shuffle寻址图
shuffle文件寻址基础知识
MapOutputTracker
spark架构中的一个主从模块
Driver端主对象MapOutputTrackerMaster
Executor端从对象MapOutputTrackerWorker
BlockManager
也是spark架构中的一个模块,也是主从架构
Driver端主对象 BlockManagerMaster
Executor端BlockManagerWorker
无论driver端还是worker端BlockManager端都有四个对象
① DiskStore:负责磁盘的管理。
② MemoryStore:负责内存的管理。
③ ConnectionManager:负责连接其他的 BlockManagerWorker。
④ BlockTransferService:负责数据的传输。
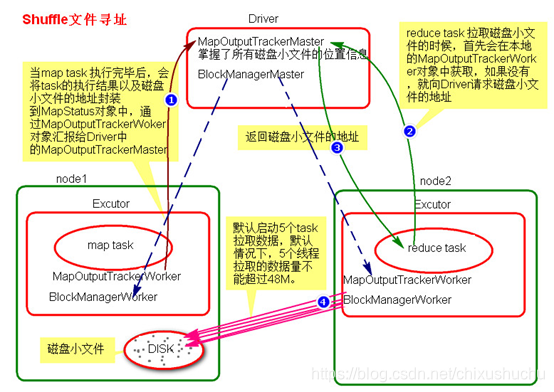
shuffle文件寻址流程
- map task执行过程,会将task的执行情况和磁盘小文件地址封装到MapStatus对象中,通过MapOutPutTrackerWorker对象向Driver端的MapOutPutTrackerMaster汇报 Driver端就掌握了所有哦磁盘小文件地址
- reduce task执行之前,会通过Executor中MapOutPutTrackerWorker向Driver端的MapOutPutTrackerMaster获取磁盘小文件地址值
- 获取到磁盘小文件地址以后会通过BlockManager中的ConnectionManager连接数据所在节点ConnectionManager,然后通过BlockTransferService进行数据的传输。
- BlockTransferService默认启动5个task去节点拉取数据。默认情况下,5个task拉取数据量不能超过48M。
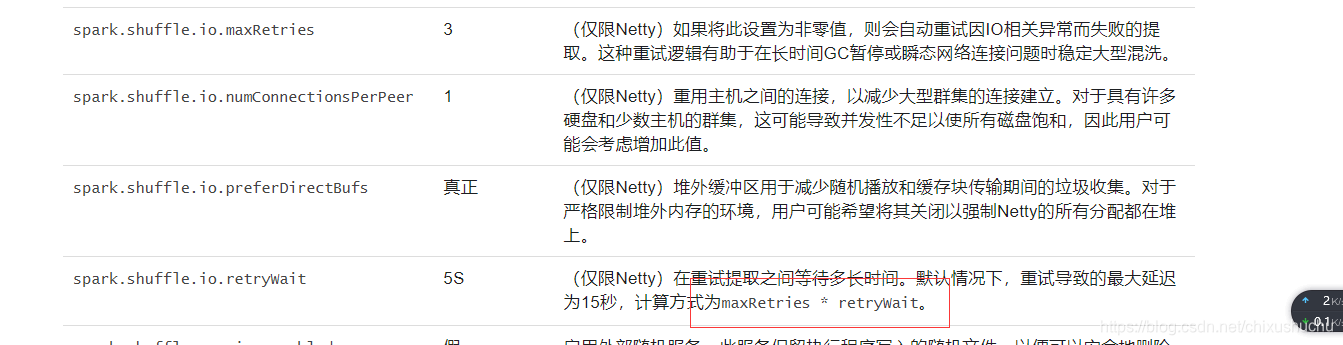
官网参数
如何调节参数
根据以上分析 在拉取数据过程中如果小文件所在executor正好在执行GC (minor GC或者 full GC)总之一旦发生GC那么BlockManager也就结束了,无法进行网络传输数据,如果一直无法拉取 可能会出现shuffle file not found 但是,可能下一个stage又重新提交了stage或task以后,再执行就没有问题了,因为可能第二次就没有碰到JVM在gc了。
那么可以适当调大参数
spark.shuffle.io.maxRetries 60
spark.shuffle.io.retryWait 60s
最多可以忍受1个小时没有拉取到shuffle file。只是去设置一个最大的可能的值。full gc不可能1个小时都没结束吧。
这样呢,就可以尽量避免因为gc导致的shuffle file not found,无法拉取到的问题