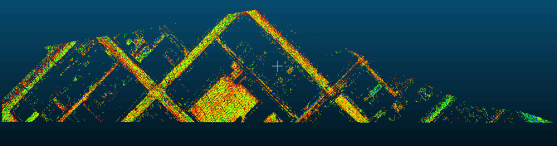
原始点云数据在CloudCompare的显示如下:

点云原始数据以及提取出的房屋道路等数据下载地址:https://download.csdn.net/download/qq_39343904/10863193
代码下载地址:https://download.csdn.net/download/qq_39343904/10863209
接着利用k-means算法提取出其中的建筑物、房屋等,代码如下:
import numpy as np
def kmean(x,k,maxtimes):
m,n = np.shape(x)
dataset = np.zeros([m,n+1])
dataset[:,:-1] = x
#middle = dataset[np.random.randint(m,size=k),:]
middle = dataset[0:3,:]
middle[:,-1] = range(1,k+1)
times = 0
oldmiddle = None
while not shouldstop(oldmiddle,middle,times,maxtimes):
print('times:',times)
print('dataset:',dataset)
print('middle:',middle)
oldmiddle = np.copy(middle)
times = times + 1
update(dataset,middle)
middle = getmiddles(dataset,k)
return dataset
def shouldstop(oldmiddle,middle,times,maxtimes):
if times > maxtimes:
return True
return np.array_equal(oldmiddle,middle)
def update(dataset,middle):
m,n =dataset.shape
for i in range(0,m):
dataset[i,-1] = getLabelFromCloestCentroid(dataset[i,:-1],middle)
def getLabelFromCloestCentroid(datasetRow,middle):
label = middle[0,-1]
minDist = np.linalg.norm(datasetRow - middle[0,:-1])
for i in range(1,middle.shape[0]):
dist = np.linalg.norm(datasetRow - middle[i,:-1])
if dist < minDist:
minDist = dist
label = middle[i,-1]
print('minDist',minDist)
print('label',label)
return label
def getmiddles(datatset,k):
result = np.zeros((k,datatset.shape[1]))
for i in range(1,k+1):
oneCluster = datatset[datatset[:,-1]==i,:-1]
result[i-1,:-1] = np.mean(oneCluster,axis=0)
result[i-1,-1] = i
return result
import numpy as np
import csv
file = open(r'全部点云数据.csv','r')
reader = csv.reader(file)
reader = list(reader)
m,n = np.shape(reader)
for i in range(0,m):
for j in range(0,4):
reader[i][j] = float(reader[i][j])
m,n = np.shape(reader)
list1 = np.zeros([m,2])
for i in range(0,m):
for j in range(2,4):
list1[i][j-2] = reader[i][j]
# x = np.vstack((a,b,c,d))
result = kmean(list1,3,10)
print('result:',result[0])
print(reader[0])
reader0 = np.zeros([m,5])
for i in range(0,m):
for j in range(0,4):
reader0[i][j] = reader[i][j]
for i in range(0,m):
reader0[i][-1] = int(result[i][-1])
print(reader0)
w1=open("1.txt","w")
w2=open("2.txt","w")
w3=open("3.txt","w")
w4=open("4.txt","w")
for i in range(m):
if(reader0[i][-1]==1):
w1.write("%s %s %s %s\n"%(reader0[i][0],reader0[i][1],reader0[i][2],reader0[i][3]))
if(reader0[i][-1]==2):
w2.write("%s %s %s %s\n" % (reader0[i][0], reader0[i][1], reader0[i][2],reader0[i][3]))
if (reader0[i][-1] ==3):
w3.write("%s %s %s %s\n" % (reader0[i][0], reader0[i][1], reader0[i][2],reader0[i][3]))
if (reader0[i][-1] == 4):
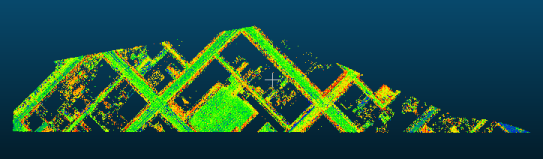
w4.write("%s %s %s %s\n" % (reader0[i][0], reader0[i][1], reader0[i][2],reader0[i][3]))以上代码将k值设置为4,也就是将点云聚成4类。输出为4个txt数据,加载进软件,效果图如下,分别是提取的道路,建筑物:

还是利用上述代码,将道路数据放进代码,将K设置为2,可以将道路数据聚类为两类,提取出道路的主干和边界: