一、算子返回为null
问题
在有些算子函数里,我们都需要有返回值。但是,有些可能不需要返回值,但是这时候不能直接返回null,返回null将会导致错误
Scala.Math(NULL) //异常
解决方法
- 如果不想有返回值,可以在返回的时候,返回一些特殊的值,比如“-999”
- 获取到rdd之后,对rdd进行filter操作,如果数据是-999的,可以返回false,进行过滤掉
- filter之后,使用coalesce算子压缩rdd的partition数量,让各个partition数据比较紧凑。提升性能。
return actionRDD.mapToPair(new PairFunction<Row, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Row> call(Row row) throws Exception {
return new Tuple2<String, Row>("-999", RowFactory.createRow("-999"));
}
});
二、持久化使用方式
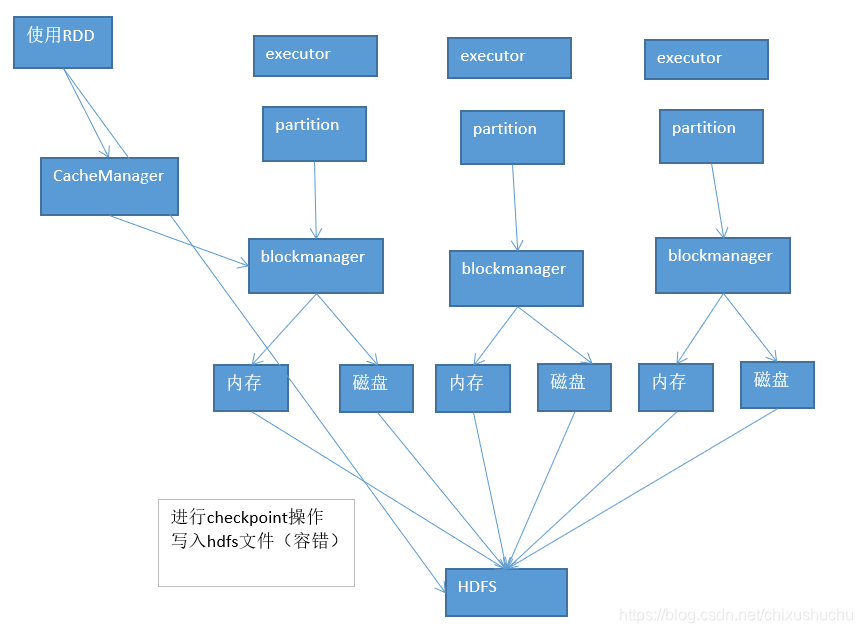
有时候希望重复使用一个rdd,不用反复计算rdd,可以直接使用通过各个节点上的executor 的BlockManager管理内存、磁盘数据
但是使用rdd持久化应该是 像下面这样
sessionid2actionRDD = sessionid2actionRDD.persist(StorageLevel.MEMORY_ONLY());
如果直接像下面
sessionid2actionRDD.persist(StorageLevel.MEMORY_ONLY());
会报错,file not found错误
三、checkpoint
持久化,一般情况可以正常工作,但是可能出现意外,缓存在内存中的数据莫名其妙丢失,或者存储在磁盘文件中的数据,莫名其妙被删除。
但是有些rdd计算可能非常耗时,rdd之前有大量的父rdd,如果重新计算一个partition,可能就需要重新计算之前所有的父rdd对应的partition,这种情况就可以对rdd进行checkpoint,以防万一。进行checkpoint,就是说,会将rdd的数据,持久化一份到容错文件系统上(比如hdfs)。在对rdd进行计算的时候,如果发现缓存数据不见了,就会去checkpoint目录查找数据,如果有的话,就直接使用避免重新计算。
这么理解,checkpoint其实算是 cache的一个备用。如果cache失效了,checkpoint就可以派上用场。
好处是:提高了spark作业的可靠性,发生问题,不用重新计算大量的rdd;
坏处是:进行checkpoint操作的时候,将rdd数据写入hdfs中的时候,很耗费性能。
checkpoint原理
- 在代码中,用sparkContext,设置一个checkpoint目录,比如hdfs目录
JavaSparkContext sc = new JavaSparkContext(conf);
// sc.checkpointFile("hdfs://");
- 在代码中,对需要进行checkpoint的rdd,执行rdd.checkpoint()
sessionid2actionRDD = sessionid2actionRDD.persist(StorageLevel.MEMORY_ONLY());
// sessionid2actionRDD.checkpoint();
- RDDCheckpointData(spark 内部的api) 接管你的RDD,会标记为marked for checkpoint,准备进行checkpoint
- job运行完之后,会调用一个finalRDD.doCheckpoint()方法,顺着rdd lineage,回溯扫描,发现有标记为checkpoint的rdd,就会进行二次标记,inProgressCheckpoint,正在接受checkpoint操作
- job执行完后,就会启动一个内部新的rdd,去将标记为inProgressCheckpoint的rdd的数据,都写入hdfs文件中。(备注,如果rdd之前cache过,会直接从缓存中获取数据,写入hdfs中;如果没有cache过,那么就会重新计算一遍这个rdd,再checkpoint)
- 将checkpoint过的rdd之前的依赖rdd,改成一个CheckpointRDD*,强制改变你的rdd的lineage。后面如果rdd的cache数据获取失败,直接会通过它的上游CheckpointRDD,去容错的文件系统,比如hdfs,中,获取checkpoint的数据。