在第一篇文章中,我们介绍了如何用上下文无关文法描述一种语言的语法,和如何使用推导和规约构造一棵语法分析树,以及如何对文法进行转换使之能够更适用于语法分析。在本篇文章中,我们将介绍如何使用自顶向下的方法进行语法分析,进一步的,我们将介绍一种更高效的预测分析方法。
文法&约定
为了下文需要和减少重复,我们先给出在下文中用到的一个表达式文法和一些符号约定。
下面是需要用到的表达式文法,称其为文法G:
E→TE'
E'→+TE'|ε
T→FT'
T'→*FT'|ε
F→(E)|id
1
2
3
4
5
同样的,我们在此给出每个下文出现的符号的约定:
大写字母:表示非终结符号,如A、B、C等;
小写字母:表示终结符号,如a、b、c等;
希腊字母:表示由终结符号和非终结符号组成的串或空串,如α、β、γ、ω等;
结束标记:把符号$作为结束标记,如输入结束、栈为空等;
空串:用ε表示长度为0的串,即空串;
语言:用L(G)表示文法G可以生成的所有串的集合,即文法G代表的语言。
自顶向下的语法分析
自顶向下的语法分析可以看作为一个输入的词素序列构造语法分析树的问题,它从语法分析树的根结点开始,按照前序遍历顺序创建这棵语法分析树的各个结点。实际上,前序遍历的创建各个结点的过程就是一个最左推导过程。
使用自顶向下方法构造一棵语法分析树的关键问题是,每次必须确定应用哪一个产生式对一个非终结符号进行推导。对一组产生式和一个非终结符号A,如果只有一个形如A→α的产生式,那么每次对A的推导只需使用这一个产生式;但是,如果有多个左部为A的产生式如A→α|β|γ,那么每次对A的推导就不得不决定使用哪一个产生式了。
递归下降的语法分析
递归下降的语法分析是自顶向下语法分析的通用方法,这种方法可能需要进行回溯。
考虑文法:
S→cAd
A→ab|a
1
2
我们尝试对串cad构造语法分析树:
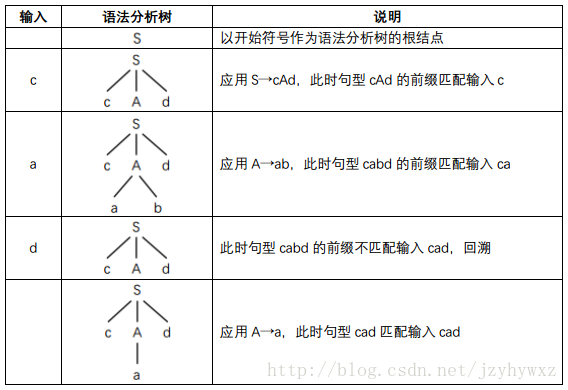
可以发现,在第一次对非终结符号A进行推导后,得到的语法分析树的句子cabd不匹配输入cad,因此需要进行回溯;在第二次对A进行推导后,得到的语法分析树的句子cad匹配输入cad,到此,成功构造了串cad的语法分析树,因此我们说串cad是符合该文法的。
预测分析技术
递归下降的语法分析方法是不高效的。如果一个文法有大量的以同一个非终结符号作为左部的产生式,在使用递归下降的语法分析方法构造一棵语法分析树时,就可能进行大量的回溯。如果我们能够唯一确定每个非终结符号在每次推导时使用的产生式,那么就可以高效的构造语法分析树。
FIRST和FOLLOW
自顶向下语法分析器的构造可以使用和文法相关的两个函数FIRST和FOLLOW来实现。在自顶向下语法分析过程中,FIRST和FOLLOW使我们可以根据下一个输入符号选择应用哪个产生式。
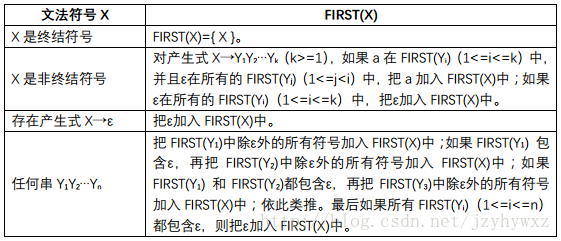
FIRST(α)是可以从α推导得到的串的第一个符号的集合,如果可以从α推导出ε,那么ε也在FIRST(α)中。
计算各个文法符号X的FIRST(X)时,不断应用下列规则,直到没有新的终结符号或ε被加入FIRST(X)中为止:
对于非终结符号A,FOLLOW(A)被定义为可能在某些句型中紧跟在A右边的终结符号的集合,如果A是某些句型的最右符号,那么$也在FOLLOW(A)中。
计算各个非终结符号B的FOLLOW(B)时,不断应用下列规则,直到没有新的终结符号被加入FOLLOW(B)中为止:
对文法G应用上述规则得到的FIRST和FOLLOW集合分别为:
预测分析表
上一节介绍了如何计算一个文法的FIRST和FOLLOW集合,但是,我们还不清楚FIRST和FOLLOW集合对构建语法分析树有什么作用。本节将如何用FIRST和FOLLOW集合构造预测分析表,这张表将帮助我们实现无回溯的递归下降的语法分析。
为了消除递归下降的语法分析过程中的回溯,我们必须确定对每个非终结符号应用哪一个产生式而不是一次次地尝试。假设有一组产生式A→α|β,其中α、β的首符号不同并且α、β不能都生成空串ε,对输入符号a,我们必须确定应用哪一个产生式:
如果a是α的首符号,那么可以应用产生式A→α;如果a是β的首符号,那么可以应用产生式A→β;
如果α可能生成空串ε,并且a可能紧跟在A之后,那么也可以应用产生式A→α;如果β可能生成空串ε,并且a可能紧跟在A之后,那么也可以应用产生式A→β;
如果前两步都没有找到匹配的产生式,那么从A推导得到的串的前缀都不能匹配a。
实际上,步骤1就是FIRST(α)或者FIRST(β),步骤2就是FOLLOW(A),步骤3报告了一个语法错误,经过上述步骤后,我们可以唯一确定一个产生式(或者发现一个语法错误)。到此,我们知道了如何根据FIRST和FOLLOW集合实现无回溯的递归下降的语法分析。
为了方便我们查看每对非终结符号和输入符号应该应用哪个产生式,我们把FIRST和FOLLOW集合“组合”成一张表,这张表记为预测分析表M[A, a],它的行头a表示所有输入符号和终结符号$,列头A表示所有非终结符号,表项是零个或多个产生式:
对于FIRST(α)中的每个非终结符号a,将A→α加入到M[A, a]中;
如果ε在FIRST(α)中,那么对于FOLLOW(A)中的每个终结符号b,将A→α加入到M[A, b]中;如果ε在FIRST(α)中且$在FOLLOW(A)中,也将A→α加入到M[A, $]中。
完成上面的操作后,如果M[A, a]中没有产生式,那么M[A, a]表示一个语法错误。
注意,上面的规则适用于任何文法,但是左递归和二义性的文法构建的预测分析表的某些表项可能有不止一个产生式。
对文法G应用上面的规则,得到其预测分析表如下:
LL(k)文法
对于某些文法,我们可以构造出向前看k个输入符号的预测分析器,这类文法也称为LL(k)文法类,其中,第一个“L”表示从左到右扫描输入,第二个“L”表示产生最左推导,“k”表示在每一步中只需要向前看k个输入符号来决定语法分析动作。通常情况下,我们只需要向前看一个符号,因此这里我们只介绍LL(1)文法。
一个文法是LL(1)的,当且仅当该文法不是左递归和二义性的。LL(1)文法的预测分析表的每个表项最多只有一个产生式,正因如此,我们才能唯一确定对每对非终结符号和输入符号应用的产生式。
表驱动的预测语法分析
该节的内容实质上和上文的预测分析技术一样,只不过更加系统的阐述了如何使用预测分析技术从一个输入串得到一个最左推导。
一个由分析表驱动的语法分析器由输入缓冲区、文法符号栈、预测分析表和结果输出流组成,如下图所示:
其中的预测分析过程如下:
对文法G,在上文已经得到了其预测分析表,考虑输入串id+id*id,其预测分析过程如下:
上图中栈的栈顶在左边,把输出组合起来就得到串id+id*id的一个最左推导。
---------------------
作者:jzyhywxz
来源:CSDN
原文:https://blog.csdn.net/jzyhywxz/article/details/78404558
版权声明:本文为博主原创文章,转载请附上博文链接!