GloVe model
单词表示模型:GloVe,用于全局向量,全局语料的统计信息直接由模型获得。
符号
:词共现矩阵
:单词
出现在单词
的上下文中的次数。
:所有出现在单词
的上下文中的单词次数。
:单词
出现在单词
的上下文中的概率。
举例:
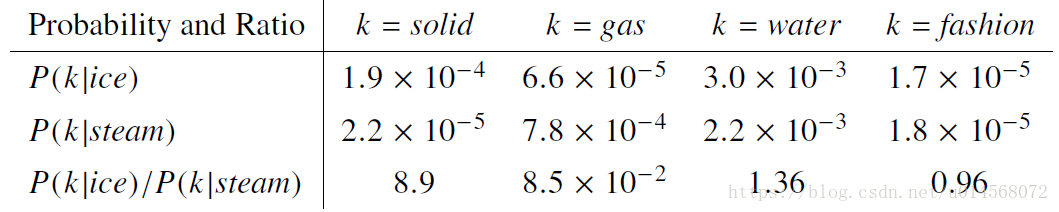
通过观察图中的比率(第三行)可以看出,当结果大于1时,单词 与ice更相关,当结果小于1时,单词 与steam更相关。
上述论点表明,单词矢量学习的适当起点应该是共现概率的比率而不是概率本身。其中,比率 取决于单词 、 、 ,我们采用最通用的模型形式:
其中,
表示单词向量,
表示单个的上下文词向量。
对于F的选择,由于向量空间本质上是线性结构,因此最自然的方法是使用向量差异。通过仅考虑两个目标词的差异可以修改为:
采用参数点积来防止 函数以不和需要的方式进行矢量维度混合:
对于单词共现矩阵,单词和上下文单词之间的区别是任意的,我们可以自由地交换这两个角色。我们的最终模型在这种重新标记下应该是不变的,因此我们通过两步骤来回复对称性。
首先要求
函数在
和
之间应该是同态的。
我们提出了一种新的加权最小二乘回归模型来解决噪音等问题。
其中,
是词汇表的大小。加权函数遵循以下规则:
1.
。如果
函数是一个连续函数,那么当
时,
是有限的。
2.
应该是非递减的。
3.
对于大的x值,它应该相对较小,以使得频繁的共现值不会超重。
我们找到了合适的函数:
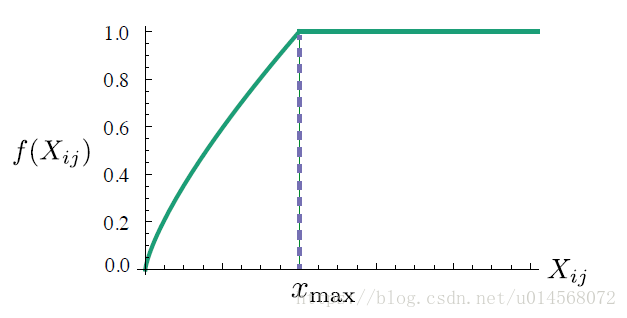
其中, 时效果最好。
模型复杂度
从等式(8)和加权函数 可以看出,模型的计算复杂度取决于矩阵 中非零元素的个数。因为这个数字总是小于矩阵大小,所以模型规模不会比 更差。但是典型的词汇表可以达到成千上万的单词,所以 可能是数千亿,比大多数语料库都大得多。因此还需要对非零元素的个数进行约束。
有必要对单词共现的分布做一些假设,我们假定单词
和单词
之间共现次数
可以被建模为该单词对的频率等级的幂律函数
:
语料库中的单词总数与同现矩阵 的所有元素和成比例。
是最大频率等级,与矩阵 中非零元素的数量一致,也是公式(8)中 的最大值。