Abstract
特征上采样 是许多现代卷积网络架构中的关键操作,例如特征金字塔。它的设计对于目标检测 和 语义/实例分割等密集预测任务至关重要。在这项工作中,我们 提出了 内容感知特征重组 (CARAFE),这是 一种通用、轻量级且高效的运算符 来实现这一目标。
CARAFE 具有几个吸引人的特性:
(1) 大视野。与以前仅利用亚像素邻域的作品(例如双线性插值)不同,CARAFE 可以在大的感受野内聚合上下文信息。
(2) 内容感知处理。 CARAFE 不是对所有样本使用固定内核(例如反卷积),而是 启用特定于实例的内容感知处理,从而即时生成自适应内核。
(3) 轻量级和快速计算。 CARAFE 引入的计算开销很小,可以很容易地集成到现代网络架构中。
我们对目标检测、实例/语义分割和修复方面的标准基准进行综合评估。 CARAFE 在所有任务中显示出一致且显著的收益(分别为 1.2% AP、1.3% AP、1.8% mIoU、1.1dB),计算开销可忽略不计。它具有作为未来研究的强大基石的巨大潜力。
代码和模型可在 https://github.com/open-mmlab/mmdetection 获得。
1. Introduction
特征上采样是深度神经网络中最基本的操作之一。一方面,对于密集预测任务(例如超分辨率 [7, 20]、修复 [13, 32] 和 语义分割 [43, 5])中的解码器,对 高级别/低分辨率特征图进行上采样以匹配高分辨率的监督 。另一方面,特征上采样也 涉及 融合 高层/低分辨率特征图 和 低层/高分辨率特征图,这在许多最先进的架构中被广泛采用,例如,特征金字塔网络 [21]、U-Net [34] 和 Stacked Hourglass [29]。因此,设计有效的特征上采样算子成为一个关键问题。
最广泛使用的特征上采样算子是 最近邻 和 双线性插值,它们采用 像素之间的空间距离 来指导上采样过程。然而,最近邻 和 双线性插值 仅考虑亚像素邻域,无法捕获密集预测任务所需的丰富语义信息。自适应上采样的另一条途径是 反卷积 [30]。反卷积层用作卷积层的逆运算符,它学习一组与实例无关的上采样内核。但是,它有两个主要缺点。首先,反卷积运算符在整个图像上应用相同的内核,而不管底层内容如何。这 限制了它响应局部变化的能力。其次,它具有大量参数,因此 在使用大内核时计算量大。这使得难以覆盖超出小邻域的更大区域,从而限制了其表达能力和性能。
在这项工作中,我们超越了这些限制,寻求一种 能够 1) 在大感受野内 聚合信息,2) 即时适应特定于实例的内容,以及 3) 保持计算效率 的特征上采样算子。为此,我们提出了一种轻量级但高效的运算符,称为 Content-Aware ReAssembly of Features (CARAFE)。具体来说,CARAFE 通过 加权组合 在以每个位置为中心的预定义区域内 重新组合特征,其中 权重以内容感知的方式生成。此外,每个位置都有多组这样的上采样权重。然后通过 将生成的特征重新排列为空间块 来完成特征上采样。
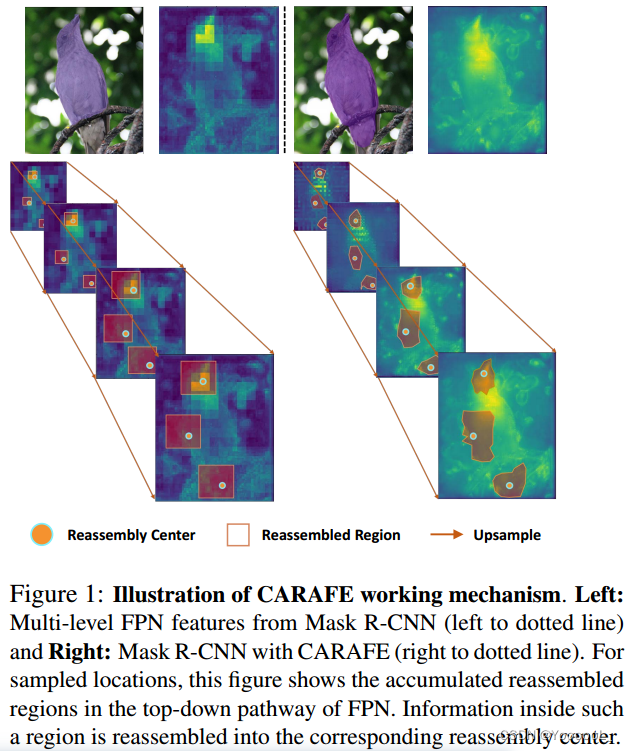
请注意,这些 空间自适应权重 不会作为网络参数学习。相反,它们是动态预测的,使用 具有 softmax 激活的轻量级全卷积模块。图 1 揭示了 CARAFE 的工作机制。经过 CARAFE 上采样后,特征图可以更准确地表示物体的形状,从而使模型可以预测更好的实例分割结果。我们的 CARAFE 不仅在空间上对特征图进行上采样,而且还学习增强其辨别力。
为了证明 CARAFE 的普遍有效性,我们对主流架构的各种密集预测任务进行了综合评估,即目标检测、实例分割、语义分割、图像修复和主流架构。 CARAFE 可以在 MS COCO [22] test-dev 2018 上 将 Faster RCNN [33] 在目标检测中的性能提高 1.2%,在实例分割中将 Mask RCNN [9] 的性能提高 1.3% AP。CARAFE 在语义分割的 ADE20k [47、48] val 上进一步将 UperNet [38] 提高了 1.8% mIoU,在图像修复中将 Global&Local [13] 在 Places [46] val 上的 PSNR 提高了 1.1 dB。当对具有 256 个通道的 H × W 特征图进行两倍上采样时,CARAFE 引入的计算开销仅为 H ∗ W ∗ 199k FLOPs,而反卷积的 H ∗ W ∗ 1180k FLOPs。所有任务的实质性收益表明,CARAFE 是一种有效且高效的特征上采样算子,具有作为未来研究的强大构建块的巨大潜力。
2. Related Work
上采样运算符。
最常用的上采样方法是 最近邻 和 双线性插值。这些插值 利用距离来测量像素之间的相关性,并在其中 使用了手工制作的上采样内核。在深度学习时代,提出了几种使用可学习算子对特征图进行上采样的方法。例如,反卷积 [30] 是卷积的逆运算符,是那些可学习的上采样器中最著名的。 Pixel Shuffle [35] 提出了一种不同的上采样器,它将 通道空间上的深度 重塑为 spatial空间上的宽度和高度。最近,[26] 提出了 引导上采样(GUM),它通过对具有可学习偏移量的像素进行采样来执行插值。然而,这些方法要么 利用小邻域中的上下文信息,要么 需要昂贵的计算 来执行 自适应插值。在超分辨率和去噪领域,其他一些作品 [27、16、11] 也探索在低级视觉中空间上使用可学习内核。本着类似的设计精神,我们在这里展示了 内容感知特征重组 在几个视觉感知任务中用于上采样的有效性和工作机制,并提供了一个轻量级的解决方案。
密集预测任务。
目标检测是使用边界框定位对象的任务,实例分割还需要预测实例掩码。Faster-RCNN [33] 引入区域生成网络 (RPN) 进行端到端训练,并通过引导锚方案 [37] 进一步改进。 [21, 24, 17, 45, 31] 利用 多尺度特征金字塔 来处理不同尺度的对象。通过 添加额外的掩码预测分支,Mask-RCNN [9] 及其变体 [1、12] 产生了有希望的像素级结果。语义分割 [25, 19] 需要对给定图像进行逐像素的语义预测。 PSPNet [43] 在多个网格尺度上引入了空间池化。UperNet [38] 基于 PSPNet 设计了一个更通用的框架。图像或视频修复 [42、40、39] 是填补输入图片缺失区域的经典问题。 U-net [34] 在最近的作品 [13、36] 中很受欢迎,并采用多个上采样运算符。Liu 等人 [23] 引入部分卷积层来减轻缺失区域对卷积层的影响。我们的 CARAFE 在广泛的密集预测任务中展示了通用的有效性。
3. 特征的内容感知重组
特征上采样是许多现代卷积网络架构中的关键运算符,这些架构是为目标检测、实例分割和场景解析等任务开发的。在这项工作中,我们 提出了 内容感知的特征重组(CARAFE)来对特征图进行上采样。在每个位置,CARAFE 可以 利用 底层内容信息 来预测重组内核 并 在预定义的邻域内重组特征。得益于内容信息,CARAFE 可以在不同位置使用自适应和优化的重组内核,并获得比主流上采样运算符更好的性能,例如 插值 或 反卷积。
3.1. 公式
CARAFE 用作 具有内容感知内核的 重组运算符。它 由两个步骤组成。第一步是 根据每个目标位置的内容 预测一个重组内核,第二步是 用预测的内核重组特征。给定大小为 C × H × W 的特征图 X 和 上采样率 σ(假设 σ 为整数),CARAFE 将生成大小为 C × σH × σW 的新特征图 X'。对于输出 X' 的任意目标位置 l' = (i' , j' ),在输入 X 处都有对应的源位置 l = (i, j) ,其中 ![]() ,
,![]() 。这里我们将 N(Xl, k) 表示为以位置 l 为中心的 X 的 k × k 子区域,即 Xl 的邻域。
。这里我们将 N(Xl, k) 表示为以位置 l 为中心的 X 的 k × k 子区域,即 Xl 的邻域。
在第一步中,内核预测模块 ψ 根据 Xl 的邻居为每个位置 l' 预测 位置合适的内核 Wl' ,如等式 (1)所示。 重组步骤公式化为 Eqn(2),其中 φ 是内容感知重组模块,它将 Xl 的邻居与内核 Wl' 重组:
![]()
![]()
我们在以下部分中指定了 ψ 和 φ 的详细信息。
3.2.内核预测模块
内核预测模块 负责 以内容感知的方式 生成重组内核。 X 上的每个源位置对应于 X' 上的 σ2 个目标位置。每个目标位置都需要一个 kup × kup 重组内核,其中 kup 是重组内核的大小。因此,该模块将输出大小为 Cup × H × W 的重组内核,其中 ![]() 。
。
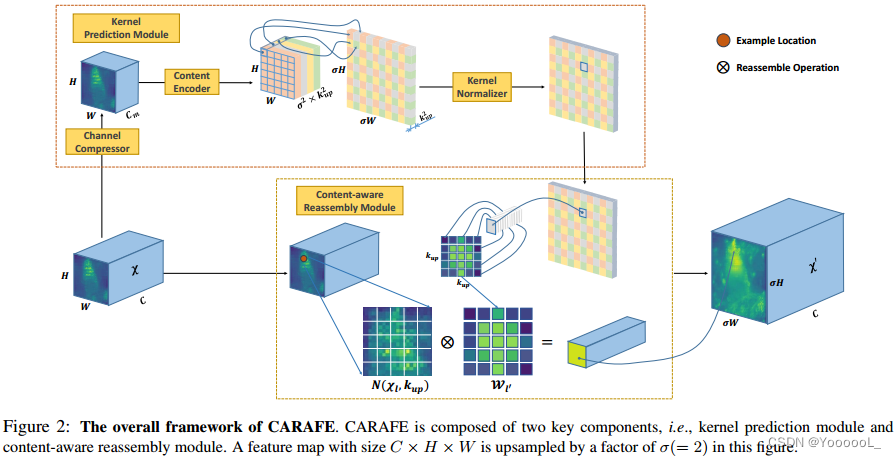
内核预测模块由三个子模块组成,即 通道压缩器、内容编码器 和 内核归一化器,如图 2 所示。通道压缩器减少输入特征图的通道。然后 内容编码器 将压缩的特征图 作为输入 并 对内容进行编码 以生成重组内核。最后,内核归一化器将 softmax 函数应用于每个重组内核。下面对这三个子模块进行详细解释。
Channel Compressor 通道压缩器。
我们采用 1×1 卷积层将输入特征通道从 C 压缩到 Cm。减少输入特征图的通道可以减少后续步骤中的参数和计算成本,从而提高 CARAFE 的效率。也可以在相同预算下为内容编码器使用更大的内核大小。实验结果表明,在可接受的范围内减少特征通道不会损害性能。
Content Encoder 内容编码器。
我们使用 内核大小为kencoder 的卷积层 根据 输入特征的内容 生成重组内核。编码器的参数为kencoder×kencoder×Cm×Cup。直观上,增加 kencoder 可以扩大编码器的感受野,并利用更大区域内的上下文信息,这对于预测重组内核很重要。然而,计算复杂度随着内核大小的平方而增长,而更大内核大小的好处却没有。通过我们在第 5.3 节中的研究,经验公式 kencoder = kup−2 是性能和效率之间的良好折衷。
Kernel Normalizer 内核归一化器。
在应用于输入特征图之前,每个 kup × kup 重组核在空间上用 softmax 函数进行归一化。归一化步骤强制核值之和为 1,这是一个跨局部区域的软选择。由于内核归一化器,CARAFE 不执行任何 重新缩放 和 更改特征图的平均值,这就是为什么我们提出的运算符被命名为特征重组。
3.3.内容感知重组模块
对于每个重组内核 Wl' ,内容感知重组模块将 通过函数 φ 重组局部区域内的特征。我们采用一种简单的 φ 形式,它只是一个加权求和运算符。对于目标位置 l' 和 以 l = (i, j) 为中心的相应正方形区域 N(Xl, kup),重组如方程式(3)所示。 其中![]() :
:
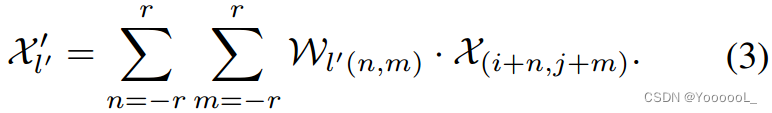
使用重组内核,N(Xl, kup) 区域中的每个像素对上采样像素 l' 的贡献不同,基于特征的内容而不是位置的距离。重组后的特征图的语义可以比原始特征图更强,因为可以更多地关注来自局部区域相关点的信息。
3.4. 与先前操作符的关系
在这里,我们讨论了 CARAFE 与动态滤波器 [15]、空间注意力 [3]、空间变换器 [14] 和 可变形卷积 [6] 之间的关系,它们具有相似的设计理念,但侧重点不同。
dynamic filter
动态过滤器生成以网络输入为条件的 特定于实例的 卷积过滤器,然后将预测的过滤器应用于输入。动态过滤器和 CARAFE 都是内容感知运算符,但它们之间的根本区别在于它们的内核生成过程。具体来说,动态过滤器作为两步卷积工作,其中额外的过滤器预测层和过滤层需要大量计算。相反,CARAFE 只是简单地对局部区域的特征进行重组,没有学习跨通道的特征转换。假设输入特征图的通道为 C,过滤器的内核大小为 K,则动态过滤器中每个位置的预测内核参数为 C × C × K × K。对于 CARAFE,内核参数仅为 K × K。因此,它在内存和速度方面更高效。
空间注意力。
空间注意力预测一个与输入特征大小相同的注意力图,然后在每个位置重新缩放特征图。我们的 CARAFE 通过加权和重新组合局部区域的特征。总之,空间注意力是一个具有逐点指导的重新缩放算子,而 CARAFE 是一个具有区域局部指导的重组算子。空间注意力可以看作是 CARAFE 的一个特例,其中重组内核大小为 1,与内核归一化器无关。
空间变换网络 (STN)。
STN 预测以输入特征图为条件的全局参数变换,并通过变换扭曲特征。然而,这种全局参数变换假设太强,无法表示复杂的空间方差;众所周知,STN 很难训练。在这里,CARAFE 使用特定于位置的重组来处理空间关系,从而实现更灵活的局部几何建模。
可变形卷积网络 (DCN)。
DCN也采用了学习几何变换的思想,并将其与常规卷积层相结合。它 预测内核偏移量 而不是使用网格卷积内核。与动态滤波器类似,它也是一个重heavy参数运算符,计算成本是 CARAFE 的 24 倍。众所周知,它对参数初始化很敏感。
4.CARAFE的应用
CARAFE 可以无缝集成到需要上采样运算符的现有框架中。在这里,我们介绍了主流密集预测任务中的一些应用。凭借可忽略不计的附加参数,CARAFE 在高级和低级任务(例如目标检测、实例分割、语义分割和图像修复)中都受益于最先进的方法。
4.1.目标检测和实例分割
特征金字塔网络(FPN)是目标检测和实例分割领域中重要且有效的体系结构。它显著提高了 Faster R-CNN 和 Mask R-CNN 等流行框架的性能。 FPN 构造具有强语义的特征金字塔,具有自上而下的路径和横向连接。在自上而下的路径中,低分辨率特征图首先使用最近邻插值进行 2 倍上采样,然后与高分辨率特征图融合,如图 3 所示。
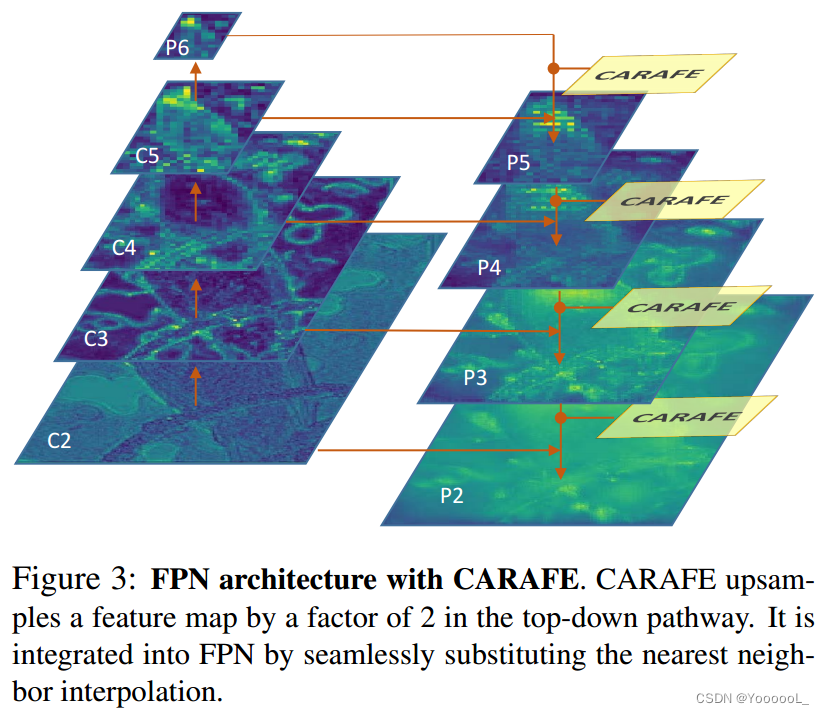
我们提出用 CARAFE 替换所有特征级别中的最近邻插值。这个修改很顺利,不需要额外改动。除了FPN结构,Mask R-CNN在mask head的末端采用了反卷积层。它用于将预测数字从 14 × 14 上采样到 28 × 28,以获得更精细的掩码预测。我们 还可以使用 CARAFE 代替反卷积层,从而减少计算成本。
5. 实验
5.1. 实验设置
数据集和评估指标。
我们在几个重要的密集预测基准上评估 CARAFE。我们使用 train split 进行训练,并默认评估所有这些数据集在 val split 上的性能。
目标检测和实例分割。
我们对具有挑战性的 MS COCO 2017 数据集进行了实验。结果使用标准 COCO 指标进行评估,即IoU 的 mAP 从 0.5 到 0.95。
实施细节。
如果没有特别说明,CARAFE 在实验中采用一组固定的超参数,其中通道压缩器的 Cm 为 64,内容编码器的 kencoder = 3,kup = 5。在补充材料中查看更多实施细节。
目标检测和实例分割。
我们使用带有 FPN 骨干的 ResNet-50 在 Faster RCNN 和 Mask RCNN 上评估 CARAFE,并遵循 Detectron [8] 和 MMDetection [2] 等 1x 训练计划设置。
5.2.基准测试结果
目标检测和实例分割。
我们首先通过将 Faster RCNN 和 Mask RCNN 的 FPN 中的最近邻插值 替换为 CARAFE,以及 Mask RCNN 的掩码头中的反卷积层来评估我们的方法。如表 1 所示,CARAFE 在 bbox AP 上将 Faster RCNN 提高了 1.2%,在 Mask AP 上将 Mask RCNN 提高了 1.3%。 APS、APM、APL的提升都在1%AP以上,说明它对各种物体尺度都有好处。
我们令人鼓舞的表现得到了图 1 所示的定性结果的支持。我们在 FPN 的自上而下路径中可视化特征图,并将 CARAFE 与基线(即最近邻插值)进行比较。很明显,通过内容感知重组,特征图更具辨别力,并且可以预测更准确的目标掩码。在图 4 中,我们展示了一些比较基线和 CARAFE 的实例分割结果示例。

为了研究不同上采样算子的有效性,我们通过使用不同的算子在 FPN 中执行上采样,在 Faster RCNN 上进行了大量实验。结果如表 2 所示。对于“N.C.”和“B.C.”,分别表示“Nearest + Conv”和“Bilinear + Conv”,我们在相应的上采样之后添加了一个额外的 3×3 卷积层。 ‘Deconv’、 ‘Pixel Shuffle’(表示为‘P.S.’)、‘GUM’是三种具有代表性的基于学习的上采样方法。我们还在这里比较了“空间注意力”,表示为“S.A.”。CARAFE 在所有这些上采样算子中实现了最好的 AP,FLOPs 和参数都相对较小,这证明它 既有效又高效。 “Nearest + Conv”和“Bilinear + Conv”的结果表明 额外的参数不会带来显著的收益。 “Deconv”、“Pixel Shuffle”、“GUM”和“Spatial Attention”的性能不如 CARAFE,这表明 有效的上采样算子的设计至关重要。
除了作为金字塔特征融合结构的 FPN 之外,我们还在掩码头中探索了不同的上采样算子。在典型的 Mask R-CNN 中,采用反卷积层对 RoI 特征进行 2 倍上采样。为了公平比较,我们不对 FPN 做任何改动,只是将反卷积层替换为各种算子。由于我们只修改掩码预测分支,因此根据掩码 AP 报告性能,如表 3 所示。CARAFE 在这些方法中实现了实例分割的最佳性能。
5.3.消融研究和进一步分析
模型设计和超参数。
我们研究了模型设计中超参数的影响,即压缩通道 Cm、编码器内核大小 kencoder 和重组内核大小 kup。我们还在内核归一化器中测试了不同的规范化方法。我们使用 ResNet-50 主干对 Faster RCNN 的设计和设置进行消融研究,并评估 COCO 2017 val 的结果。
为了实现高效设计,我们首先分析了由 FLOP 测量的计算复杂度。当使用因子 σ 对输入通道 Cin 的特征图进行上采样时,CARAFE 的每像素 FLOPs 计算为 ![]() ,参考[28]。
,参考[28]。

我们在通道压缩器中试验了不同的 Cm 值。此外,我们还尝试移除通道压缩器模块,这意味着内容编码器直接使用输入特征来预测重组内核。表 8 中的实验结果表明,将 Cm 压缩到 64 不会导致性能下降,同时效率更高。更小的 Cm 将导致性能略有下降。在没有通道压缩器的情况下,它可以达到相同的性能,这证明 通道压缩器 可以 在不损害性能的情况下 加快内核预测。基于以上结果,我们将 Cm 默认设置为 64,作为性能和效率之间的折衷。
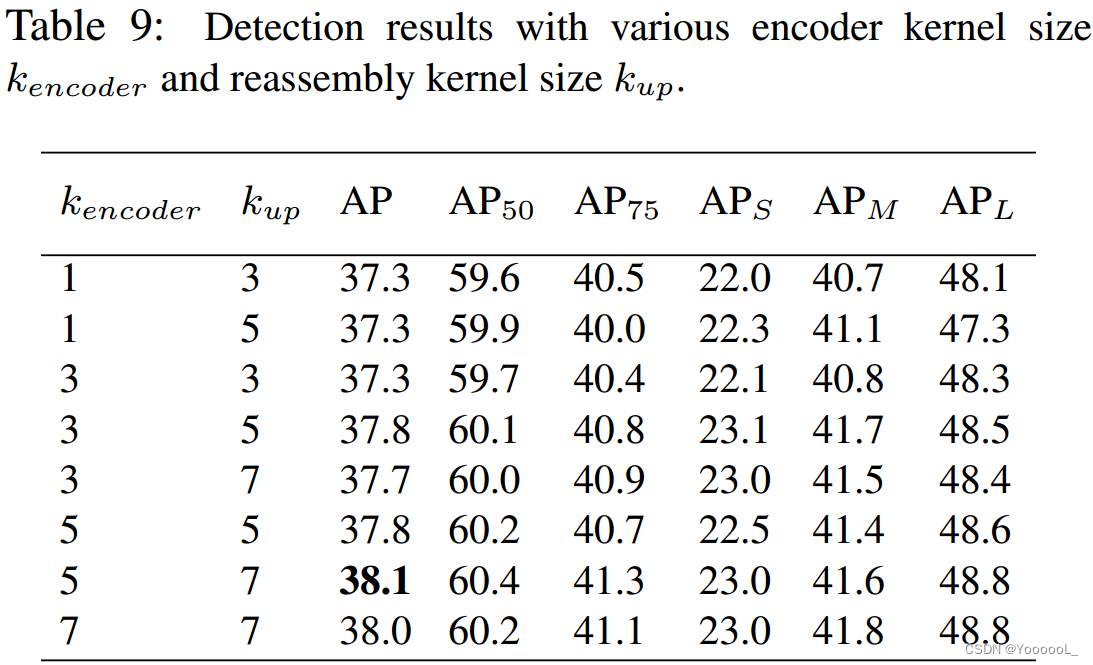
然后我们调查 kencoder 和 kup 的影响。直观地,增加 kup 也需要更大的 kencoder,因为内容编码器需要更大的感受野来预测更大的重组内核。如表 9 所示,同时增加 kencoder 和 kup 可以提高性能,而仅扩大其中之一则不会。我们总结了一个经验公式 kencoder = kup − 2,这在所有设置中都是一个不错的选择。虽然采用更大的内核大小被证明是有帮助的,但我们默认设置 kup = 5 和 kencoder = 3 作为性能和效率之间的折衷。
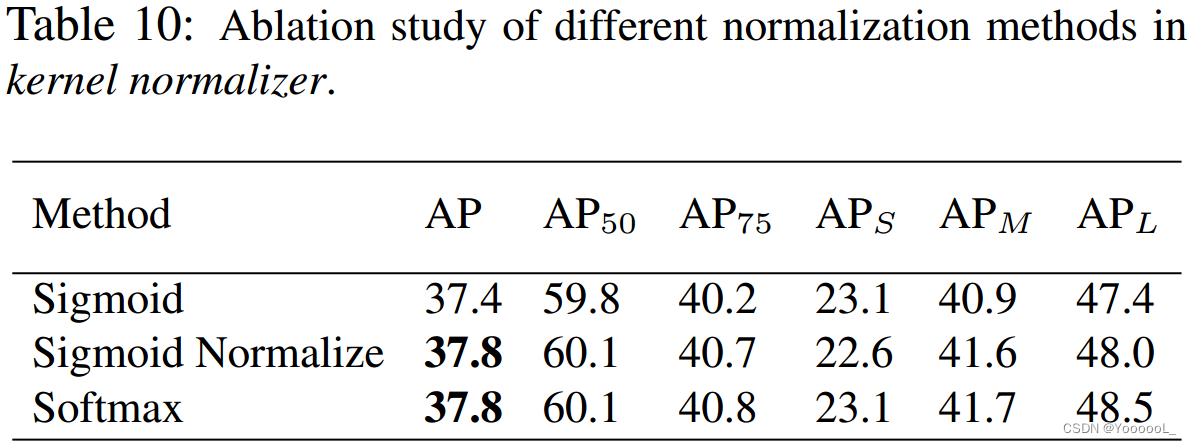
除了 softmax 函数,我们还测试了内核归一化器中的其他替代方案,例如 sigmoid 或 带归一化的 sigmoid。如表 10 所示,‘Softmax’ 和 ‘Sigmoid Normalized’ 具有相同的性能并且优于 ‘Sigmoid’,这表明 将要总和的重组核归一化为 1 是至关重要的。
CARAFE 的工作原理。

我们进行了进一步的定性研究,以确定 CARAFE 的工作原理。通过采用 CARAFE 作为上采样算子的经过训练的 Mask RCNN 模型,我们在图 5 中可视化了重组过程。在 FPN 结构中,低分辨率的特征图会被连续多次上采样到更高分辨率,因此 上采样后的特征图中的像素 会重新组合来自更大区域的信息。我们对高分辨率特征图中的一些像素进行采样,并查看它是从哪些邻居重新组合而来的。绿色圆圈表示示例位置,红点表示重组期间高权重的来源。从图中我们可以清楚的了解到 CARAFE是内容感知的。它 倾向于重新组合具有相似语义信息的点。人体上的一个位置更喜欢来自同一个人的其他点,而不是其他物体或附近的背景。对于语义较弱的背景区域中的位置,重组更均匀 或 仅偏向于具有相似低级纹理特征的点。
6. Conclusion
我们介绍了 内容感知特征重组 (CARAFE),这是一种通用、轻量级且高效的上采样运算符。它始终将目标检测、实例/语义分割和修复方面的标准基准性能分别提高 1.2% AP、1.3% AP、1.8% mIoU 和 1.1dB。更重要的是,CARAFE 引入的计算开销很小,可以很容易地集成到现代网络架构中。未来的方向包括探索 CARAFE 在图像恢复和超分辨率等低级视觉任务中的适用性。