文章目录
ShutdownHook导致Spark Driver OOM
问题发现和定位
线上有个Spark程序在跑一天批次数据的时候没有问题,但是运行多天的跑批时内存溢出。先把Heap Dump出来看一下发现出现大量Netty分配的Heap内存空间没有被释放,发现SparkSession对象被没有GC。

程序为了不影响多日不同程序之间的相互影响,所以程序有不停的新的实例化SparkSession再关闭。检查关闭SparkSession代码, ThreadLocal 变量确定已经被remove了。
// 项目清理SparkSession代码
def stop() {
logDebug("Clear SparkSession and SparkContext")
if (sqlContext != null) {
sqlContext = null
}
if (spark != null) {
spark.stop()
spark = null
}
SparkSession.clearActiveSession
}
// SparkSession 代码
/** The active SparkSession for the current thread. */
private val activeThreadSession = new InheritableThreadLocal[SparkSession]
/**
* Clears the active SparkSession for current thread. Subsequent calls to getOrCreate will
* return the first created context instead of a thread-local override.
*
* @since 2.0.0
*/
def clearActiveSession(): Unit = {
activeThreadSession.remove()
}
回头再次检查,分析Paths from GC Root,发现两个奇怪点:一是这个引用关系是用 ShutdownHookManager的内部类的一个线程引用出来的,不是用户启动线程引用,也不是Spark内部线程引用。二是该线程的状态为NEW。
inheritableThreadLocals of org.apache.hive.common.util.ShutdownHookManager$1 "Thread-28" tid=68 [NEW] 94184 120
Hive的ShutdownHookManager 是一个工具类,该类通过静态方法向JVM(java.lang.ApplicationShutdownHooks)注册了一个注册了一个Shutdown hook线程。在该hook中允许用户添加一些用于执行清理工作的线程,在系统退出时根据注册的优先级依次执行。
// org.apache.hive.common.util.ShutdownHookManager
static {
MGR.addShutdownHookInternal(DELETE_ON_EXIT_HOOK, -1);
Runtime.getRuntime().addShutdownHook(
new Thread() {
@Override
public void run() {
MGR.shutdownInProgress.set(true);
for (Runnable hook : getShutdownHooksInOrder()) {
try {
hook.run();
} catch (Throwable ex) {
LOG.warn("ShutdownHook '" + hook.getClass().getSimpleName() +
"' failed, " + ex.toString(), ex);
}
}
}
}
);
}
问题定位了:
- 用户线程线程实例化SparkSession。
SparkSession对象被保存到当前线程的activeThreadSession对象中。- 程序实例化新的ClassLoader对象并加载到
org.apache.hive.common.util.ShutdownHookManager类。 ShutdownHookManager类执行静态代码,实例化清理线程,并注册到系统。该线程同时继承父线程的activeThreadSession对象。- 用户关闭SparkSession对象引用,
ShutdownHookManager类中的hook线程保持SparkSession对象引用,导致内存溢出。
解决办法
SparkSession类的增加一个InheritableThreadLocal对象来引用SparkSession,这样可以方便的在程序的不同地方,不同线程获取到SparkSession对象,并进行相关操作。但是导致这个Memory Leak实在有些尴尬。
尝试了修改Spark代码在每次使用ClassLoader加载org.apache.hive.common.util.ShutdownHookManager 类时,不把SparkSession对象传递到子线程中,结果发现行不通,因为在Hive的代码中也会生成很多新的ClassLoader对象,并重新加载org.apache.hive.common.util.ShutdownHookManager 类,此时相对于Spark系统来说,已经不可控了。
直接在ShutdownHookManager上想办法吧,通过反射清理掉所有注册的hook线程所有继承的ThreadLocal对象,系统恢复正常。
/** Cleans up and shuts down the Spark SQL environments. */
def stop() {
logDebug("Clear SparkSession and SparkContext")
catalogEventListener.stop()
if (sqlContext != null) {
sqlContext = null
}
if (spark != null) {
spark.stop()
spark = null
}
SparkSession.clearActiveSession
val clazz = Class.forName("java.lang.ApplicationShutdownHooks")
val field = clazz.getDeclaredField("hooks")
field.setAccessible(true)
val inheritableThreadLocalsField = classOf[Thread].getDeclaredField("inheritableThreadLocals")
inheritableThreadLocalsField.setAccessible(true)
val hooks = field.get(clazz).asInstanceOf[java.util.IdentityHashMap[Thread, Thread]].asScala
hooks.keys.map(inheritableThreadLocalsField.set(_, null))
}
FileSourceScanExec 进行Parquet文件Split策略有问题
问题描述:
一个十几M的parqeut文件在线上会被切分为好几个Task同时运行,运行的时候只有其中一个Task实际读了文件,其余的Task都是读了空文件。
原因: 因为虽然我们在对parquet文件进行了切割,在读取parqeut文件的时候会根据split读取的start和length去获取对应的RowGroup,如果RowGroup的middle位置可以被读取就读取出来,否则读取的是空数据。
Debug日志
21:16:10.180 main INFO org.apache.spark.sql.execution.FileSourceScanExec: Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.
21:16:10.180 main INFO org.apache.spark.sql.execution.FileSourceScanExec: defaultMaxSplitBytes : 134217728
21:16:10.180 main INFO org.apache.spark.sql.execution.FileSourceScanExec: openCostInBytes : 4194304
21:16:10.180 main INFO org.apache.spark.sql.execution.FileSourceScanExec: default.parallelism : None
21:16:10.180 main INFO org.apache.spark.sql.execution.FileSourceScanExec: defaultParallelism : 53
21:16:10.180 main INFO org.apache.spark.sql.execution.FileSourceScanExec: totalBytes : 98047688
21:16:10.180 main INFO org.apache.spark.sql.execution.FileSourceScanExec: bytesPerCore : 1849956
21:16:10.180 main INFO org.apache.spark.sql.execution.FileSourceScanExec: maxSplitBytes : 4194304
21:16:10.180 main INFO org.apache.spark.sql.execution.FileSourceScanExec: splitFiles : 4194304
21:16:10.189 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(0,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200606/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 0-4194304, partition values: [20200606]))
21:16:10.189 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(1,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200606/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 4194304-8388608, partition values: [20200606]))
21:16:10.189 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(2,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200606/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 8388608-12582912, partition values: [20200606]))
21:16:10.189 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(3,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200607/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 0-4194304, partition values: [20200607]))
21:16:10.189 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(4,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200607/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 4194304-8388608, partition values: [20200607]))
21:16:10.189 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(5,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200608/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 0-4194304, partition values: [20200608]))
21:16:10.189 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(6,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200608/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 4194304-8388608, partition values: [20200608]))
21:16:10.189 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(7,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200608/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 8388608-12582912, partition values: [20200608]))
21:16:10.189 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(8,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200608/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 12582912-16777216, partition values: [20200608]))
21:16:10.189 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(9,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200609/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 0-4194304, partition values: [20200609]))
21:16:10.189 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(10,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200609/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 4194304-8388608, partition values: [20200609]))
21:16:10.190 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(11,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200609/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 8388608-12582912, partition values: [20200609]))
21:16:10.190 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(12,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200609/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 12582912-16777216, partition values: [20200609]))
21:16:10.190 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(13,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200610/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 0-4194304, partition values: [20200610]))
21:16:10.190 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(14,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200610/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 4194304-8388608, partition values: [20200610]))
21:16:10.190 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(15,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200610/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 8388608-12582912, partition values: [20200610]))
21:16:10.190 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(16,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200610/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 12582912-16777216, partition values: [20200610]))
21:16:10.190 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(17,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200608/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 16777216-19269825, partition values: [20200608]))
21:16:10.190 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(18,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200609/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 16777216-19067647, partition values: [20200609]))
21:16:10.190 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(19,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200606/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 12582912-13440409, partition values: [20200606]))
21:16:10.190 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(20,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200610/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 16777216-16864703, partition values: [20200610]))
21:16:10.190 main INFO org.apache.spark.sql.execution.FileSourceScanExec: generate new FilePartition : FilePartition(21,WrappedArray(path: hdfs://nameservice/data/hive/pdd/pdd_bot_marketing/dws_group_reminder_detail/dt=20200607/part-00000-5c7f7d21-a16a-4aad-893c-eb9bb4bdcdad.c000, range: 8388608-8433584, partition values: [20200607]))
相关排查日志
动态插入分区表任务执行失败失败
错误分析
这是一个动态插入分区表的sql job,第一个Task运行失败后,第二个task启动的时候发现第一个task的输出文件仍然存在,task attempt启动失败,任务直接退出。
根本原因还是动态分区插入job的task 输出文件的提交控制有问题,已经给社区反馈响应的Issue。SPARK-32395
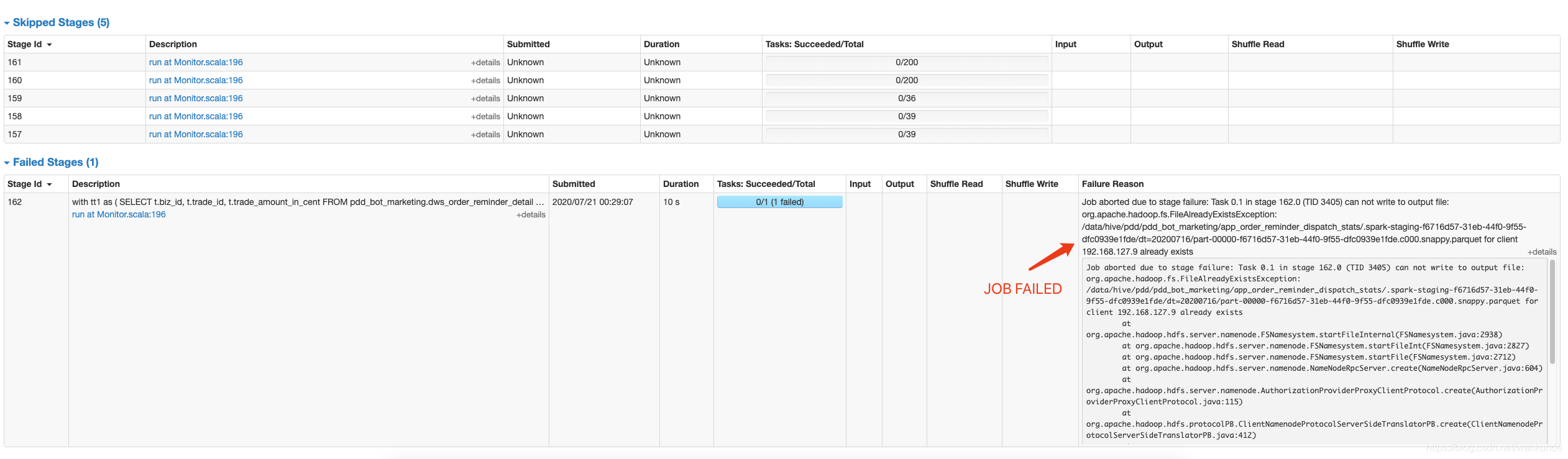

task attempt1 日志
00:29:10.344 Executor task launch worker for task 3404 INFO org.apache.hadoop.io.compress.CodecPool: Got brand-new compressor [.snappy]
00:29:12.192 Executor task launch worker for task 3404 INFO org.apache.parquet.hadoop.InternalParquetRecordWriter: Flushing mem columnStore to file. allocated memory: 29701024
00:29:12.474 SIGTERM handler ERROR org.apache.spark.executor.CoarseGrainedExecutorBackend: RECEIVED SIGNAL TERM
00:29:12.589 Executor task launch worker for task 3404 ERROR org.apache.spark.util.Utils: Aborting task
java.io.IOException: can not write PageHeader(type:DICTIONARY_PAGE, uncompressed_page_size:7498, compressed_page_size:5643, dictionary_page_header:DictionaryPageHeader(num_values:625, encoding:PLAIN_DICTIONARY))
at org.apache.parquet.format.Util.write(Util.java:224)
at org.apache.parquet.format.Util.writePageHeader(Util.java:61)
at org.apache.parquet.format.converter.ParquetMetadataConverter.writeDictionaryPageHeader(ParquetMetadataConverter.java:1125)
at org.apache.parquet.hadoop.ParquetFileWriter.writeDictionaryPage(ParquetFileWriter.java:336)
at org.apache.parquet.hadoop.ColumnChunkPageWriteStore$ColumnChunkPageWriter.writeToFileWriter(ColumnChunkPageWriteStore.java:198)
task attempt2 日志
00:29:16.512 Executor task launch worker for task 3405 ERROR org.apache.spark.util.Utils: Aborting task
org.apache.hadoop.fs.FileAlreadyExistsException: /data/hive/pdd/pdd_bot_marketing/app_order_reminder_dispatch_stats/.spark-staging-f6716d57-31eb-44f0-9f55-dfc0939e1fde/dt=20200716/part-00000-f6716d57-31eb-44f0-9f55-dfc0939e1fde.c000.snappy.parquet for client 192.168.127.9 already exists
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInternal(FSNamesystem.java:2938)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2827)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFile(FSNamesystem.java:2712)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.create(NameNodeRpcServer.java:604)
at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.create(AuthorizationProviderProxyClientProtocol.java:115)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.create(ClientNamenodeProtocolServerSideTranslatorPB.java:412)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2226)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2222)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2220)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:106)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:73)
at org.apache.hadoop.hdfs.DFSOutputStream.newStreamForCreate(DFSOutputStream.java:2134)
at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1781)
at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1705)
at org.apache.hadoop.hdfs.DistributedFileSystem$7.doCall(DistributedFileSystem.java:437)
at org.apache.hadoop.hdfs.DistributedFileSystem$7.doCall(DistributedFileSystem.java:433)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:433)
at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:374)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:926)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:907)
at org.apache.parquet.hadoop.util.HadoopOutputFile.create(HadoopOutputFile.java:74)
at org.apache.parquet.hadoop.ParquetFileWriter.<init>(ParquetFileWriter.java:248)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:390)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:349)
at org.apache.spark.sql.execution.datasources.parquet.ParquetOutputWriter.<init>(ParquetOutputWriter.scala:37)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$$anon$1.newInstance(ParquetFileFormat.scala:150)
at org.apache.spark.sql.execution.datasources.DynamicPartitionDataWriter.newOutputWriter(FileFormatDataWriter.scala:241)
at org.apache.spark.sql.execution.datasources.DynamicPartitionDataWriter.write(FileFormatDataWriter.scala:262)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$executeTask$1(FileFormatWriter.scala:273)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1411)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:281)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$write$15(FileFormatWriter.scala:205)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:127)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:444)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:447)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
.....
; not retrying
00:29:16.583 main ERROR FileFormatWriter: Aborting job 6de09c5c-b425-4d01-b5c0-1aa0a6e3f58e.
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0.1 in stage 162.0 (TID 3405) can not write to output file: org.apache.hadoop.fs.FileAlreadyExistsException: /data/hive/pdd/pdd_bot_marketing/app_order_reminder_dispatch_stats/.spark-staging-f6716d57-31eb-44f0-9f55-dfc0939e1fde/dt=20200716/part-00000-f6716d57-31eb-44f0-9f55-dfc0939e1fde.c000.snappy.parquet for client 192.168.127.9 already exists
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInternal(FSNamesystem.java:2938)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2827)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFile(FSNamesystem.java:2712)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.create(NameNodeRpcServer.java:604)
at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.create(AuthorizationProviderProxyClientProtocol.java:115)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.create(ClientNamenodeProtocolServerSideTranslatorPB.java:412)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2226)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2222)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2220)
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2023)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:1972)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:1971)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1971)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:950)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:950)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:950)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2203)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2152)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2203)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2152)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2141)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:752)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2093)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:195)
at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:178)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:108)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:106)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.executeCollect(commands.scala:120)
at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:229)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3616)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:100)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:160)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:87)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3614)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:229)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:100)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:97)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:606)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:601)
at org.apache.spark.sql.SparkSqlRunner.run(SparkSqlRunner.scala:34)
at com.leyan.insight.Monitor$.executeSql$1(Monitor.scala:196)
at com.leyan.insight.Monitor$.$anonfun$main$20(Monitor.scala:204)
at com.leyan.insight.Monitor$.$anonfun$main$20$adapted(Monitor.scala:183)
at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198)
at com.leyan.insight.Monitor$.$anonfun$main$13(Monitor.scala:183)
at com.leyan.insight.Monitor$.$anonfun$main$13$adapted(Monitor.scala:122)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)