-
求均值,表格中含有空值:
#The result of this is that mean_age would be nan. This is because any calculations we do with a null value also result in a null value mean_age = sum(titanic_survival["Age"]) / len(titanic_survival["Age"]) print (mean_age)运行结果:

-
正确的均值
age = titanic_survival["Age"] # print(age.loc[0:10]) age_is_null = pd.isnull(age) #we have to filter out the missing values before we calculate the mean. good_ages = titanic_survival["Age"][age_is_null == False] #print good_ages correct_mean_age = sum(good_ages) / len(good_ages) print (correct_mean_age)运行结果:

-
mean()
# missing data is so common that many pandas methods automatically filter for it correct_mean_age = titanic_survival["Age"].mean() print (correct_mean_age)运行结果:

-
计算不同类别的均值
#mean fare for each class passenger_classes = [1, 2, 3] fares_by_class = {} for this_class in passenger_classes: pclass_rows = titanic_survival[titanic_survival["Pclass"] == this_class] pclass_fares = pclass_rows["Fare"] fare_for_class = pclass_fares.mean() fares_by_class[this_class] = fare_for_class print fares_by_class运行结果:
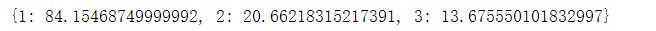
-
数据透视表 获救的比例
#index tells the method which column to group by #values is the column that we want to apply the calculation to #aggfunc specifies the calculation we want to perform passenger_survival = titanic_survival.pivot_table(index="Pclass", values="Survived", aggfunc=np.mean) print (passenger_survival)运行结果:

-
平均年龄
passenger_age = titanic_survival.pivot_table(index="Pclass", values="Age") print(passenger_age)运行结果:

-
一个量和两个量之间的关系
port_stats = titanic_survival.pivot_table(index="Embarked", values=["Fare","Survived"], aggfunc=np.sum) print(port_stats)运行结果:

-
dropna
#specifying axis=1 or axis='columns' will drop any columns that have null values drop_na_columns = titanic_survival.dropna(axis=1) new_titanic_survival = titanic_survival.dropna(axis=0,subset=["Age", "Sex"]) #print new_titanic_survival -
loc函数
row_index_83_age = titanic_survival.loc[83,"Age"] row_index_766_pclass = titanic_survival.loc[766,"Pclass"] print (row_index_83_age) print (row_index_766_pclass)运行结果:

pandas常用预处理方法

猜你喜欢
转载自blog.csdn.net/weixin_42260102/article/details/103428209
今日推荐
周排行