每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。如下图:
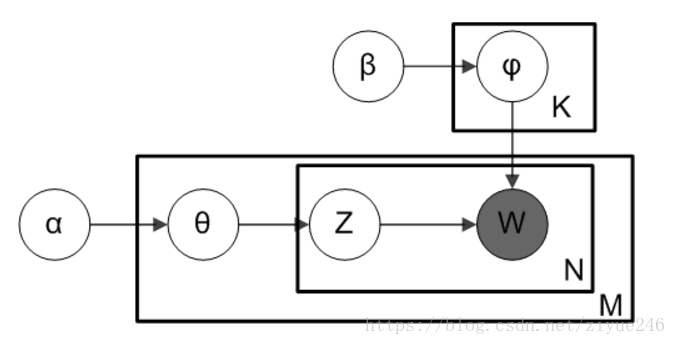
K为主题个数,M为文档总数,是第m个文档的单词总数。 是每个Topic下词的多项分布的Dirichlet先验参数, 是每个文档下Topic的多项分布的Dirichlet先验参数。是第m个文档中第n个词的主题,是m个文档中的第n个词。剩下来的两个隐含变量和分别表示第m个文档下的Topic分布和第k个Topic下词的分布,前者是k维(k为Topic总数)向量,后者是v维向量(v为词典中term总数)。