错误的持久化使用方式:
usersRDD,想要对这个RDD做一个cache,希望能够在后面多次使用这个RDD的时候,不用反复重新计算RDD;可以直接使用通过各个节点上的executor的BlockManager管理的内存 / 磁盘上的数据,避免重新反复计算RDD。
usersRDD.cache()
usersRDD.count()
usersRDD.take()
上面这种方式,不要说会不会生效了,实际上是会报错的。会报什么错误呢?会报一大堆file not found的错误。
正确的持久化使用方式:
usersRDD
usersRDD = usersRDD.cache()
val cachedUsersRDD = usersRDD.cache()
之后再去使用usersRDD,或者cachedUsersRDD,就可以了。就不会报错了。所以说,这个是咱们的持久化的正确的使用方式。
持久化,大多数时候,都是会正常工作的。但是就怕,有些时候,会出现意外。
比如说,缓存在内存中的数据,可能莫名其妙就丢失掉了。
或者说,存储在磁盘文件中的数据,莫名其妙就没了,文件被误删了。
出现上述情况的时候,接下来,如果要对这个RDD执行某些操作,可能会发现RDD的某个partition找不到了。
对消失的partition重新计算,计算完以后再缓存和使用。
有些时候,计算某个RDD,可能是极其耗时的。可能RDD之前有大量的父RDD。那么如果你要重新计算一个partition,可能要重新计算之前所有的父RDD对应的partition。
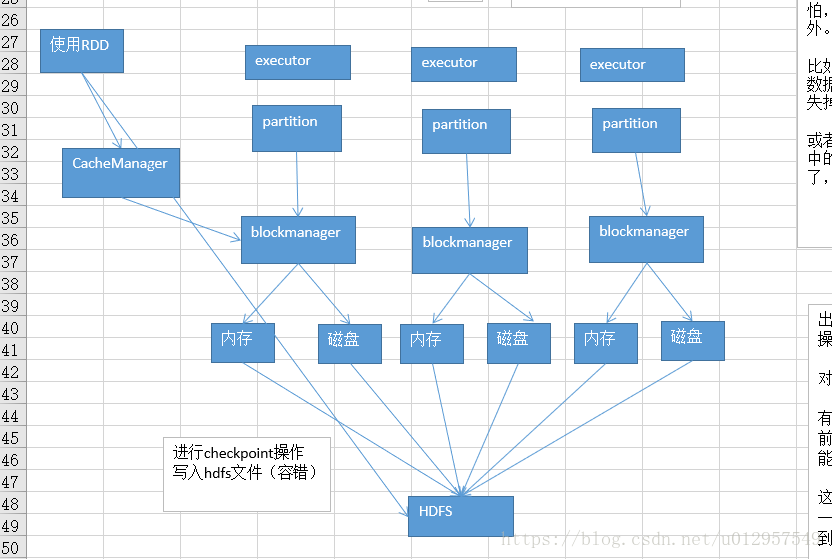
这种情况下,就可以选择对这个RDD进行checkpoint,以防万一。进行checkpoint,就是说,会将RDD的数据,持久化一份到容错的文件系统上(比如hdfs)。
在对这个RDD进行计算的时候,如果发现它的缓存数据不见了。优先就是先找一下有没有checkpoint数据(到hdfs上面去找)。如果有的话,就使用checkpoint数据了。不至于说是去重新计算。
checkpoint,其实就是可以作为是cache的一个备胎。如果cache失效了,checkpoint就可以上来使用了。
checkpoint有利有弊,利在于,提高了spark作业的可靠性,一旦发生问题,还是很可靠的,不用重新计算大量的rdd;但是弊在于,进行checkpoint操作的时候,也就是将rdd数据写入hdfs中的时候,还是会消耗性能的。
checkpoint,用性能换可靠性。
出现上述情况的时候,接下来,如果要对这个RDD执行某些操作,可能会发现RDD的某个partition找不到了。
对消失的partition重新计算,计算完以后再缓存和使用。
有些时候,计算某个RDD,可能是极其耗时的。可能RDD之前有大量的父RDD。那么如果你要重新计算一个partition,可能要重新计算之前所有的父RDD对应的partition。
这种情况下,就可以选择对这个RDD进行checkpoint,以防万一。进行checkpoint,就是说,会将RDD的数据,持久化一份到容错的文件系统上(比如hdfs)。
在对这个RDD进行计算的时候,如果发现它的缓存数据不见了。优先就是先找一下有没有checkpoint数据(到hdfs上面去找)。如果有的话,就使用checkpoint数据了。不至于说是去重新计算。
checkpoint,其实就是可以作为是cache的一个备胎。如果cache失效了,checkpoint就可以上来使用了。
checkpoint有利有弊,利在于,提高了spark作业的可靠性,一旦发生问题,还是很可靠的,不用重新计算大量的rdd;但是弊在于,进行checkpoint操作的时候,也就是将rdd数据写入hdfs中的时候,还是会消耗性能的。
欢迎关注,更多福利
