最近做文本匹配算法比赛遇到LDA抽取特征,故结合西瓜书,总结一下LDA
LDA用生成式模型的角度来看待文档和主题。假设每篇文档包含了多个主题,用θd表示文档t每个话题所占比例,θd,k表示文档t中包含主题d所占用的比例,继而通过如下过程生成文档d。
(1)根据参数为α的狄利克雷分布,随机采样一个话题分布θd;
(2)按照如下步骤生成文中的N个词:
根据θd进行话指派,得到文档d中词n的话题
根据指派话题所对应的词频βk进行采样随机生成词
采用盘式记法可以将模型表示成如下形式
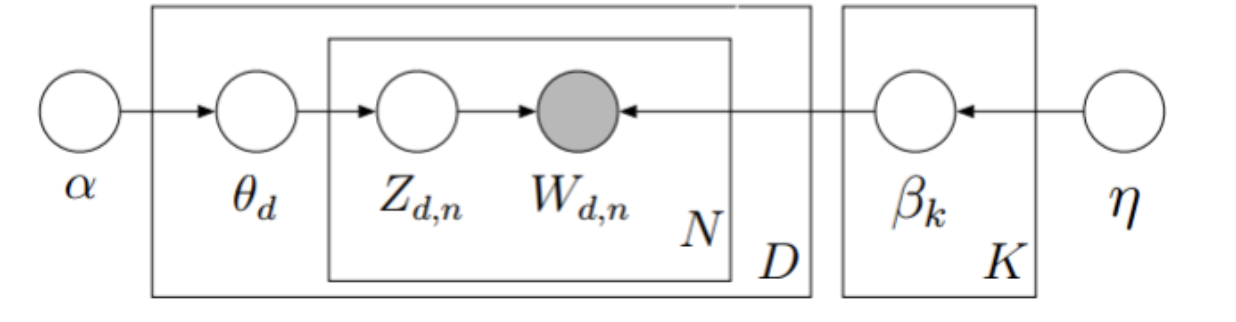
α的狄利克雷分布采样生成D个主题分布对应D篇文章,θd生成词的主题,根据主题词的频率分布生成词。于是LDA模型的概率分布可以写成:
\( p(W,z,\beta,\theta|\alpha,\eta) = \prod_{d=1}^Dp(\theta_d|\alpha)\prod_{i=1}^Kp(\beta_k|\eta)(\prod_{n=1}^NP(w_{d,n}|z_{d,n},\beta_k)P(z_{d,n}|\theta_d)) \)
其实读到这基本上没有什么难点,接下来就是一个小难点。\(p(\theta_d|\alpha)\)和\(p(\beta_k|\eta)\)假设为以\(\alpha\)和\(\eta\)为参数的K维和N为狄利克雷分布。
\( p(\theta_d|\alpha)=\frac{\Gamma(\sum_k\alpha_k)}{\prod_k\Gamma(\alpha_k)}\prod_{k}\theta_{d,k}^{\alpha_k -1} \)
其中\(\Gamma\)为阶乘在实数域的扩展,狄利克雷分布可以理解为二项分布扩展到多维实数域。选择狄利克雷分布其实是为了好计算。
给定训练文本每片文本的词频\( W=\{w_1,w_2,...,w_D\} \), LDA的参数\(\alpha\)和\(\eta\)可以通过极大似然法估计,
\( LL(\alpha,\eta) = \sum_{d=1}^{D}\ln p(w_d|\alpha,\eta) \)
但由于\(p(w_d|\alpha,\eta)\)计算难度较大,常用变分法和吉布斯采样来近似求解。若\(\alpha\)和\(\eta\)已经确定,则可以通过文档词频来推断文档包含的主题结构。下一章将介绍两个硬货,MCMC采样和变分推断。