对话系统-----seq2seq基本模型
本文介绍一下应用在对话系统的seq2seq基本模型,当然也可以应用在chatbot,翻译等相似任务中。因为在之前的学习中,经常被seq2seq一些代码中的输入和输出的搞混,特别是decoder的target,input,output的形式。从基本模型和伪代码两个角度讲解说明。
基本模型
seq2seq的基本模型包括了两个部分,encoder和decoder部分,encoder用来对输入进行信息的抽取(隐层向量承载信息),decoder用来产生输出。基础的seq2seq模型的encoder和decoder都是由基础RNN单元组成的,也可以是LSTM单元或者GRU单元。我们可以看下面这张图,其中每一个方块都是一个RNN单元,左侧三个代表encoder部分,右侧代表decoder部分。RNN单元之间的箭头代表隐层向量的流动方向,隐层向量承载着RNN单元对输入抽取的信息。

输入[A,B,C],我们希望经过训练的模型能够输出[W,X,Y,Z],就是说我们的目标target是[W,X,Y,Z]。<go>和<eos>是decoder端需要的标志位,分别指示句子的开始和结束。
因为我们使用一个深度学习模型通常会有两个步骤:training和inference。对于encoder来说这两个步骤没有操作上的区别,但是对于decoder是不一样的,因为training阶段训练集我们是有正确的target的,可以使用target对decoder进行训练,但是inference阶段是没有target的。
一般情况下seq2seq的decoder会采用这种方式,在training阶段,用target训练,计算target和decode_output的loss。不过这里要注意的是,decoder的输入和输出是有一个时间步的交错的,因为RNN本本质处理的就是时间序列,所以要有对空白位的填补,这就是<go>和<eos>,这两个标志符还有一个重要的作用就是告诉decoder句子的开始和结束。因此在training阶段decoder的输入和target的真实形式分别是[go,W,X,Y,Z]和[W,X,Y,Z,eos];在inference阶段,将t-1产生的输出作为t的输入再次传入decoder,下面这张图的回环效果。有人马上可能就会问,那填t=1时刻怎么办,前面时刻没有输出啊。是的,所以这时候<go>就派上了用场,指示开始decode,并且填补了这个空白。
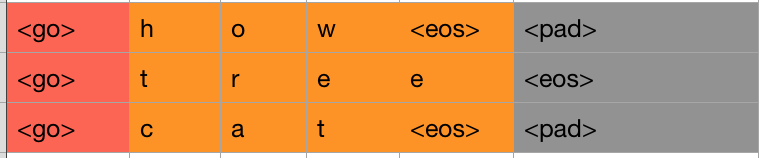
最后,因为seq2seq模型要求输入的句子长度保持一致,新版的TensorFlow接口中只要求每个batch中的句子长度保持一致,不管怎样,我们都需要都句子进行最大长度的padding,这个不用多说。但是在decoder训练阶段,上面的例子中我们说到要删除<eos>,但在实际操作中我们是删掉的最后一个<eos>或者<pad>。看下面这张图就一目了然了。
TensorFlow中已经为我们分装好了用于training阶段和inference阶段的API,我们直接调用就好了。具体使用可以参考我的这篇文章。
伪代码
我们以一个伪代码例子说明seq2seq的工作过程。
training阶段
# 训练数据
input_text = ['A', 'B', 'C']
output_text = ['W', 'X', 'Y', 'Z'] // 目标target
# 计算encoder的状态,用于承载信息传入decoder
encoder_state = encoder(input_text)
output_text_with_start = ['<go>'] + output_text
output_text_with_end = output_text + ['<eos>']
output = []
decoder_state = 0
for decoder_input, decoder_target in zip(
output_text_with_start, output_text_with_end):
# decoder_state 相当于每轮都会更新
# 根据不同策略,最开始可以是 0 (例如是一个全 0 向量的状态)
# 然后每轮结束后,decoder_state 也会更新
decoder_output, decoder_state = decoder(
encoder_state, decoder_state, decoder_input)
output.append(decoder_output)
# 收集loss
loss = loss_function(decoder_output, decoder_target)
# 第一个 loss 实际上相当于概率 P('W'|'<go>') 的损失函数
# 也就是给decoder输入最开始字符'go',给出句子的第一个词'W'的概率,依次还有:
# P('X'|'W')
# P('Y|'X')
# P('Z|'Y')
# P('<eos>'|'Z')
# 也即是我们分别喂给decoder: '<go>', 'W', 'X', 'Y', 'Z'
# 我们希望它的输出是:'W', 'X', 'Y', 'Z', '<eos>'
"""
decoder(encoder_state, decoder_state, '<go>') -> 'W'
decoder(encoder_state, decoder_state, 'W') -> 'X'
decoder(encoder_state, decoder_state, 'X') -> 'Y'
decoder(encoder_state, decoder_state, 'Y') -> 'Z'
decoder(encoder_state, decoder_state, 'Z') -> '<EOS>'
output == ['W', 'X', 'Y', 'Z', '<EOS>']
"""
inference阶段
# 用户输入数据
input_text = ['床', '前', '明', '月', '光']
# 计算encoder的状态
encoder_state = encoder(input_text)
# 第一个输入到decoder的字,是我们预设的'<go>'
# 而后续输入到decoder的字,是上一轮decoder的输出
last_decoder_output = '<go>'
output = []
decoder_state = 0
# 如果句子太长了,就是说预测句子结尾可能已经失败了
# 则退出预测
# 也就是循环最长也就是output_length_limit
for _ in range(output_length_limit):
# decoder_state 相当于每轮都会更新
decoder_output, decoder_state = decoder(
encoder_state, decoder_state, last_decoder_output)
output.append(decoder_output)
# 更新 last_decoder_output
last_decoder_output = decoder_output
# 如果察觉到句子结尾,则直接退出预测
if decoder_output == '<eos>':
break