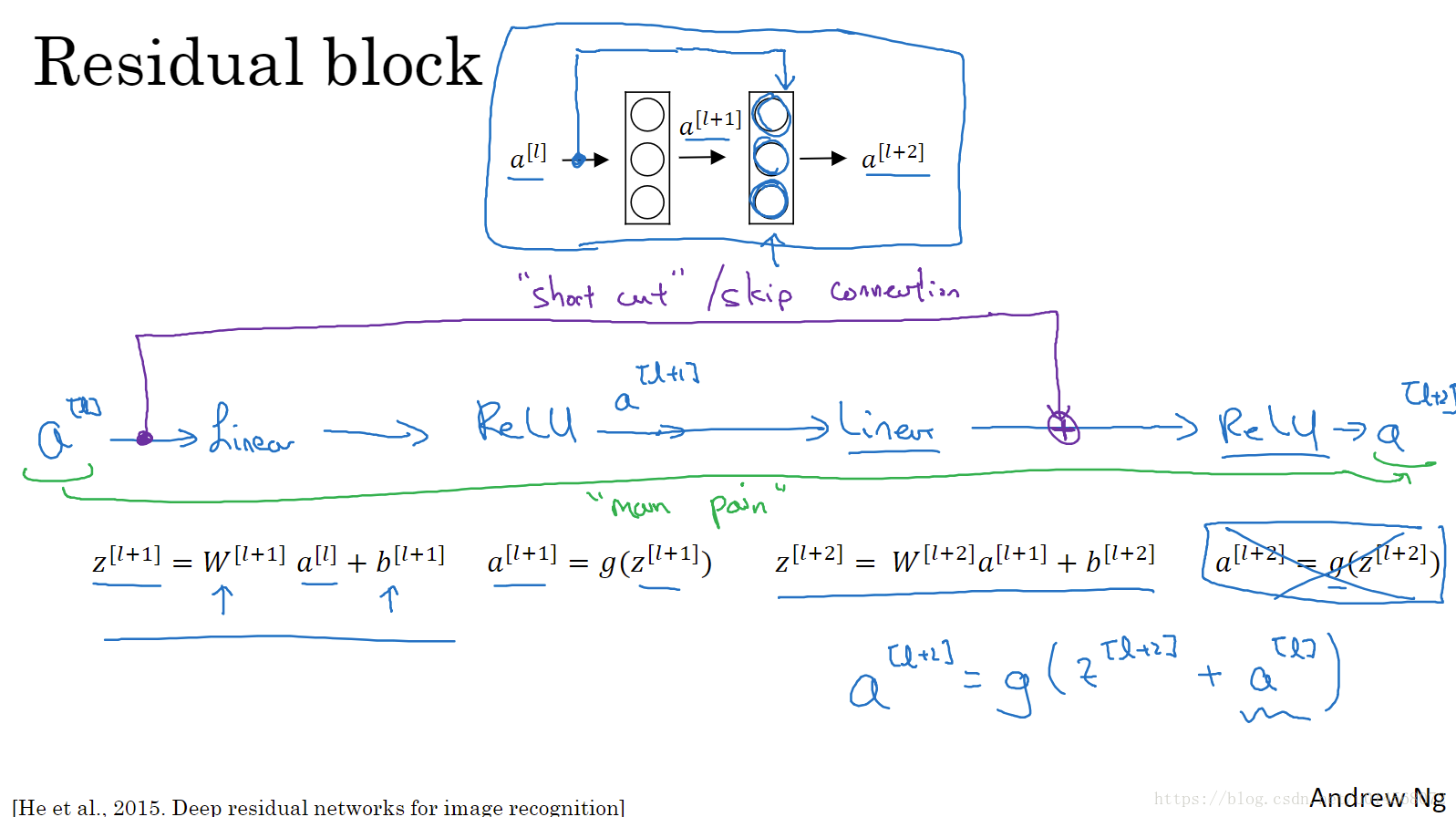
残差网络的变化主要体现在:
将
直接向后拷贝到神经网络深层,在ReLU非线性激活前面加上
(shortcut / Skip connection)。
的信息直接传递到神经网络的深层而不用沿着主路径传递,从而产生一个残差块。
插入的时机是在线性激活之后,ReLU激活之前。
每两层增加一个捷径,构成一个残差块,则整个网络构成一个残差网络。
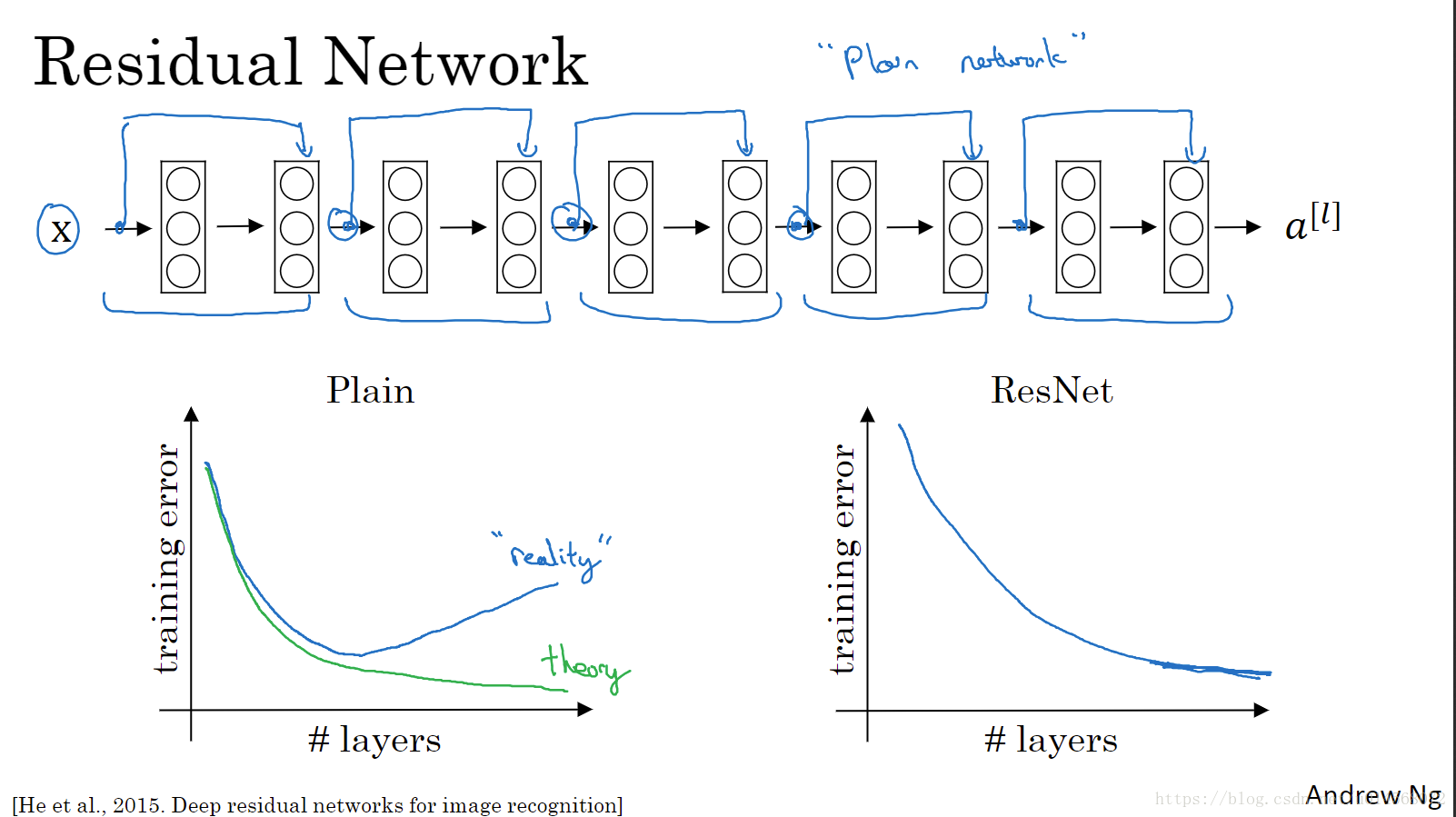
对于普通的训练,随着网络深度的增加,训练错误会先减少,后增加。因为深度越深,意味着用优化算法越难训练。
对于残差网络,即使网络再深,训练效果都会不错——训练误差在减小,有助于解决梯度爆炸和梯度消失的问题。
2.4 残差网络为什么有用?
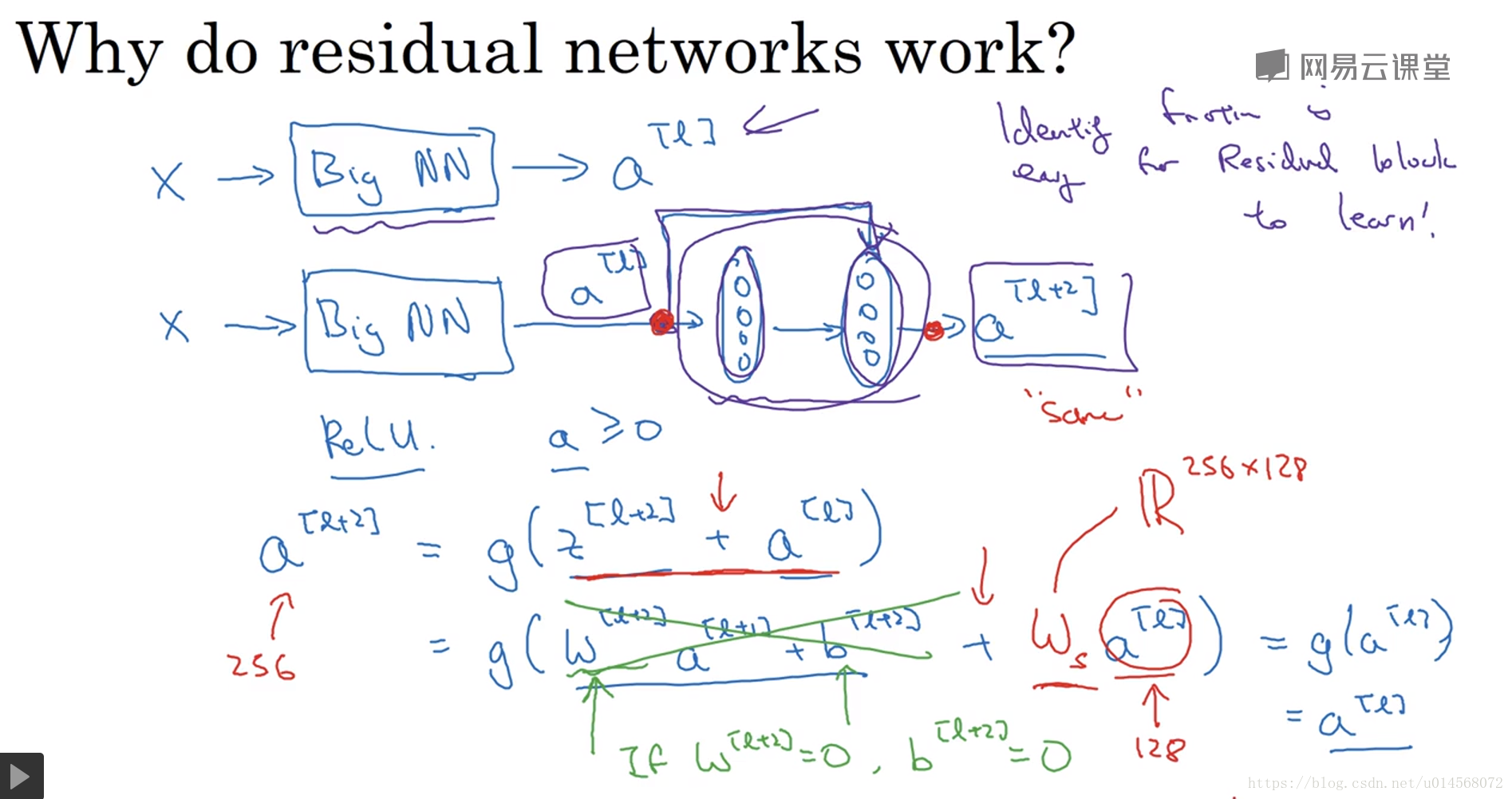
学习恒等式函数对于残差块来说很容易,Skip Connection使我们很容易得出
,这意味着即使我们在
与
之间加入两层,其效率也不会逊色于简单的神经网络,因为学习恒等函数对它来说很简单。
因此,不论是把残差块添加到神经网络的中间还是末端位置,都不会影响网络的表现,有时候甚至可以提高效率(或者说至少不会降低性能)。
假设
与
具有不同的维度,则需要在
前乘以一个相应的矩阵
以使其维度相同。
2.5 网络中的网络以及1×1卷积

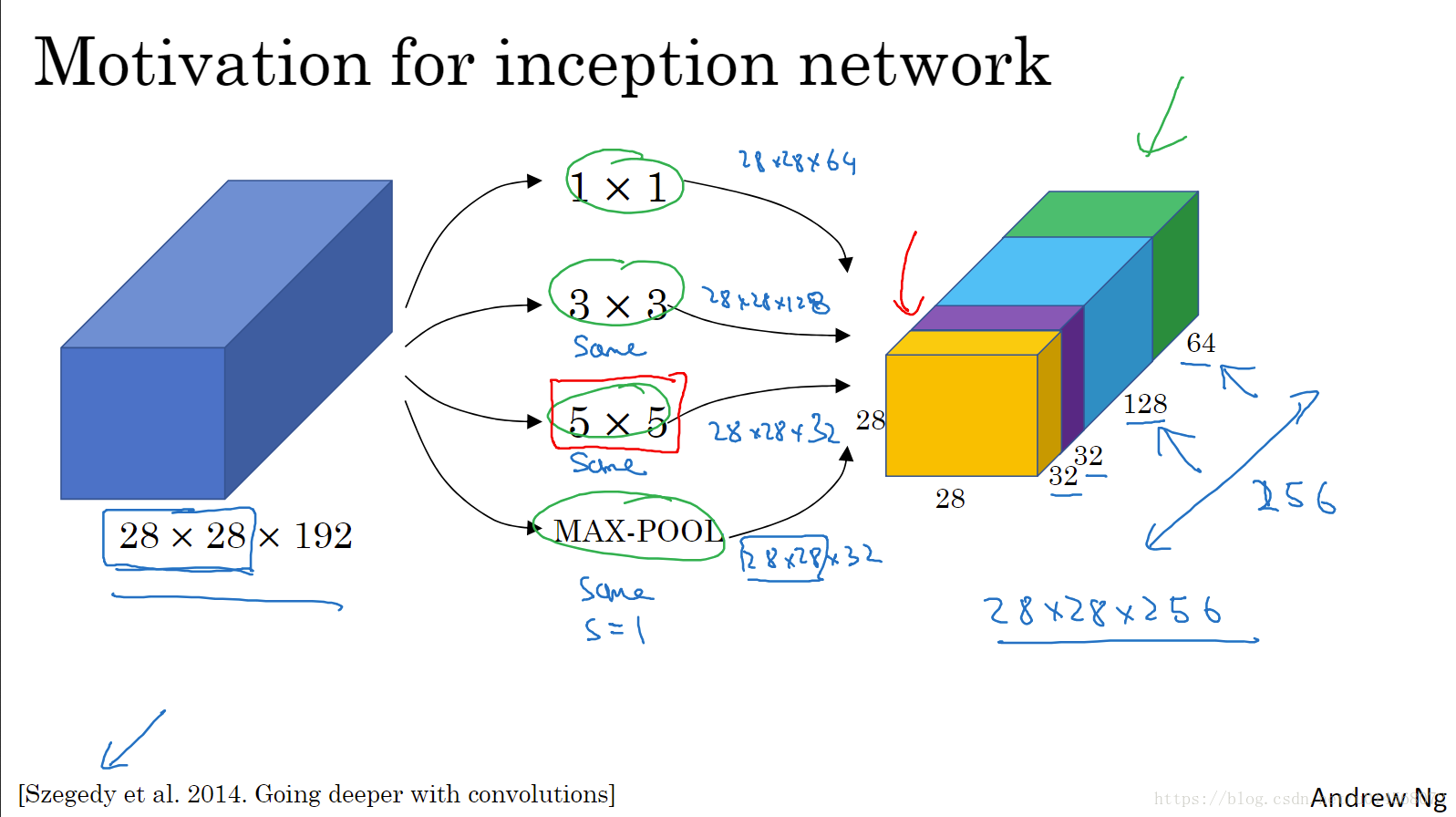
对于6×6×32的图片来说,1×1卷积实现的功能是计算蓝色图中32个数字和过滤器中32个数字的元素乘积,然后应用ReLU非线性函数。
1×1卷积(network in network)的作用可以理解为,在这32个单元都应用了一个全连接神经网络,全连接层的作用是输入32个数字和过滤器数量(标记为
),在36个单元(6×6)上重复此过程,输出结果是6×6×过滤器数量。
2.6 谷歌Inception网络简介
Inception网络或Inception层的作用是:代替人工来决定卷积层中的过滤器类型,或者确定是否需要创建卷积层或池化层。
核心内容:

使用1×1卷积,将最左打的输入层,压缩成中间这个较小层,又是被称为“瓶颈层”。先缩小,再扩大,从而大大降低了计算成本。
只要合理构建瓶颈层,则既可以缩小表示层规模,又不会降低网络性能。
2.7 Inception网络
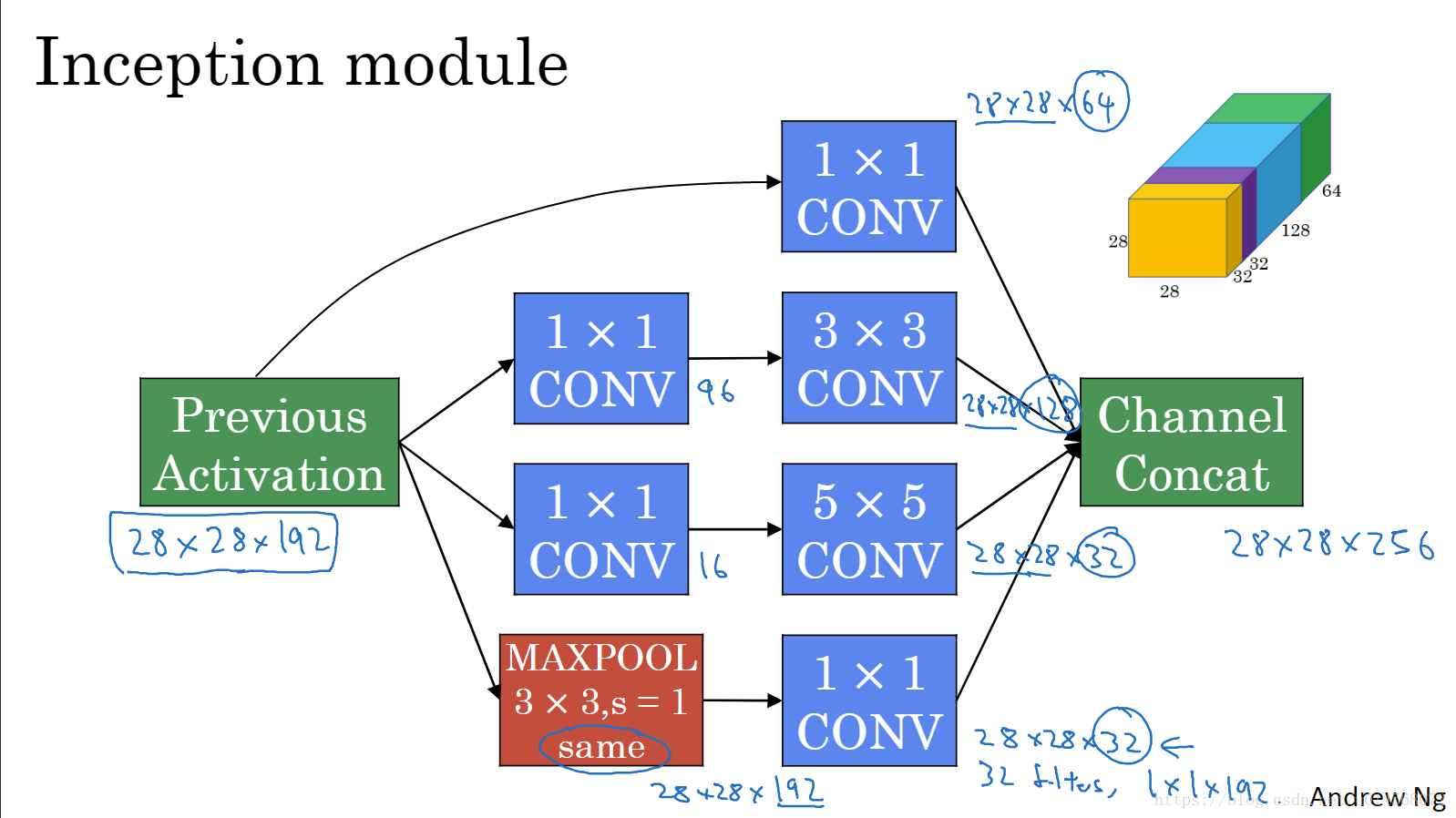
Inception模块将之前层的激活或输出作为其输入,然后将不同操作得到的结果直接连接起来——Channel Concat。
注意,如果使用最大池化,则输出信道数与输入相同,需要加一个1×1卷积将信道数减少。
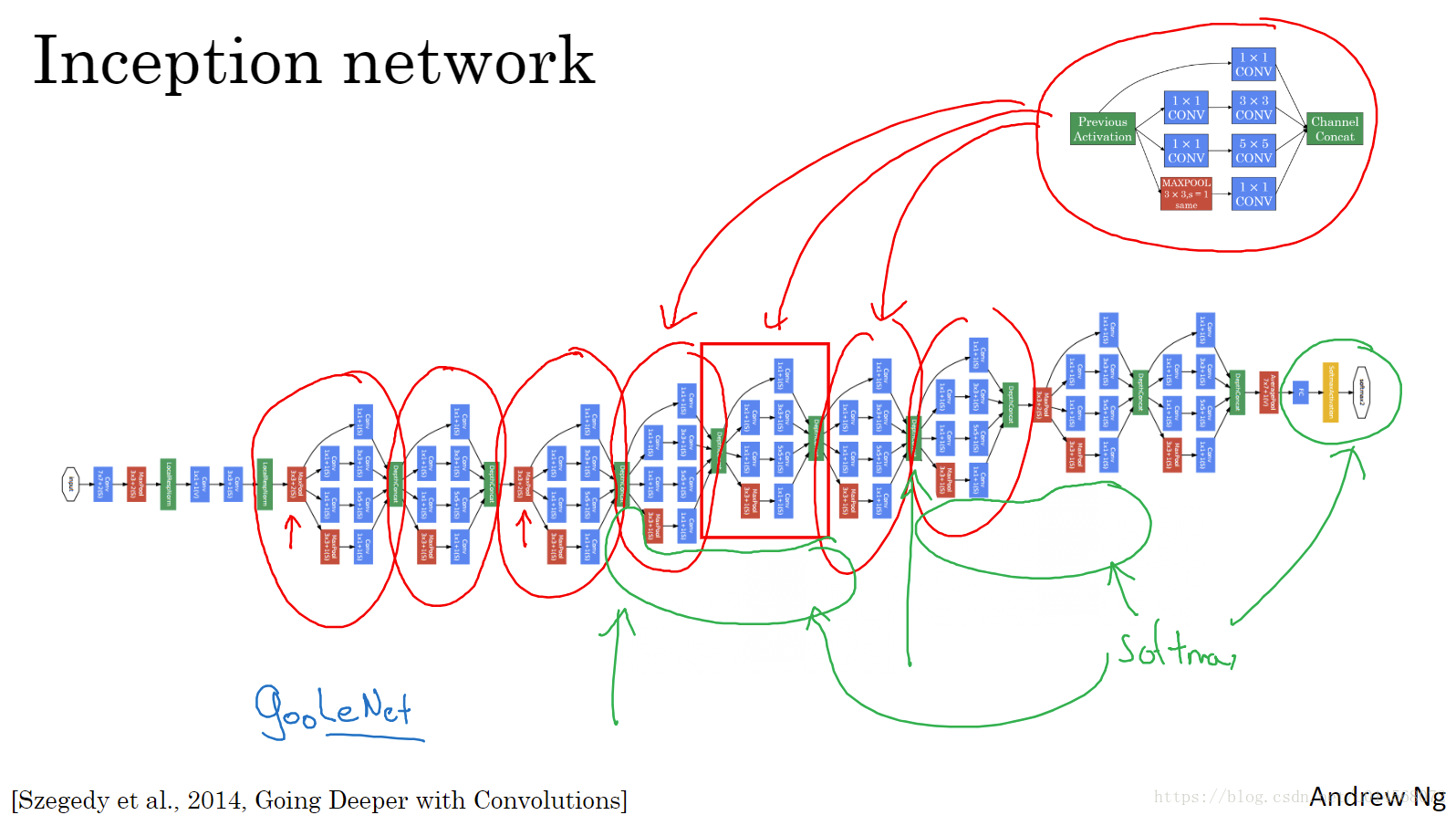
上图中的分支实际上是全连接层,通过softmax获得预测结果,起到调节作用,防止过拟合。
2.9 迁移学习
迁移学习——将公共数据集上的知识(权重参数等)迁移到自己的问题上。
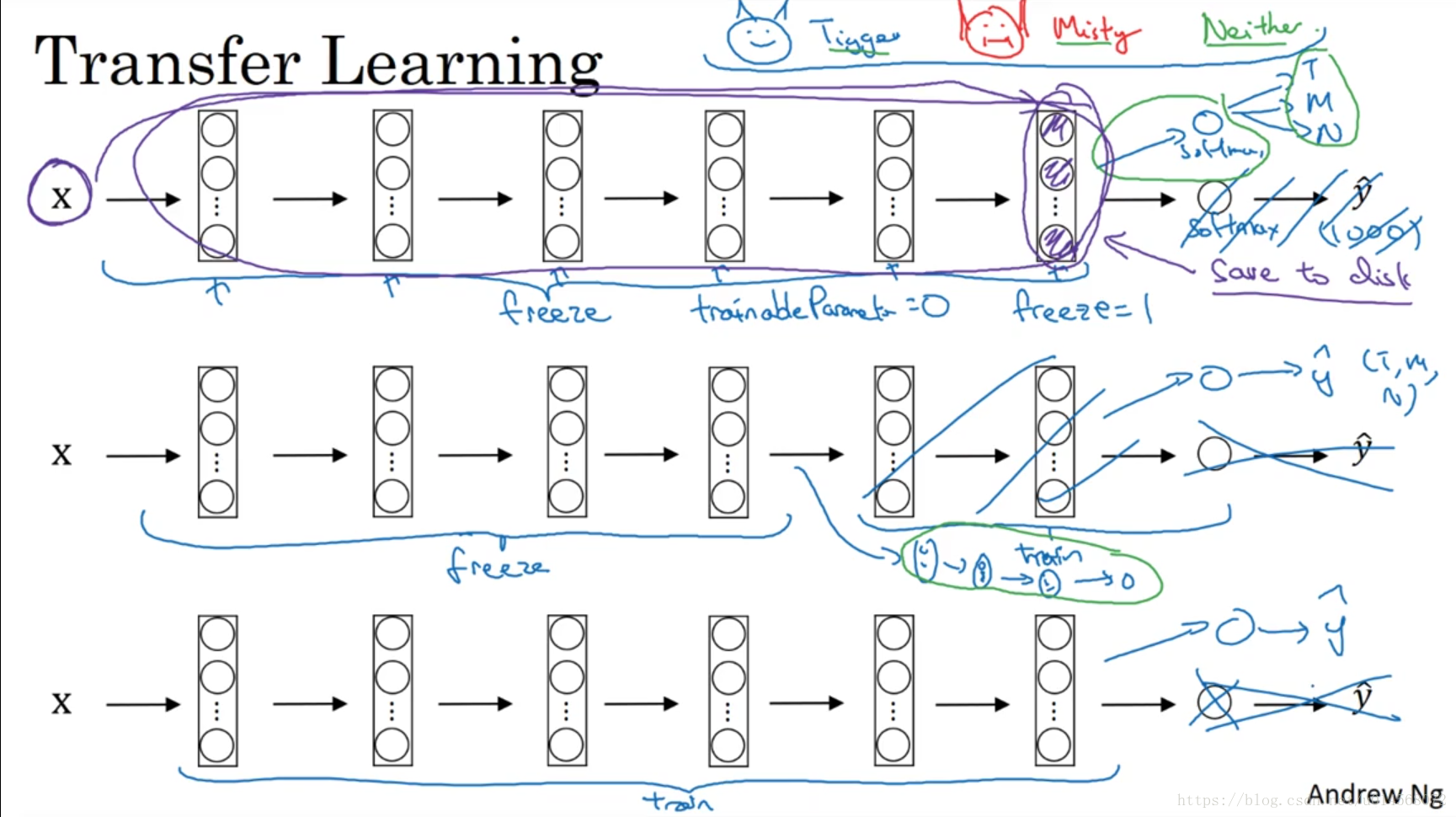
对于较小的数据集,网上的神经网络开源实现代码,可以直接使用其代码和权重参数,去掉最后的softmax层,创建自己的softmax单元以解决自己的实际问题。
可以将中间的神经网络视为冻结的,通过使用别人预训练的参数来获得比较好的性能效果。
对于更大的数据集,应该只冻结一部分层。冻结的层数越少,需要训练的参数越多。
如果有大量的数据,则可以冻结更少的层,甚至将开源神经网络和权重参数只作为初始化,来训练更多参数。
2.10 数据扩充
数据扩充方法:
1. 垂直镜像对称,随机裁剪、局部弯曲等。
2. 色彩转换
对RGB不同的采样方法:PCA(主成分分析)——影响颜色扭曲;PCA颜色增强;
2.11 计算机视觉现状
学习算法两种知识来源:
- Labeled data 已标签的数据
- Hand Engineered手工工程
ppt
集成
独立地训练几个神经网络,并对其输出做平均。(几乎不用于实际生产)测试时的multi-crop
是一种将数据扩展应用到测试图像的形式。