使用散点图矩阵图,可以两两发现特征之间的联系
scatter_matrix(frame, alpha=0.5, c,figsize=None, ax=None, diagonal='hist', marker='.', density_kwds=None,hist_kwds=None, range_padding=0.05, **kwds)1。frame,pandas dataframe对象
2。alpha, 图像透明度,一般取(0,1]
3。figsize,以英寸为单位的图像大小,一般以元组 (width, height) 形式设置
4。ax,可选一般为none
5。diagonal,必须且只能在{‘hist’, ‘kde’}中选择1个,’hist’表示直方图(Histogram plot),’kde’表示核密度估计(Kernel Density Estimation);该参数是scatter_matrix函数的关键参数
6。marker。Matplotlib可用的标记类型,如’.’,’,’,’o’等
7。density_kwds。(other plotting keyword arguments,可选),与kde相关的字典参数
8。hist_kwds。与hist相关的字典参数
9。range_padding。(float, 可选),图像在x轴、y轴原点附近的留白(padding),该值越大,留白距离越大,图像远离坐标原点
10。kwds。与scatter_matrix函数本身相关的字典参数
11。c。颜色
使用python sklearn库里的iris数据集,
import mglearn
import pandas as pd
from sklearn.datasets import load_iris
iris_dataset = load_iris()
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=0)
iris_dataframe=pd.DataFrame(X_train,columns=iris_dataset.feature_names)
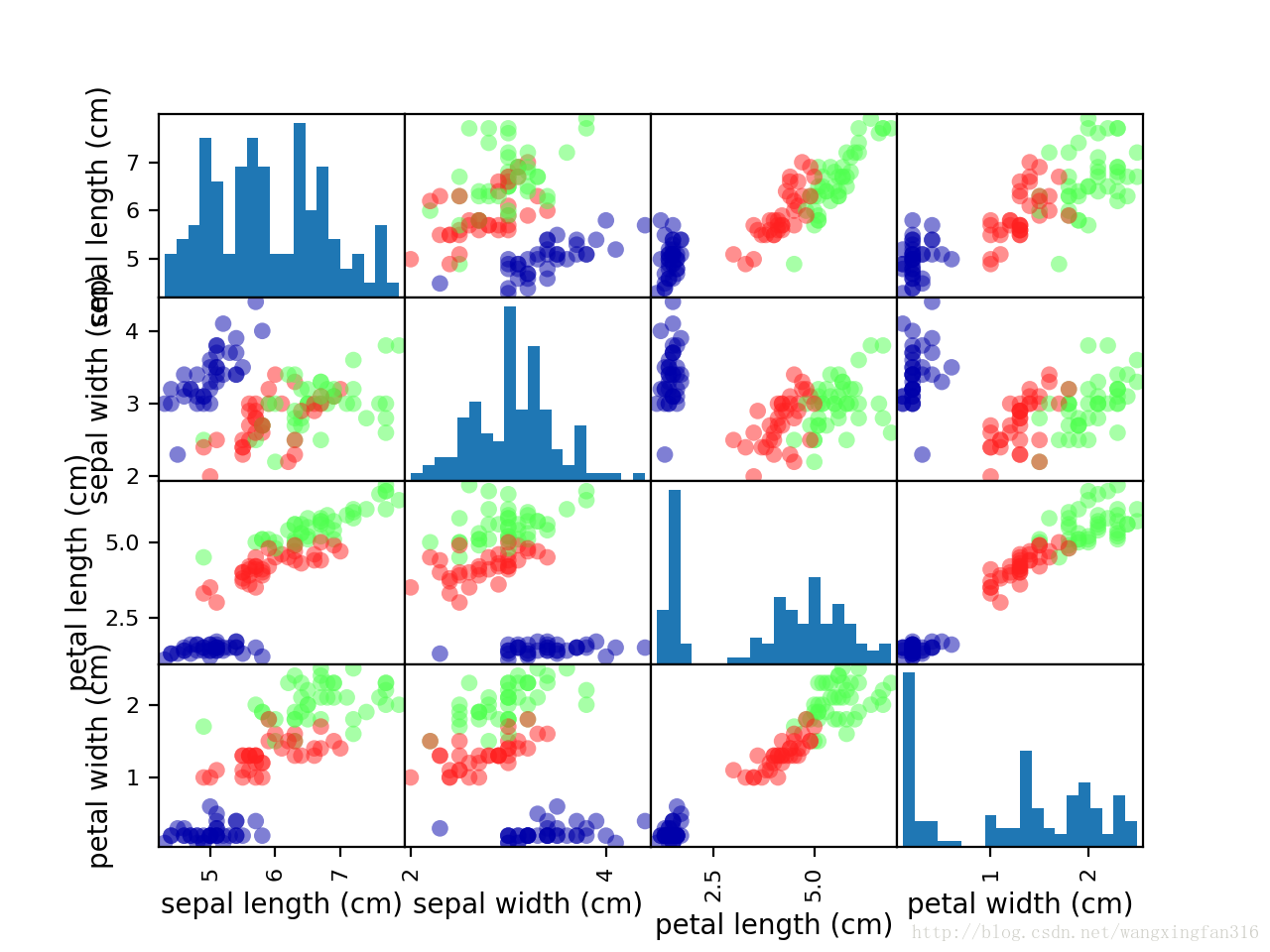
grr = pd.plotting.scatter_matrix(iris_dataframe,marker='o',c = y_train,hist_kwds={'bins':20},cmap=mglearn.cm3)矩阵的对角线是每个特征的直方图,颜色使用训练集的label,可以看出其明显的分开三个类别
get到一个新的知识点
numpy中有一些常用的用来产生随机数的函数,randn()和rand()就属于这其中。
numpy.random.randn(d0, d1, …, dn)是从标准正态分布中返回一个或多个样本值。
numpy.random.rand(d0, d1, …, dn)的随机样本位于[0, 1)中。
参考https://blog.csdn.net/hurry0808/article/details/78573585?locationNum=7&fps=1