参考代码:enas
1. 概述
导读:这篇文章是在NAS的基础上提出使用权值共享的方式进行网络搜索,避免了控制器采样得到sample的重复训练,从而压缩整体搜索时间的网络搜索算法ENAS。在NAS中首先由控制器采样出一个网络结构,之后将其训练到收敛,之后将该采样网络的性能作为控制器的reward(但是这里花了大力气训练出来的权重就会被丢弃,下一个网络结构又会从头开始进行训练),从而训练和引导控制器使其下一个产生的网络更好。这篇文章在网络参数上进行共享,每次从这个整体的网络搜索空间采样出来样本(一个子网络它们的参数是共享的)不需要训练到收敛,从而极大减少网络搜索的时间,使得其可以在1080Ti显卡上只要花费不到16小时就可以完成搜索。其在CIFAR-10数据集上获得了2.89%的错误率(相比NAS的2.65%),在时间大幅减少的同时效果已经相当接近了。
搜索空间的设计:
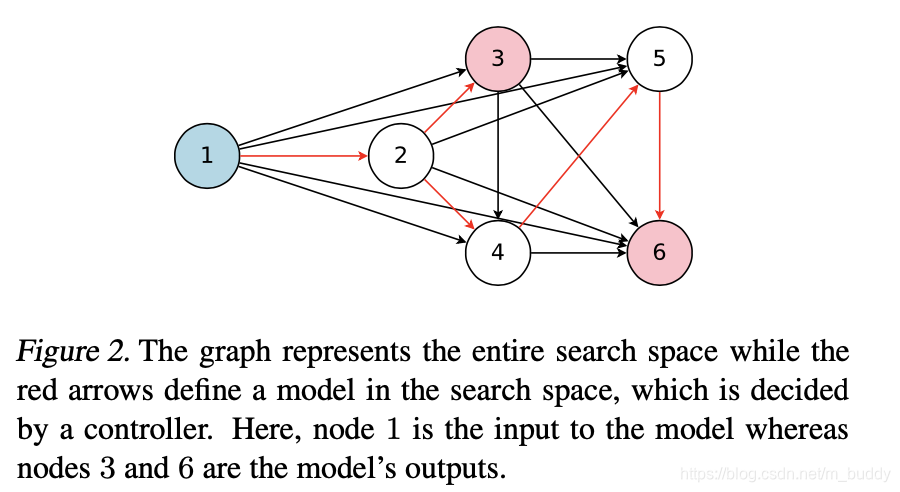
在这篇文章中为了实现搜索空间中的参数共享设计了一个超网络,其中的节点代表一个局部计算单元(其中含有需要训练的参数,若是被控制器采样到之后就可以用里面存储的参数信息,从而实现参数共享),其中的边代表了数据信息的流动方向,构建出来的图见下图所示:
搜索控制器的设计:
对于ENAS算法中的控制器部分,采用的是多个节点的RNN网络构成,它们的主要完整如下的两个任务:
- 1)控制那条边需要被激活,也就是选择当前节点的前序节点;
- 2)选中当前节点的操作类型,如卷积等;
每个节点中是有独立的参数的,它们在整个训练过程中重复使用(也是一种参数共享),下图展示的就是有4个节点构成的控制器结构(右图):
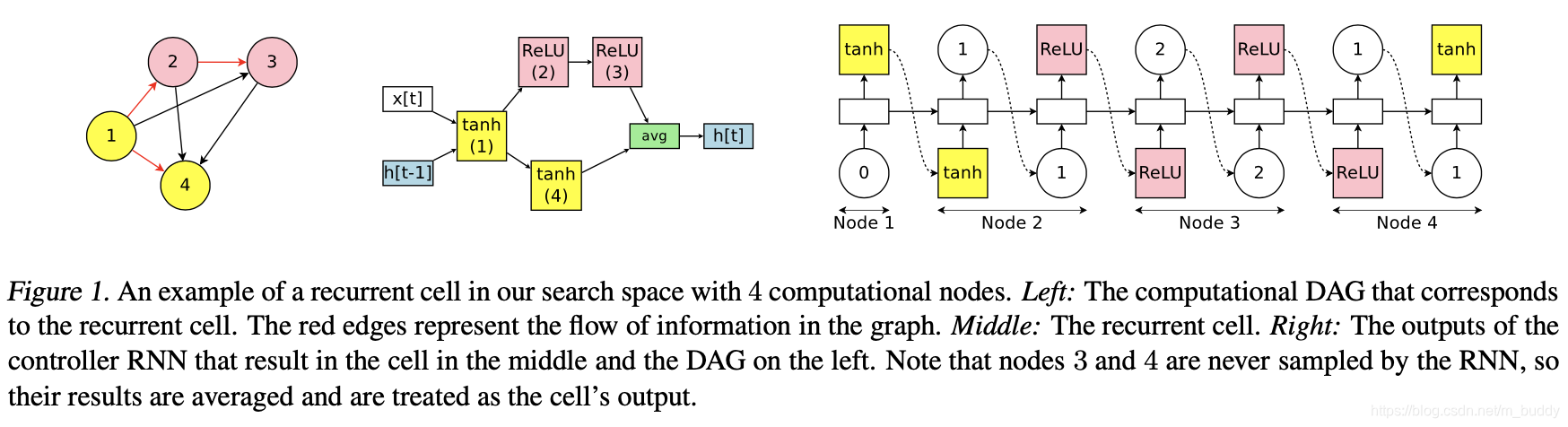
途中左边和中间的两个图分别是代表选择出来的子网络结构。
2. 方法设计
2.1 ENAS的训练与最后网络的生成
文章设计的整个方法涉及到两个分布参数的训练:
- 1)控制器RNN网络的参数 θ \theta θ;
- 2)由控制器采样出来的子网络参数 w w w;
从ENAS的算法流程可以知道这两个参数是交替进行训练的,首先完成对子网络参数 w w w的初始化训练,再训练RNN控制器网络部分,之后这两个网络交替进行训练,直到收敛。
子网络参数 w w w的训练:
在训练子网络参数的时候首先会固定控制器的参数,从中采样出来一个子网络 m i = π ( m ; θ ) m_i=\pi(m;\theta) mi=π(m;θ),之后对于他的训练就是标准的CNN网络训练过程了。那么这部分的下降梯度可以描述为:
∇ w E m ∼ π ( m ; θ ) [ L ( m ; w ) ] ≈ 1 m ∑ i = 1 M δ w L ( m i , w ) \nabla_wE_{m\sim\pi(m;\theta)}[L(m;w)]\approx\frac{1}{m}\sum_{i=1}^M\delta_wL(m_i,w) ∇wEm∼π(m;θ)[L(m;w)]≈m1i=1∑MδwL(mi,w)
其中, M M M表示的一次性采样的子网络的个数,尽管在采样个数固定的时候这样的采样方式会带来较大的方差,但是文章指出其在 M = 1 M=1 M=1的情况下也能很好工作。
控制器网络参数 θ \theta θ训练:
训练控制器那么对应的就需要固定子网络的参数 w w w了,这里由于是以离散的方式进行采样,对于控制器参数更新梯度的来源是使用policy gradient的方式进行的。这里将子网络在val数据集上的性能作为反馈 R ( m ; w ) R(m;w) R(m;w),从而去最大化这个反馈:
E m ∼ π ( m ; θ ) [ R ( m ; w ) ] E_{m\sim\pi(m;\theta)}[R(m;w)] Em∼π(m;θ)[R(m;w)]
Policy Gradient讲解:【CS285第5讲】Policy gradient
除了上文提到的监督优化之外,文章还引入了对skip connection的约束,在代码里面是使用的KL散度,其先验是0.4。引入它是为了防止网络生成过多的skip connection,从而使得网络抽取的特征越来越浅,表达能力和泛化能力降低。
最后生成网络的选择:
最后需要生成最后的子网络,一般是采取一次性通过 π ( m ; θ ) \pi(m;\theta) π(m;θ)采样得到几个子网络,将其在val数据集上进行性能比较,在其中选择性能最好的一个,将其从scratch进行训练。
2.2 搜索空间的设计
传统网络层构建:
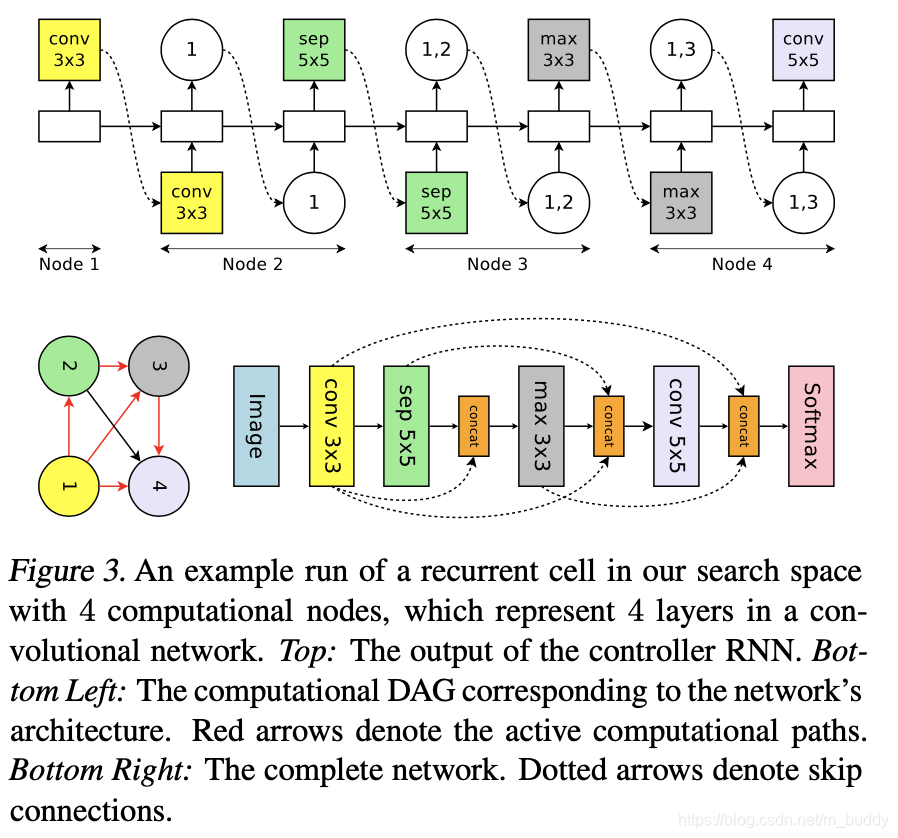
这里在进行搜索的时候是固定需要搜索的网络层数 L = 12 L=12 L=12,之后在这基础上构建控制器,控制器完成的功能与上文中提到的类似,只不过所选用的操作不同,这里采用的操作空间为:卷积核大小为 3 ∗ 3 , 5 ∗ 5 3*3,5*5 3∗3,5∗5的常规卷积和可分离卷积,池化核大小为 3 ∗ 3 3*3 3∗3的均值和最大值池化操作。其实这里虽然全排列起来包含的变化很多,但是还是很多超参数是固定的,也是存在一定的局限。对于这部分其搜索的流程见下图所示:
基于网络cell进行构建:
像上面逐层进行网络搜索效率较低,一个自然的思想就是将一些网络操作组合成一个小模块,通过小模块的堆叠实现整体网络的构建,如下图所示:
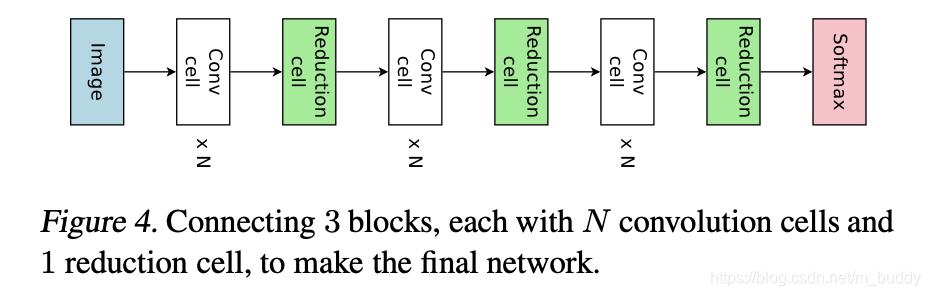
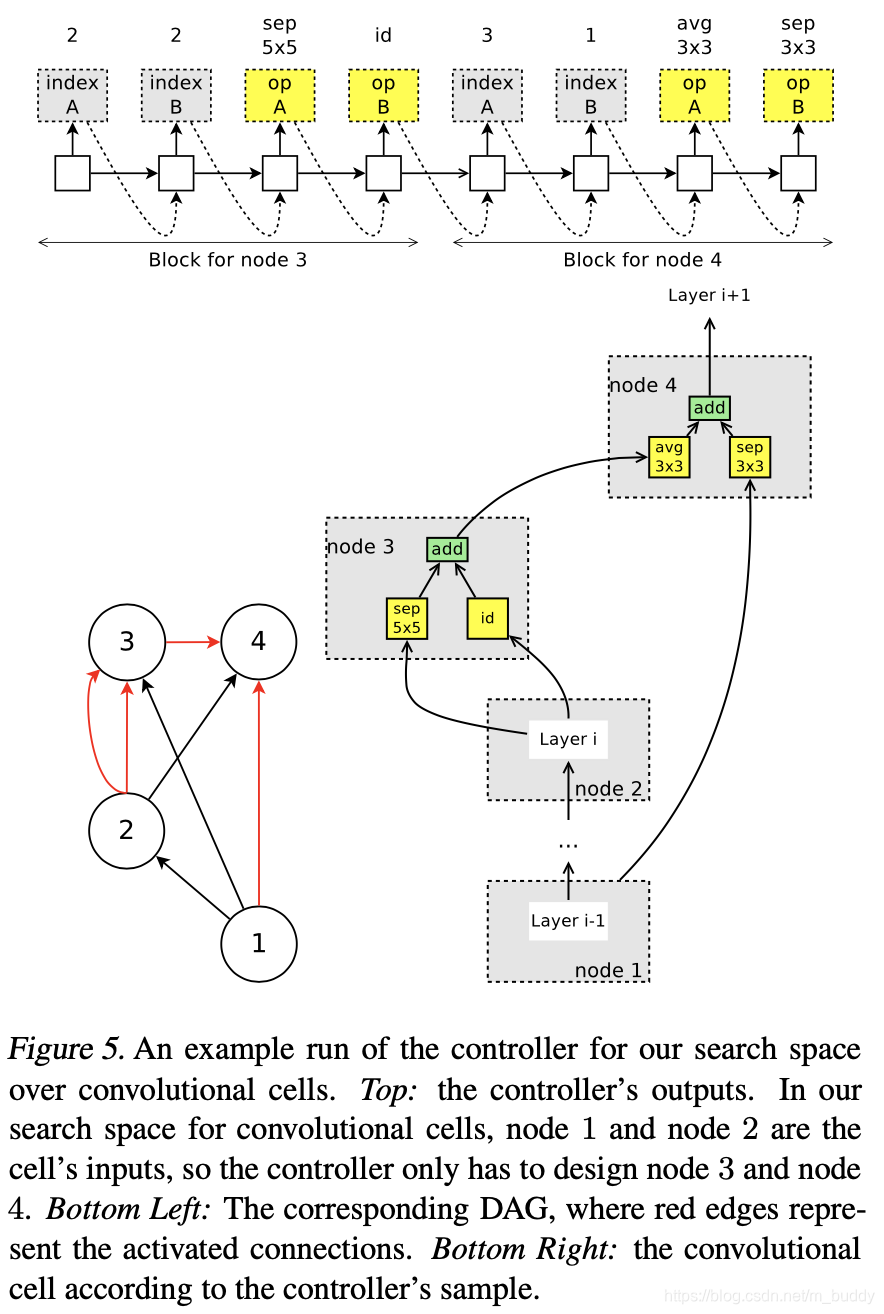
对于这样的搜索情况文章对控制器部分进行了改进:
- 1)从前序的节点中选择两个作为输入;
- 2)为这两个输入选择合适的操作类型,不同大小的卷积核以及卷积类型等;
下图展示了这种搜索方式的流程示意图:
3. 实验结果
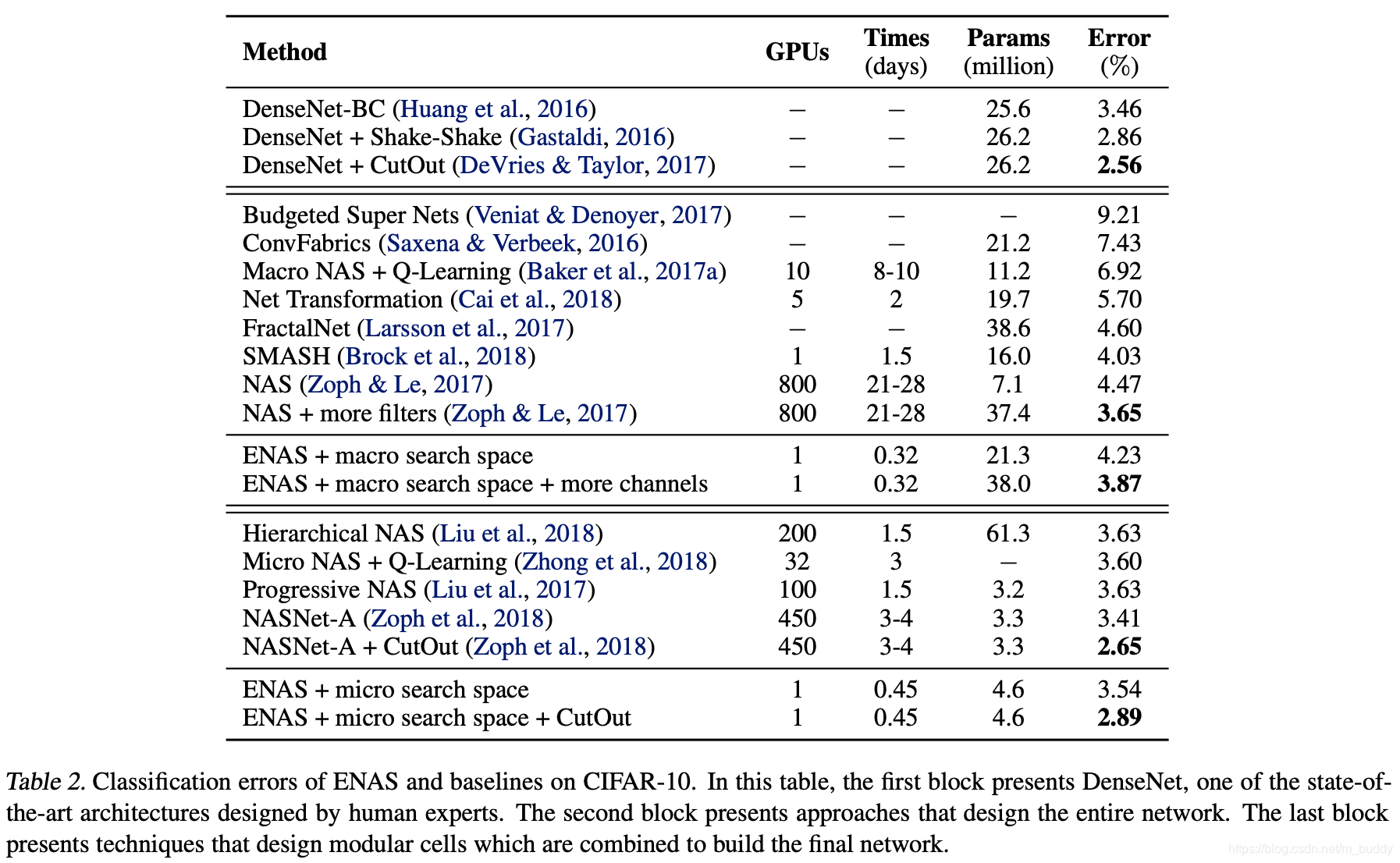
CIFAR-10数据集:
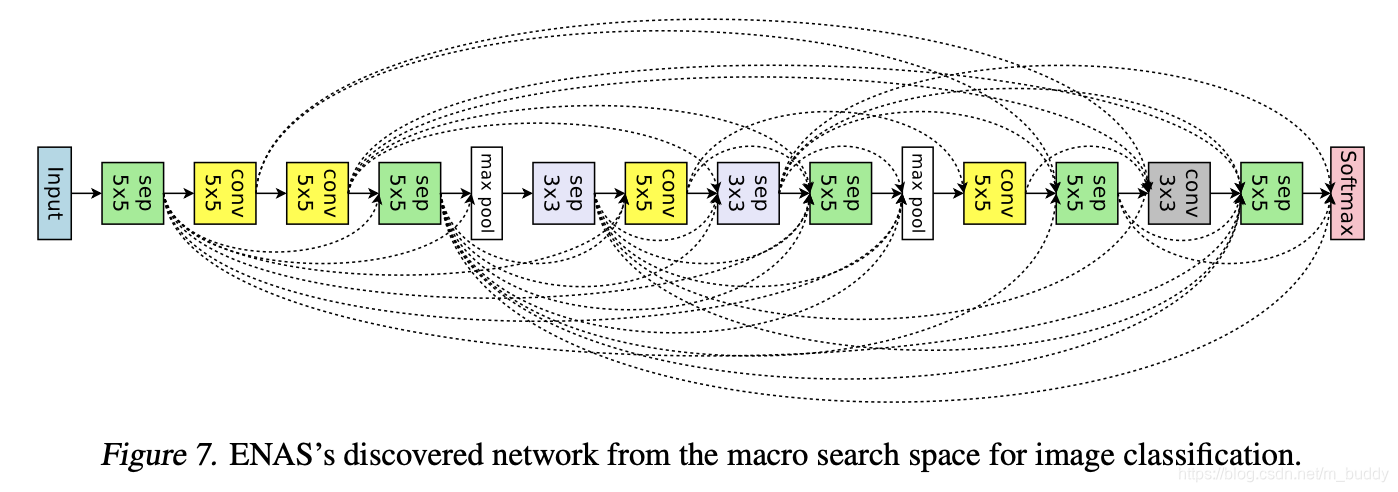
搜索结果的可视化展示: