版权声明:===========版权所有,可随意转载,欢迎互相交流=========== https://blog.csdn.net/weixin_42446330/article/details/85215276
以下是我的学习笔记,以及总结,如有错误之处请不吝赐教。
自然语言处理发展:
在网上看了很多文章都没有屡清楚LDA、n-gram、one-hot、word embeding、word2vec等等的关系,直到看到这篇文章:参考1
要分清楚两个概念:语言模型和词的表示
- 语言模型:分为文法语言和统计语言,我们现在常说的语言模型就是统计语言,就是把语言(词的序列)看作一个随机事件,并赋予相应的概率来描述其属于某种语言集合的可能性。给定一个词汇集合 V,对于一个由 V 中的词构成的序列 S = 〈w1, · · · , wT 〉 ∈ Vn,统计语言模型赋予这个序列一个概率 P(S),来衡量 S 符合自然语言的语法和语义规则的置信度。
常见的统计语言模型有N-gram Model,最常见的是 unigram model、bigram model、trigram model 等等。形式化讲,统计语言模型的作用是为一个长度为 m 的字符串确定一个概率分布 P(w1; w2; :::; wm),表示其存在的可能性,其中 w1 到 wm 依次表示这段文本中的各个词。一般在实际求解过程中,通常采用下式计算其概率值: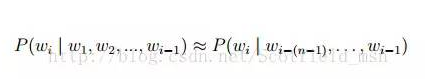
- 词的表示:(参考)分为离散表示和分布表示:
①离散表示主要有:one-hot、Bag of Words、TF-IDF
②分布表示又分为:基于矩阵的分布表示(主要有Glove模型、共现矩阵、SVD分解等等)和基于神经网络的分布表示(主要有word2vec、NNLM、RNNLM、C&W等等)
NLTK语料库:

文本处理流程:

- Tokenize就是分词:
有不合语法的分词需要用到正则表达式:


- 词形归一化:
①Stemming 词⼲提取:⼀般来说,就是把不影响词性的inflection的⼩尾巴砍掉 :
②Lemmatization 词形归⼀:把各种类型的词的变形,都归为⼀个形式: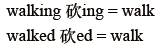
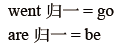
③一写nltk实现stemming 的例子:
④Pos Tag:有时词性不同重名会有小问题

- Stopwords:去停用词

- 总结:文本预处理流水线:
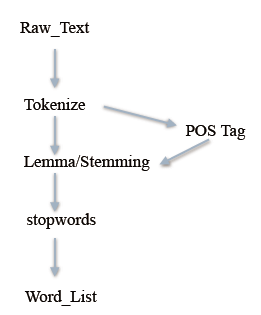
接下来我们就可以进行对清洗过的词进行各种特征工程的处理了。
To be continue.....