介绍性的讲解在此不多讲,本文主要讲主题模型LDA的原理。
我们可以从生成模型思考一下,一篇文章由文档进而生成文字,是怎样的一个概率过程呢。在主题模型中,文档“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”。按照该思路,文档中词语出现的概率为:

上面的公式还可以用矩阵来表示:
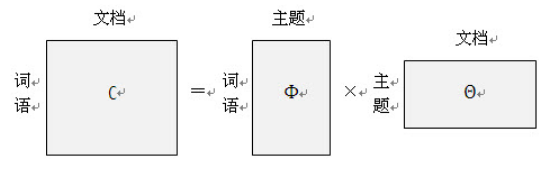
当然,这只是粗略的模型描述,下面我们来说一下LDA主题模型具体用到了哪些概率模型。
LDA(LatentDirichlet Allocation)的概率模型
假设我们有M篇包含N个单词的文档,那么我们可以按照以下方式理解文档生出单词的流程:
1. 首先,每篇文档都有自己的主题,而且可能是多个主题,每个主题的成分有大小之分。所以我们可以假设一篇文档的主题符合多项式分布(参数为)。而这个文档集合的任意一篇文档,其主题分布是符合狄利克雷分布的(参数为
)(参考常见概率分布(一))。
2. 假设我们根据第一步的过程确立了某个主题,那么依据该不同词汇出现的概率是符合多项式分布的(我们这里仅仅考虑频率学派的观点,假如有v个词汇,可以把生成词汇的过程理解为掷N次具有v面的骰子),其参数为。
浓缩一下:
for each doc:
choose for
choose topic z_n for
choose w for
或者用概率图模型的方式来表示:

LDA的参数求解
有了概率模型和数据,我们很自然的想到要用最大似然方法(MLE)求解改模型的参数,但是我们知道和z_n是隐藏变量,也就是观测不到的,这时候我们想到要用EM算法。
对于EM算法第E-step,我们知道需要求得p(z|x),这里z是隐藏变量,x是可观测变量。对应到lda的情况下,就应该是求解后验概率:
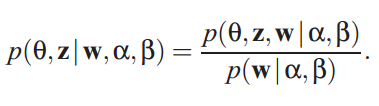
该后验概率非常不易求解,我们想到了使用变分推断技术。变分推断的推导过程可以参考博客Variational Inference 变分推断,这里不做赘述。
参考文献:
[1] Latent Dirichlet Allocation - David M.Blei
[2] LDA主题模型学习笔记2:求解隐变量和模型参数(EM思想)
[3] 主题模型-LDA浅析
[4] 一文详解LDA主题模型