利用K-means算法进行客户分群
在数据科学和机器学习领域,K-means聚类是一种常用的无监督学习方法,用于将数据分成预定义数量的群体。在这个例子中,我们将使用K-means算法对一个简化的销售数据集进行客户分群,以便更好地了解不同群体的消费行为。
1. 导入库和生成模拟数据
# 导入必要的库
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib
matplotlib.use('TkAgg') # 选择TkAgg或其他合适的后端
import matplotlib.pyplot as plt
# 生成模拟销售数据集
data = {
'CustomerID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], # 客户ID
'AnnualIncome (k$)': [15, 20, 25, 30, 35, 40, 50, 60, 70, 80], # 年收入
'SpendingScore (1-100)': [39, 81, 6, 77, 40, 76, 6, 94, 3, 72] # 消费分数
}
df = pd.DataFrame(data)
2. 选择特征和应用K-means聚类
# 选择特征
X = df[['AnnualIncome (k$)', 'SpendingScore (1-100)']]
# 使用K-means聚类
kmeans = KMeans(n_clusters=3, random_state=42, n_init='auto')
df['Cluster'] = kmeans.fit_predict(X)
print(df.head())
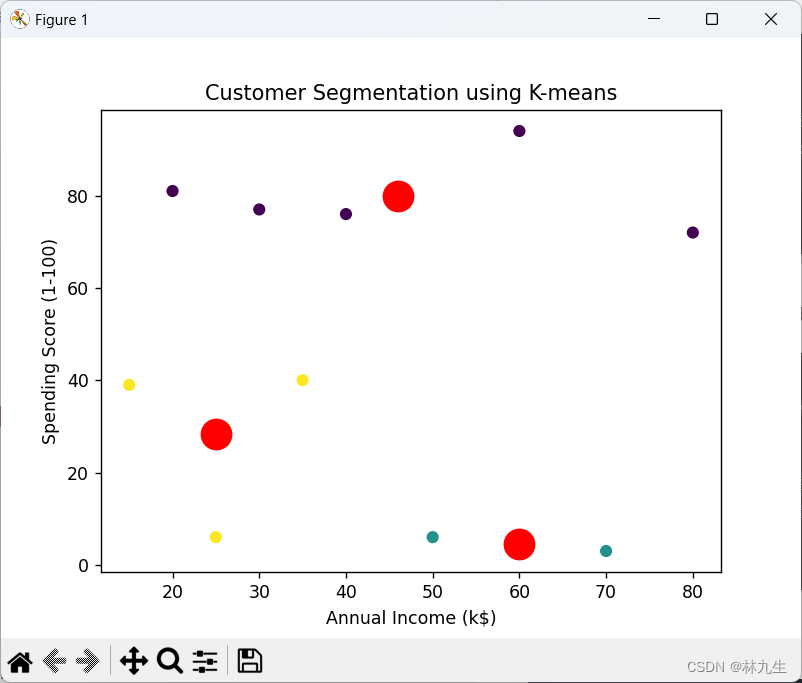
3. 可视化聚类结果
# 可视化结果
# 绘制散点图,每个簇使用不同颜色表示
plt.scatter(X['AnnualIncome (k$)'], X['SpendingScore (1-100)'], c=df['Cluster'], cmap='viridis')
# 绘制聚类中心点,用红色表示
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='red')
# 添加轴标签
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
# 添加标题
plt.title('Customer Segmentation using K-means')
# 显示图形
plt.show()
4. 分析和实际应用
在这个例子中,我们使用了一个包含顾客ID、年收入和消费得分的简化销售数据集。我们使用K-means算法将顾客分成三个群体,然后通过散点图可视化不同群体的年收入和消费得分。这个示例可能对一个零售企业有实际意义,可以根据不同顾客群体的特征制定个性化的营销策略。例如,高收入且高消费得分的群体可能是高价值顾客,可以针对他们提供更精细化的服务和促销活动。通过这样的客户分群,企业可以更好地理解其目标市场,从而优化销售和服务策略。
- 运行截图: