论文地址:https://ieeexplore.ieee.org/abstract/document/9039580
百度网盘地址:https://pan.baidu.com/s/1A8NKT_wz4UgEFhvqk4xEqg?pwd=dvn5
从arxiv上看,应该是2018年就发了
文章目录
- Abstract
- 1. Introduction
- 2. 数据集(Facial Expression Databases)
- 3. Deep Facial Expression Recognition
- 4. The state-of-the-art
- 个人总结
Abstract
这篇论文会介绍深度学习方面的面部表情识别(Facial Expression Recognition, FER),主要包括:模型,数据集,模型对比等
后续都会用FER来代表面部表情识别
1. Introduction
面部基本表情(basic expressions)包括7种:anger, disgust, fear, happiness, sadness, surprise,contempt
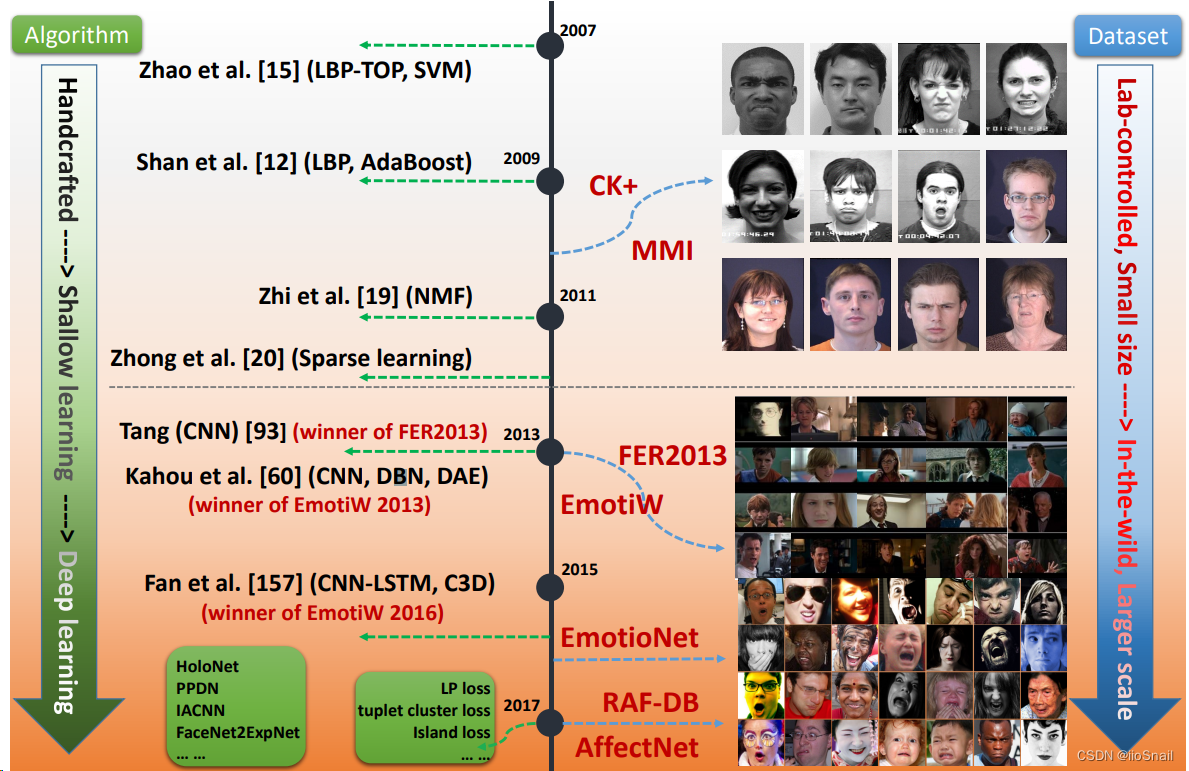
该图展示了FER的方法和数据集的演进过程
面部表情主要分为两种:静态图片识别(static image FER),动态视频识别(dynamic sequence FER)
2. 数据集(Facial Expression Databases)
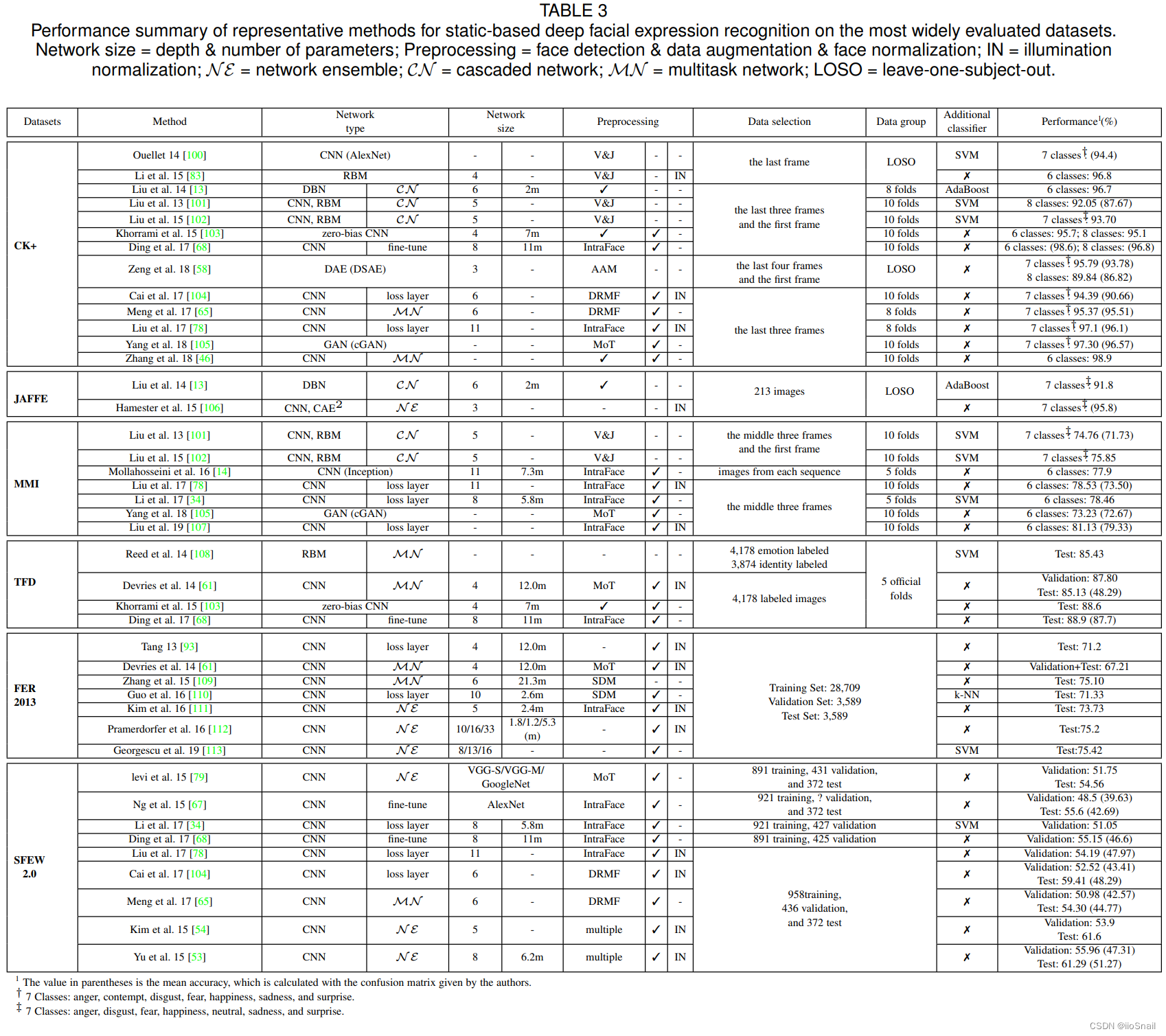
FER常用数据集如下表:
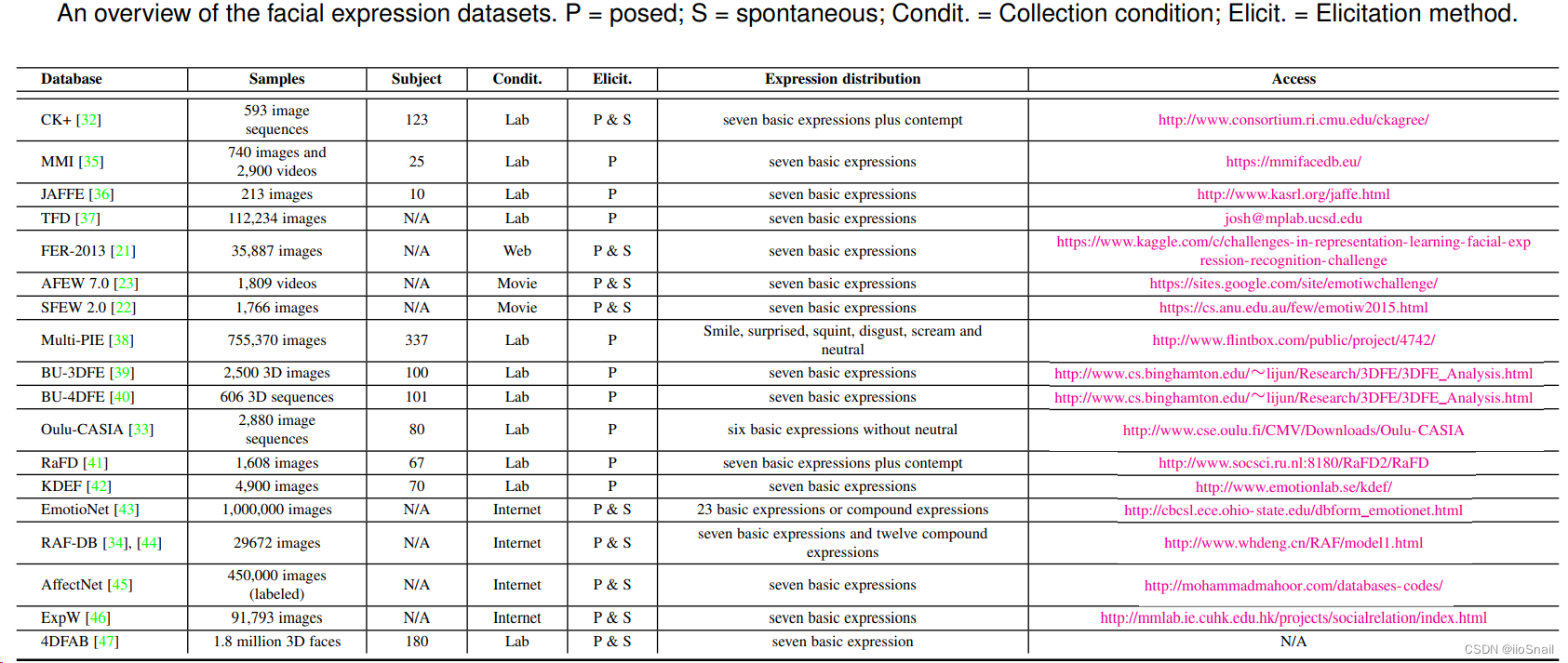
字段解释:
- Database: 数据集的名字
- Samples:样本的数量和形式
- Subject:应该是指人的数量,N/A就是数据集中不知道具体包含了多少人
- Condit:Collection condition,样本从哪收集的
- Elicit:Elicitation method。收集的方式:摆拍(posed, P),自然表情(Spontanueous, S)
- Expression Distribution:包含哪些表情
上表中的数据集介绍:
- CK+:包含表情从面无表情(neutral expression)到极端表情(peak expression,例如大哭大笑等)的变化序列
- MMI:和CK+差不多,标记方法不太一样
- Oulu-CASIA:包含两种成像系统(imaging system):近红外光谱(near-infrared, NIR)和可见光(visible light,VIS);包含三种不同的光照条件(illumination condition)。和CK+一样的变化序列。
- JAFFE:日本女性面部表情(Japanese Female Facial Expression,JAFFE)
- FER2013:分辨率为48*48
- AFEW:Acted Facial Expressions in the Wild
- SFEW:Static Facial Expressions in the Wild
- Multi-PIE:包含15个观察点位(viewpoint)和19种光照条件(illumination conditions)
- BU-3DFE:The binghamton University 3D Facial Expression
- BU-4DFE:动态的BU-3DFE
- EmotioNet:大数据集
- RAF-DB:The real-world Affective Face Database
- AffectNet:提供了两种emotion model:categorical model 和 dimensional model
- ExpW:The Expression in-the-Wild,人工标注,无噪声
- 4DFAB:1,800,000高分辨率3D人脸
3. Deep Facial Expression Recognition
3.1 预处理(Preprocessing)
3.1.1 人脸对齐(Face alignment)
人脸对齐(Face alignment):从图片中找到人脸,把背景和非人脸的地方移除
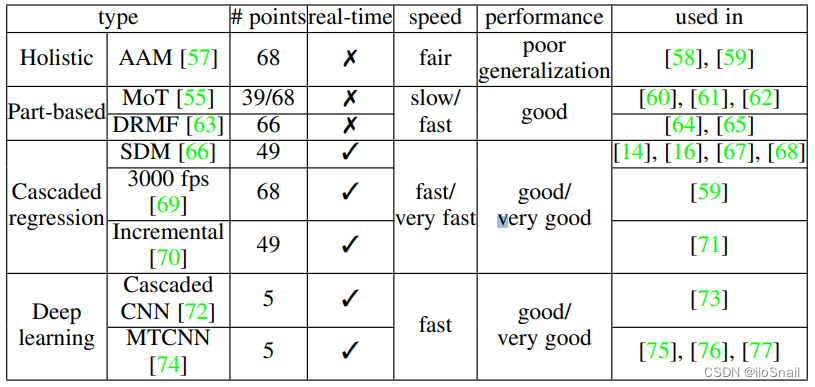
该表展示了基于面部特征点(facial landmark)算法的一些情况
3.1.2 数据增强(Data augmentation)
数据增强主要有两种方式:
- on-the-fly:作用是减缓过拟合。例如:裁掉中心或四个角的一部分,水平翻转等
- offline:作用是扩展数据的多样性。例如:随机扰动(random perturbations),随机变换(random transforms),如旋转,偏移,扭曲,缩放,噪音,调对比度,颜色扰动(rotation, shifting, skew, scaling, noise, contrast, color jittering)
- 其他方式:使用GAN生成人脸
3.1.3 面部矫正(Face normalization)
Face normalization:图片的亮度和姿势千变万化,face normalization就是对这两项进行标准化。
Illumination normaliztion: 想办法突出脸部。例如脸部光线充足一些, 背景光线暗一点。常用方法有 ① isotropic diffusion (IS)-based normalization;② Difference of Gaussian(DoG); ③ homomorphic filtering-based normalization;④ histogram equalization combined with illumination normalization;
相关研究表明illumination normalization结合histogram equalization一起用在人脸识别上表现不错,因为histogram equalization可以增加图片的整体对比度(global contrast),所以当前景和背景的亮度差不多时效果比较好。然而,如果直接使用histogram equalization可能会过度加重局部对比度(local contrast),要解决这个问题,[引用87]提出了一个方法。
Pose normalization:想办法让脸正面朝前。常用的方法:① [引用90]的方法比较流行。②基于GAN的方法
3.2 Deep networks for feature learning
下图展示了常见用于FER的深度学习网络:
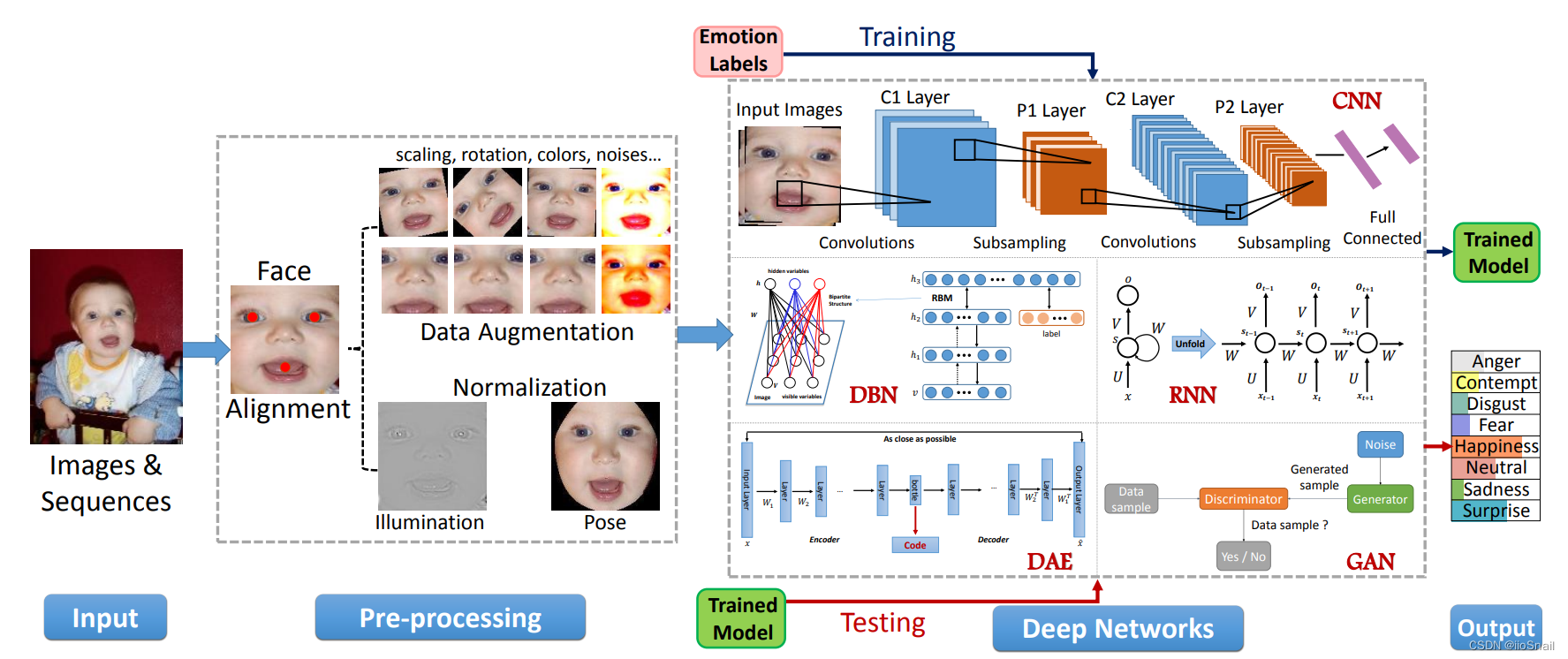
常见的架构有:卷积神经网络(convolutional neural network, CNN),深度信念网络(Deep belef network, DBN),Auto-Encoder,循环神经网络(Recurrent Neural Network, RNN),生成对抗网络(Generative adversarial network, GAN)
3.3 Facial expression classification
用深度学习可以做到 端到端(end-to-end),也可以将人脸检测和表情识别分开。
4. The state-of-the-art
4.1 Pretraining and fine-tuning
比较适合人脸检测的预训练模型:VGG-Face
一个 端到端,two-stage 的网络:FaceNet2ExpNet
4.2 使网络输入多样化(Diverse network input )
相比直接把原始图片送给网络,可以通过一些方法从原始图片提取一些特征,这些特征更聚焦于与表情有关的脸部部分。
有两种方式:
- Low-level representations encode features:① [引用79]提出了 mapped LBP feature 针对illumination-invariant FER,适用于光线变化较大的任务。 ② [引用118]提出的 Scale-invariant feature transform(SIFT) feature 可以很好的应对缩放、旋转等,适用于多角度的FER任务。
- Part-based representations extracrt features:从图片中移除非关键部分,多利用关键部分。对于脸部特征,有三个关键部分(Regions of interests, ROIs): 眉毛,眼镜和嘴巴。 也可以用attention机制去学习关键部位(主要特征(salient features))。
4.3 Deep FER networks for static images
下图是最新的(state-of-the-art)的用于静态 FER 的模型。
4.3.1 辅助模块(Auxiliary block)
HoloNet中的CReLU结合residual stracture增加了网络深度,并且有一个inception-residual block可以学习多比例(multiscale)和表情区分(expression-discriminative)特征。
还可以在一个网络中使用多个监督分数([引用89]),称为Supervised scoring ensemble(SSE),如下图
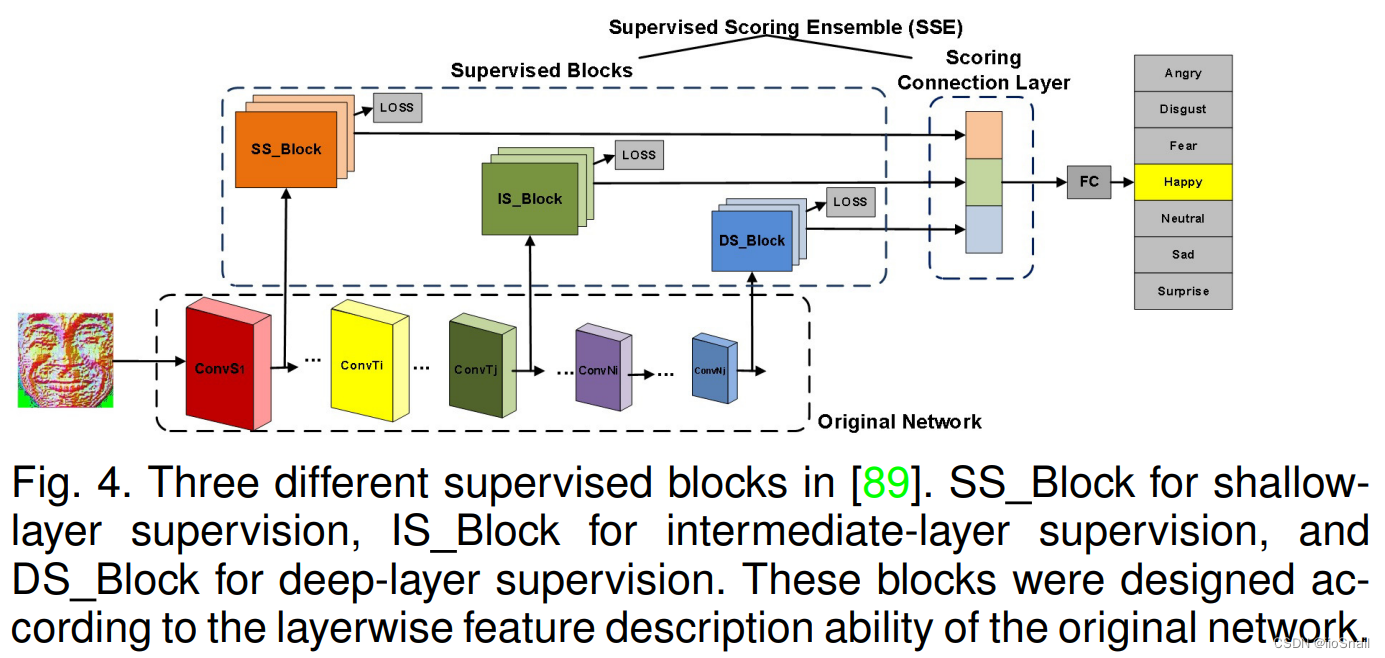
数据集中有些是人标注的,有些是机器标注的,所以会有标注不一致的问题,Inconsistent Pseudo Annotations to Latent Truth(IPA2LT) framework 可以解决该问题
4.3.2 损失函数(Loss Layer)
FER有两个难题:high interclass similarity 和 high intraclass variation
解决方式有:
- penalizes the distance between deep features and their corresponding class centers, two variations were proposed to assist the supervision of the softmax loss for more discriminative features. (不懂TODO)
- island loss[引用104]:增加不同类别之间的距离。如下图所示:
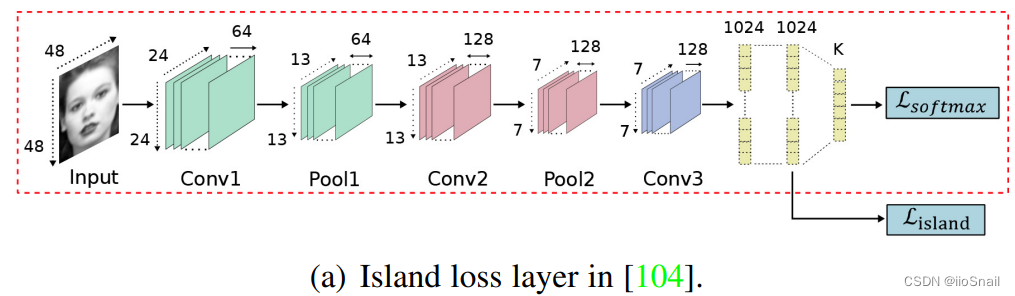
- locality-preserving loss(LP loss)[引用34]:相同表情的特征向量距离越近越好
- 基于triplet loss:正样本 与 anchor 越近越好,负样本 与 anchor 越远越好。相关论文:引用131,引用110,引用78
4.3.3 集成学习(Network ensemble)
集成学习的两个要点:① 模型之间的多样性(diversity)越大越好 ② 一个合适的集成方法
4.3.4 多任务网络(Multitask networks)
就是除了考虑表情外,还要考虑其他潜在因素,如:头的姿势,光线,面部形态(facial morphology)。使用多任务学习可以解决。
相关文献有:引用108(disBM),67,136, 137, 65, 74, 65, 73, 138, 139,46
4.3.5 级联网络(Cascaded Networks)
cascaded network:网络中不同的模块负责不同的任务。例如,网络的前半部分负责提取人脸区域,后半部分对其进行分类。
目前方法有:① DBN[引用140] ② contractive convolutional network (CCNET)[引用141] ③ [引用101,102] ④ boosted DBN(BDBN)[引用13]
4.3.6 生成对抗网络(Generative adversarial network, GAN)
GAN可以用于数据增强和对应的识别任务。
相关研究:
- [引用142] 可以根据侧脸照片生成对应的正脸照片,同时保证表情等特征不被改变
- [引用143] 可以生成不同表情、不同姿势和不同观察角度的图片。
- [引用144] 提出了 identity-adaptive generation model (IA-gen)
- [引用105] 提出了 a de-expression residue learning (DeRL) procedure for exploring the expressive information, which is filtered out during the deexpression process but still embedded in the generator. Then, the model extracts this information from the generator directly to mitigate the influence of subject variations and improve the FER performance.(没看懂TODO)
4.3.7 Discussion

4.4 Deep FER networks for dynamic image sequences
动态表情识别相关模型:
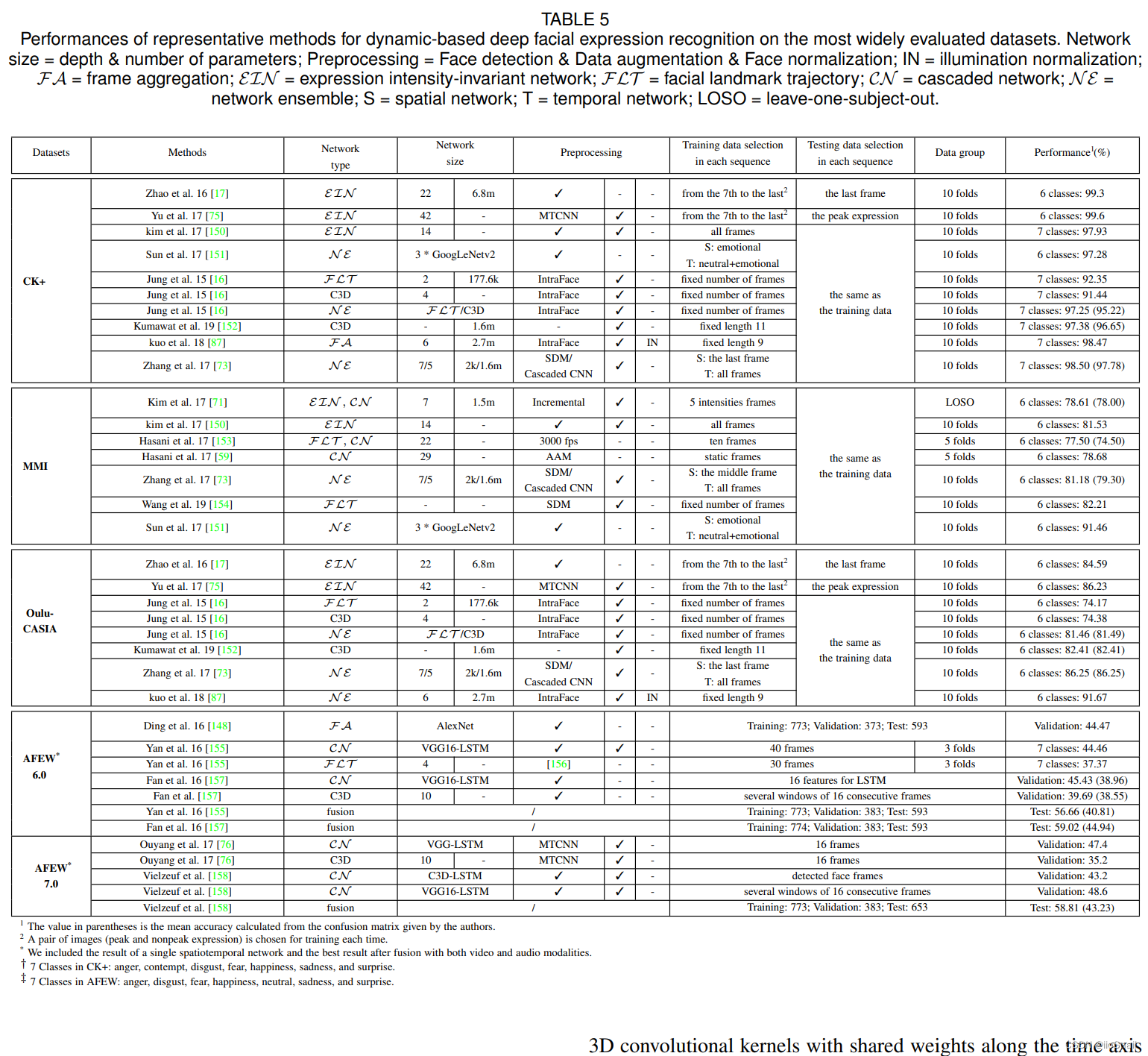
4.4.1 Frame aggregation
对于某个表情的一段视频,每一帧的表情强度(expression intensity)是不同的,所以直接计算每一帧的error显然是不合适的。针对该问题,作者将其分为了两种做法:
- decision-level frame aggregation:直接将所有帧的输出concat到一起。
- feature-level frame aggreation:把所有帧的特征向量合并到一起。
4.4.2 Expression intensity-invariant network
表情是有强度的(开怀大笑,微笑等),本章作者介绍了些 表情无关(intensity-invariant) 的网络。
对于 expression intensity-invariant network 训练集的标签应该包含 intensity。[引用17]提出了 peak-piloted deep network(PPDN) 网络,如下图:
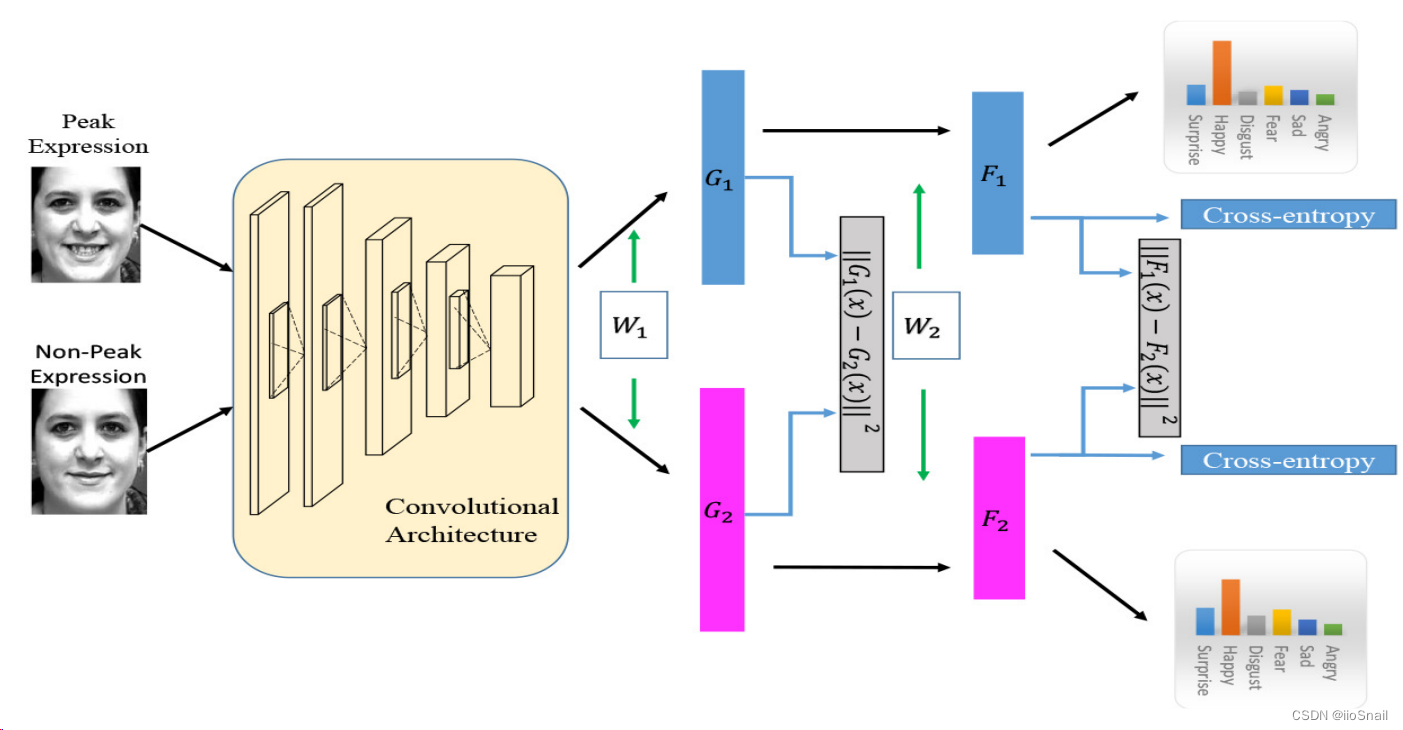
该网络在训练阶段,一次接受两张图片,peak expression和non-peak expression,然后对于损失,除了cross-entropy之外,还增加了一个惩罚项,即让这两个图片特征的距离越近越好。
4.4.3 Deep spatiotemporal FER network
既要考虑空间,又要考虑时间。可以用RNN,或C3D(3D convolutional kernels)
4.4.4 Discussion
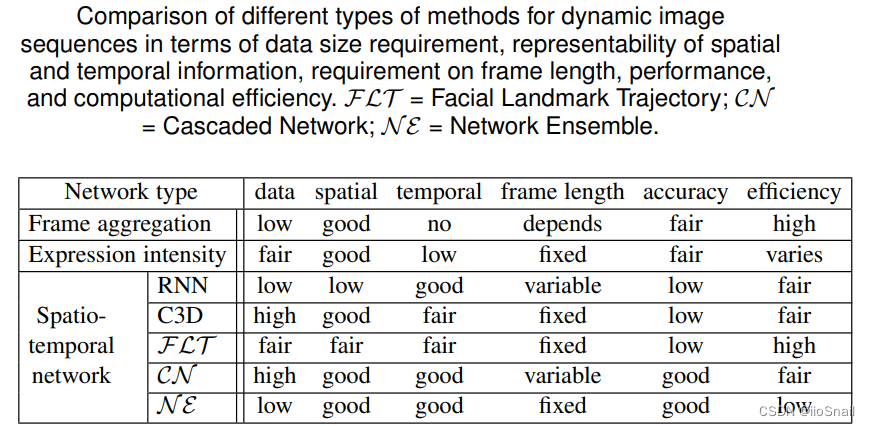
个人总结
这篇综述比较老,个人感觉模型那部分有点过时,不过数据集和预处理那部分可以看一下,可以提供一个思路。