自顶向上分析方法
1 思想
简单来说就是试图从输入符号串出发,将其直接作为叶子结点,然后向上构造出一棵分析树。从树根到叶子叫展开,而从叶子回树根就叫归约。所以这种方法的关键在于查找当前句型的可归约串,然后规约到非终结符,形成一个新串,再重复查找句型,归约的过程。
2 方法
2.1 优先分析法
- 简单优先分析法
规范归约:按照文法符号之间的优先关系确定当前句型的可归约串。(划重点意义不大,因为它限制了作用范围只能是简单优先文法。
- 算符优先分析法
算符文法:若产生式右边任意位置都没有连续两个或以上的非终结符出现,则称为算符文法。
算符优先文法:若算符文法G不含有\(\varepsilon\)产生式,且它的任何两个构成序对的终结符号之间最多有>、<、=三种优先关系中的一种成立,则称G是一个算符优先文法。
其实上面这些定义并没有什么卵用
2.2 LR分析方法
- 句柄:最左直接短语。也是分析树最左边的只有父子两代的子树叶结点自左至右排列形成的符号串。
- LR是一种规范规约,具体过程如下:
- 把输入符号一个一个地移进栈里,直到栈顶的符号串形成一个可归约串为止。
- 把栈顶的这个可归约串归约为产生式的左部符号,直到栈顶不再有可归约串为止。
- 重复以上移进-归约操作,直到归约到文法的开始符号。
2.3 规范规约
- 步骤:先找出当前句型的句柄,然后把句柄归约为相应产生式的左部符号,得到一个新的句型,重复此过程,最终归约到文法的开始符号。
- 形式定义:假定\(\alpha\)是文法G的一个句子,如果右句型序列\(\alpha_n,\alpha_{n-1},...,\alpha_1,\alpha_0\)满足以下两个条件,则称该序列是\(\alpha\)的一个规范归约。
1.\(\alpha_n = \alpha,\alpha_0 = S\)
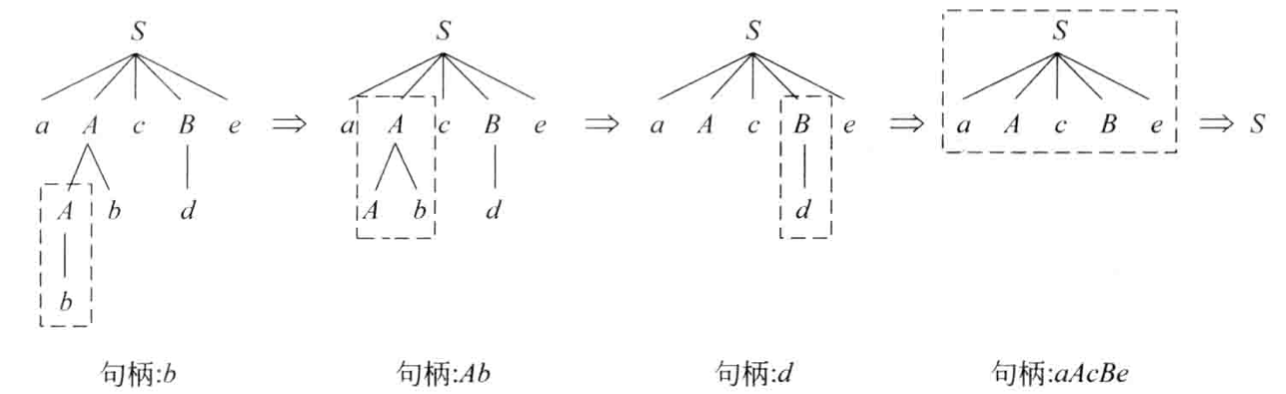
2.对任何\(i(0<i\leq n),\alpha_{n-1}\)是经过把\(\alpha_i\)的句柄替换为相应产生式的左部符号而得到的。 - 规范归约的可归约串可以描述为:若\(\alpha \beta \omega\)是一个规范句型,\(\beta\)是它的句柄,\(\alpha\)是位于\(\beta\)之前的符号串,它是在\(\beta\)之前进行归约的结果,可含有终结符和非终结符。\(\omega\)是位于\(\beta\)之后的符号串,只能有终结符号。将句柄\(\beta\)归约到它的父结点A上去。
- 下面通过一张表作为栗子看一下归约过程:
对下列文法,分析符号串\(abbcde\)
\(S\rightarrow aAcBe, A\rightarrow b|Ab, B\rightarrow d\)

3 LR分析方法
其实这里开始才是重点
3.1 LR模型和工作过程


说白了就是goto和action都是二维数组,两个角标做索引存储信息。
\(goto[S_m, A]\)表示当前的\(S_m\)状态相对于非终结符号A的后继状态。
\(action[S_m,a_i]\)和上一节讲的分析表意思差不多(没看的自行面壁补)存储的是当前状态对输入的终结符采取的分析动作,包括移进,归约,接受,出错。
突然乱入一个定义
- 活前缀:对规范句型的一个前缀,如果它不包含句柄之后的任何符号,则称该前缀为该句型的一个活前缀。比如上面那个栗子里的一个规范句型aAbcde的句柄Ab,活前缀有\(\varepsilon ,a,aA,aAb\)。
这什么沙雕定义 - 描述一下LR分析程序的算法:
贴图警告

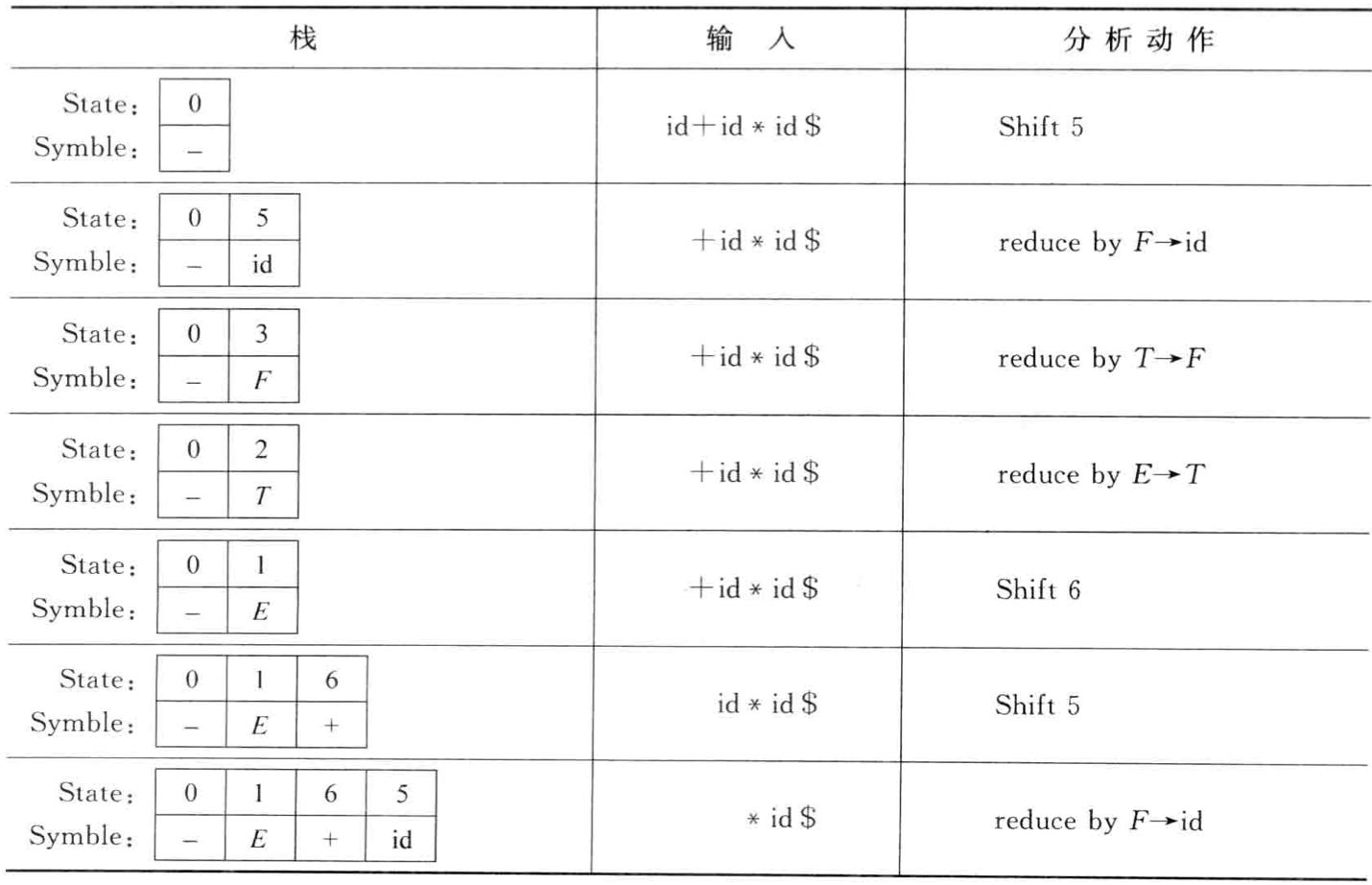
下面再举个栗子体现如何利用LR分析表来分析识别符号串的动作
分析输入符号串id+id*id,文法为:
\(E\rightarrow E+T|T,T\rightarrow T*F|F,F\rightarrow (E)|id\)


现在的问题在于如何构造LR分析表这句话是不是似曾相识呢?看出来了嘛,构造表就是考点,2333咳咳,规范点说就是为给定的文法构造一个识别它所有活前缀的DFA。不知道DFA的自行移步形式语言与自动机
3.2 LR(0)
- 引入必要定义
贴图,算了不警告了,估计习惯了



忽略定义,算法标号4.10,4.11啥的
下面敲黑板!构造文法G的LR(0)项目集规范族。

这里不想举栗子惹(突然卖萌,因为后面写DFA的时候潜移默化地融进这里的思想。疯狂暗示这里看不懂也没关系,理解掌握后面的套路就可(误
来,看一个DFA的栗子:文法 \(S\rightarrow aA|bB,A\rightarrow cA|d, B\rightarrow cB|d\)

整明白没?就是先拓展一个 \(S^'\rightarrow S\) 出来,然后给这个推导式箭头右边第一个符号前面加个点,表示现在分析的位置,然后点后面如果是非终结符,把非终结符的所有推导式加进来,在箭头后面加个点。对于新加进来的推导式,继续观察点后面是不是非终结符,需不需要再加入新的推导式。如果没有了,这就是一个项目集\(I_0\),然后对所有推导式点后面的终结符和非终结符。都牵出一条外箭头到一个新的项目集\(I_i\)里,线上写的是对应的那个符号,然后把对应的推导式的点往后移一个,作为新的推导式放入\(I_i\),之后再用\(I_0\)拓展的方法,完善\(I_i\)闭包。推导式推到点在末尾的归约状态后,该推导式不能引出新的项目集。
3.3 SLR(1)
- 引入原因:LR(0)出来的项目集如果同一个状态既有移进项(点后面是终结符),又有归约项(点后面没符号了),此时就有移进-归约冲突。若含有两个不同的归约项,则为归约-归约冲突。SLR(1)是为了解决以上冲突中的部分情况。
- 解决冲突的思想:

这个说白了,就是往后看一个,然后简单判断一下哪个推导式和这个下一个输入不矛盾。如果有冲突的两个推导式左边的那个非终结符的follow还有交集,那这种情况就没戏(官方点说,这叫不算SLR(1)文法,这个是证明文法要说的。总的来说,SLR(1)的DFA跟LR(0)看起来没啥区别,主要是人工判断一下冲突的follow集,考虑能不能解决冲突。当然不过这样也解决不了,那就引出下一种,LR(1)。
3.4 LR(1)
3.5 LALR(1)
下回再说,hhh