目录
整个系统是由多个不同部分组成的,每个部分都有可能出现问题,性能会受到不同部分的影响


进程管理
所有进程都通过task_struct结构体来管理的,一个进程描述符包含了单个进程在运行期间所有必要的信息
如进程标识,进程属性,构建进程的资源等


进程的生命周期
父进程fork出子进程,子进程调用exec将新的程序复制到子进程的地址空间,因为父子两个进程共享相同的地址空间,所以新程序写数据时会导致页错误,内核会给子进程分配新的物理页
这种延迟操作被称为Copy On Write
子进程结束后调用exit结束进程,会释放大部分数据并发送终止信号给父进程,此时进程是僵尸进程zombie process,直到父进程通过waitpid调用得知子进程已经结束,并移除所有子进程的数据结构,释放进程描述符

线程也被称为轻量级进程Light Weight Process LWP
在Linux操作系统中有如下几个线程实现
1.linuxThread,目前是默认的线程实现,但也有一些不富豪POSIX标准
2.Native POSIX Thread Library(NPTL),这个借口更符合POSIX标准,增加了新的clone()系统调用,信号处理
3.Next Generation POSIX Thread,由IBM开发的POSIX线程库版本,目前处于维护状态没有下一步计划
进程优先级和nice
Linux支持的nice级别从最低的19,到最高的-20

上下文切换和中断
执行的进程被加载到寄存器的数据集被称为上下文context,在切换过程中,先存储运行进程的上下文,然后将下一个要运行的进程的上下文恢复到寄存器。这个过程是上下文切换context switching,过多的上下文切换会频繁的刷新寄存器和高速缓存cache,会导致性能问题
硬件/软件中断会将当期进程切换到一个新的进程处理这个中断,也会导致上下文切换,过多的中断会导致性能问题
/proc/interrupts 中可以看到硬件相关的中断信息

进程状态,通过 man ps可以查看到进程有如下一些状态
PROCESS STATE CODES
Here are the different values that the s, stat and state output specifiers (header "STAT" or "S") will display to describe the state of a
process.
D Uninterruptible sleep (usually IO)
R Running or runnable (on run queue)
S Interruptible sleep (waiting for an event to complete)
T Stopped, either by a job control signal or because it is being traced.
W paging (not valid since the 2.6.xx kernel)
X dead (should never be seen)
Z Defunct ("zombie") process, terminated but not reaped by its parent.
For BSD formats and when the stat keyword is used, additional characters may be displayed:
< high-priority (not nice to other users)
N low-priority (nice to other users)
L has pages locked into memory (for real-time and custom IO)
s is a session leader
l is multi-threaded (using CLONE_THREAD, like NPTL pthreads do)
+ is in the foreground process group
僵尸进程,已经被认为是死亡的进程了,即使用kill -9也不能杀掉
父进程可以忽略SIGCHLD信号,子进程退出后init进程会回收相关的资源
父进程忽略SIGCHLD信号后,瞬间fork出1W个子进程,子进程都退出了然后父进程继续sleep,再ps观察发现子进程都没了,说明都被init进程给回收了

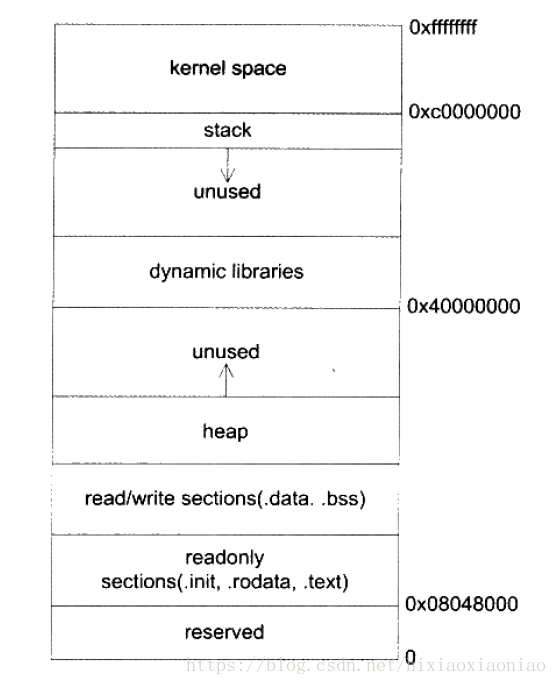
进程的内存段
操作系统内核对每个进程采用的是动态内存分配机制
文本段,用来存储可执行代码的区域
数据段,这个段由三个区域组成
数据,存储初始化数据,如静态变量
BSS,存储零初始化数据
堆,由malloc分配的内存,向高地址增长
栈段,在区域是局部变量,函数参数,返回的存储函数的存放区域,向低地址增长
中间一部分是动态链接库
用 pmap 命令可以查看进程的内存映射分布
CPU调度程序
O(1)调度模型中,每个CPU使用2个队列,一个运行队列和一个过期队列
调度程序根据他们的优先级将他们放到运行队列的进程列表中,需要调度时取出运行队列汇总最高优先级列表中的第一个进程并运行
调度程序基于进程的优先级和以前的阻塞率给进程分配一个时间片,当进程时间片用完后,进程调度程序将其移动到过期队列相应的优先级列表中,然后再取下一个具有最高优先级的进程,重复以上过程
一旦运行队列中不再有进程等待,调度程序就将过期队列转变为新的运行队列,之前的运行队列成为新的过期队列开始再次循环
新的调度程序支持非统一内存架构Non-Uniform Memory Architecture NUMA,和对称多处理器SMP
2.6内核还支持完全公平调度Completely Fair Scheduler CFS,它基于虚拟时间的红黑树
虚拟时间是基于进程等待运行的时间,竞争CPU的进程数量以及进程的优先级来计算的,一些病态的进程想伤害系统就很难了

内存体系结构
页帧分配
内核以内存页为单位处理内存,一个内存页通常是4KB大小,当一个进程请求一定数量内存页的时候,如果有有效的内存页则内核分配给该进程
否则需要从其他进程或分页缓存中得到
进程不能直接访问武力内存,只能访问虚拟内存,一个进程分配内存时,页帧的物理地址被映射到进程的虚拟地址
32位架构和64位架构的虚拟内存寻址布局

虚拟内存管理
应用程序向系统申请内存时,系统不会给应用程序分配物理内存,但会向内核请求一定大小的虚拟内存,并在虚拟内存中交换得到映射

伙伴系统
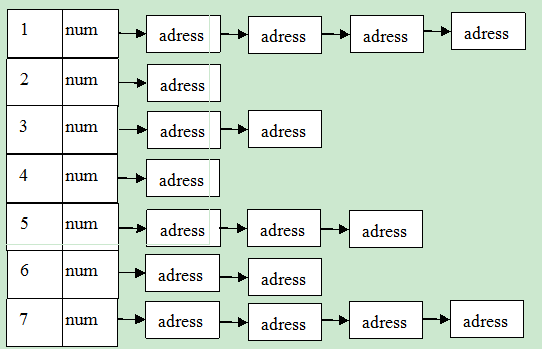
Linux中的内存管理的“页”大小为4KB。把所有的空闲页分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页块。最大可以申请1024个连续页,对应4MB大小的连续内存。每个页块的第一个页的物理地址是该块大小的整数倍。
结构如图所示:第i个块链表中,num表示大小为(2^i)页块的数目,address表示大小为(2^i)页块的首地址。
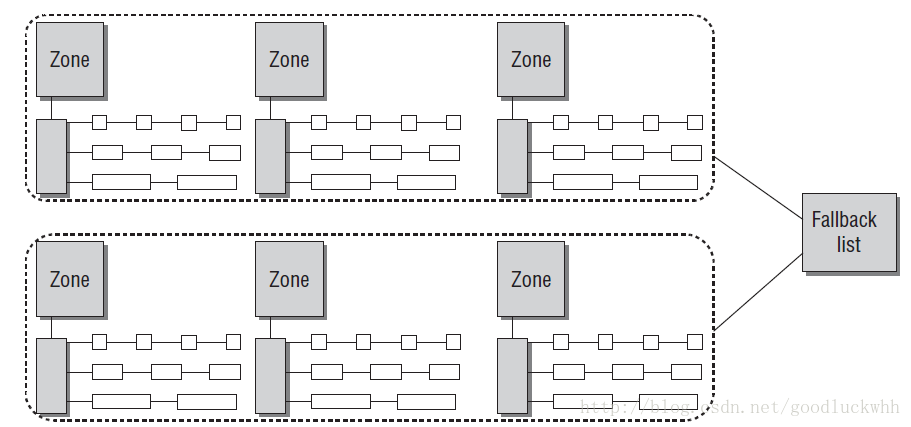
从另一个视角看伙伴系统
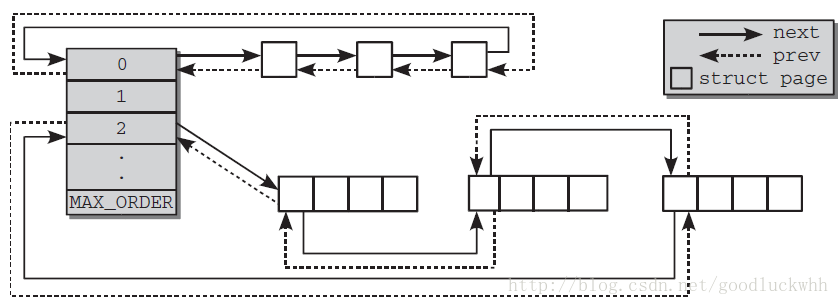
基于伙伴系统的内存管理方式专注于内存节点的某个内存域的管理,但是系统中的所有zone都会通过备用列表连接起来
系统中伙伴系统的当前信息可以通过 /proc/buddyinfo 查看
分页回收
内核根据页的可移动性将其划分为3种不同的类型:
不可移动的页:在内存中有固定位置,不能移动。分配给核心内核的页大多是此种类型
可回收的页:不能移动,但是可以删除,其内容可以从某些源重新生成。
可移动的页:可以随意移动。属于用户进程的页属于这种类型,因为它们是通过页表映射的,因而在移动后只需要更新用户进程页表即可
kswapd在任务中通常处于可中断睡眠状态,当区域中的空闲分页低于一个阈值后使用LRU将这个页释放掉
kswapd扫描活跃页列表,并坚持最近使用的分页,将最近没有使用的分页放入非活跃页列表中
通过 vmstat -a 命令查看活跃和非活跃的内存多少
一些不常用的守护进程如 getty,可能会被放到swap,如果swap使用了50%页不一定表明内存瓶颈,反而正面是内核在有效的利用系统资源
文件系统
虚拟文件系统VFS
虚拟文件系统是驻留在用户进程与各种类型的Linux文件系统之间的一个抽象接口层
VFS提供了访问文件系统对象的通用对象模型,如索引节点,文件对象,分页缓存,目录条目等
它对用户进程隐藏了实现每个文件系统的差异,有了VFS用户进程不需要知道系统使用的是哪一个文件系统,为每个文件系统运行哪一个系统调用

文件系统日志
对一个文件执行执行写操作时,内核首先改变文件系统的元数据(metadata),然后再写实际的用户数据,这个操作有时候会损害数的完整性
在对元数据写过程中如果系统崩溃了,则文件系统的一致性会被破坏,fsck可以修复不一致并在下次重启时恢复,但文件系统太大就需要很长时间恢复
日志文件可以解决这个问题,先写入日志文件再写入系统文件,这也会损失性能

Ext2
Ext2文件系统以引导扇区开始,接下来是块组,将整个文件系统分成若干个小的块组有助于提高性能,因为他可以将用户数据的索引节点 i-node 表和数据块更紧密的保存在磁盘盘片上,因此可以减少寻道时间,一个块组包含以下项目
1.超级快Super Block,文件系统的信息存储在这里,超级快的精确部分被防止在每个块组的顶部
2.块描述符Block group descriptor,块组上的信息被存储在这里
3.数据块位图Data block bitmaps,用户空闲数据块管理
4.索引节点位图I-node bitmaps,用于空闲节点的管理
5.索引节点表I-node tables,索引节点表存储在这里,每个文件有一个相应的索引节点表,其中保存
了文件的元数据,比如文件模式,uid,gid,atime,ctime,mtime和到数据块的指针
6.数据块Data Block

要查找/var/log/message过程
先查找根目录/,kernel会解析文件路径,搜索/ 的目录条目,该目录条目中有他下面文件和目录的新兴,接着找/var,然后是/var/log,最后找到message文件
内核使用一个文件对象缓存,比如目录条目缓存或者索引节点缓存来加速查找符合条目的索引节点

Ext3
支持日志功能,用 mount命令生命日志的模式
通过tune2fs命令和编辑/etc/fstab文件,可以将Ext2系统更新到Ext3文件系统
日志模式包含
1.全日志journal,元数据和实际数据都被写入日志区,然后再写入主文件系统,但效率不高
2.顺序ordered,元数据写入到日志区,再将元数据和实际数据写入文件系统
3.回写writeback,将元数据写入日志区,实际数据写入到主文件系统中
Ext4兼容Ext3,增加伸缩性,支持最大文件系统为1024PB
使用区段提高了分配性能,在线磁盘碎片整理
其他文件系统
XFS,Btrfs,JFS,ReiserFS
磁盘I/O子系统
磁盘执行写入操作时的基本操作
1.一个进程通过write()系统调用请求写一个文件
2.内核更新已映射的分页缓存
3.内核线程pdfulsh/per-BDI flush将分页缓存刷新到磁盘
4.文件系统层同时在一个bio(block input outpu)结构中防止每个块缓冲,并向块设备层提交写请求
5.块设备层从上层得到请求,并执行一个I/O电梯操作,将请求放置到I/O请求队列
6.设备驱动器(如SCSI或其他设备特定的驱动器)将执行写操作
7.磁盘设备固件执行硬件操作,如在盘片扇区上定位磁头,旋转,数据传输

存储器的层次结构

局部性locality of reference
大多数最近使用过的数据,在不久将来有较高的几率被再次使用(时间局部性)
驻留在数据附近的数据有较高的几率被再次使用(空间局部性)

刷新脏页
进程首先在内存中改变数据,这时磁盘和内存中的数据是不相同的,并且内存中的数据被称为脏页dirty page,如果系统突然崩溃,则内存中的数据会丢失
同步脏数据缓冲的过程被称为刷新,2.6内核中Per-BDI flush线程检查到当脏页到达某个阈值时就会发生刷新flush

块层
块层处理所有与块设备操作相关的活动
块层中的关键数据结构是bio(block input outpu)结构,bio结构是在文件系统层和块层之间的一个接口
当执行写的时候,文件系统层试图写入由块缓冲区构成的页缓存,它通过防止连续的块在一起构成bio结构,然后将其发送到块层
块层处理bio请求,并链接这些请求进入一个被称为I/O请求的队列,这个链接的操作被称为I/O电梯调度器I/O elevator,有4种不同的调度算法
1.CFQ complete Fair Queueing完全公平队列,默认的I/O调度器
2.Deadline,循环电梯调度器round robin
3.NOOP
4.Anticipatory
I/O设备驱动程序
内核使用设备驱动程序得到设备的控制权,设备驱动程序通常是一个独立的内核模块,他们通常针对每个设备(或者设备组)而提供,以便这些设备在系统上可用,一旦加载了设备驱动程序,它将被当做内核的一部分运行,并能控制设备的运行
SCSI small Computer System Interface,小型计算机系统接口是最常使用的I/O设备技术,尤其在企业级服务器环境中,SCSI包含以下模块类型
1.Upeer level drivers上层驱动程序,sd_mod,sr_mod,st(SCSI Tape)和sq(SCSI通用设备)
2.Middle level drivers中层驱动程序,如scsi_mod。其实现了SCSI协议和通用SCSI功能
3.Low level drivers底层驱动程序,其提供对每个设备的较低级别访问,底层驱动程序基本上是特定
于某一个硬件设备的,可提供给某个设备,如IBM ServerRAID controller的ips等
4.Pseudo drive伪驱动程序,如ide-scsi

磁盘条带阵列RAID
需要考虑如下内容
1.文件系统使用的块大小,块的大小指可以读取/写入到驱动器的最小数据量
2.计算文件系统stride与stripe-width,如果文件系统块大小为4KB,则cheunk大小为64KB,则stride为64/4=16块
创建文件系统时可以使用mkfs给定数量
mke2fs -t ext4 -b 4096 -E stride=16,stripe-width=64 /dev/san/lun1
网络子系统
网络分层结构和网络操作
网络数据传输的基本操作
1.应用程序发送数据到对等主机的时候,创建数据
2.调用socket函数,并写入数据
3.socket缓冲区被用来处理传输数据,socket缓冲区引用数据,并向下穿过各层
4.在每一层中,执行适当的操作,比如解析报头,添加和修改报头,校验和,路由操作,分片等,当
socket缓冲区向下穿过各层时,在各层之间的数据自身是不能够复制的,因为在不同层之间复制实际
数据是无效的,内核仅通过改变在socket缓冲区中的引用来避免不必要的开销并传递到下一层
5.网络接口卡向线缆发送数据,当传输时增加一个中断
6.以太网帧到大对等主机的网络接口卡
7.如果MAC地址匹配接口卡的MAC地址,将帧移动到网络接口卡的缓冲区
8.网络接口卡最终将数据包移动到一个socket缓冲区,并发出一个硬件中断给CPU
9.CPU之后处理数据包,并使其向上穿过各层,直到它到达一个应用程序的TCP端口如Apache

socket buffer相关的参数调整
/proc/sys/net/core/rmem_max
/proc/sys/met/core/rmem/default
/proc/sys/net/core/wmem_max
/proc/sys/net/core/wmem_default
/proc/sys/net/ipv4/tcp_mem
/proc/sys/net/ipv4/tcp_rmem
/proc/sys/net/ipv4/tcp_wmemsocket缓冲区内存分配

传统的方式每次一个匹配MAC地址的以太网帧到达接口,都会产生一个硬件中断,CPU每处理一个硬件中断都要停止当前工作导致上下文切换,
引入NAPI后,对于第一个数据包还是跟传统一样触发一次中断,但之后接口就进程轮询模式,只要有数据包放入网络接口的DMA环形缓冲区,不会引起中断减少了上下文切换的开销,等最后一个数据包处理完后缓冲区被清空,接口卡再次退回到中断模式
Netfilter
内核的一个模块可以提供防火墙功能,包括
1.数据包过滤,满足一定条件后就接受或拒绝该数据包
2.地址转换,如果匹配则更改数据包
3.改变数据包,如果匹配则对数据包进行修改,如ttl,tos,mark等
可以通过以下属性来匹配过滤器
网络接口,IP地址-IP地址范围-子网,协议,ICMP协议,端口,TCP标志,状态
满足条件后的目标行动有
1.ACCEPT
2.DROP
3.REJETC,通过发送回一个错误数据包来响应匹配的数据包,如imcp-net-unreachable等
4.LOG,开启内核日志记录匹配到数据
5.MASQUERADE,SNAT,DNAT,REDIRECT

TCP/IP的三次握手

TCP连接状态图

滑动窗口和延迟ACK

Offload
支持Offload的硬件,内核可以分出一部分给适配器
checksum,IP/TCP/UDP执行校验,通过比较协议头部中的checksum字段的值和计算数据包中的数据的
值,确保数据包被正确传输
TCP segmentation offload,TSO TCP分段offload,当大于支持的最大传输单元MTU数据发送到网络
适配器时,数据应该被分成MTU大小的数据包
Bonding模块
多个网卡使用同一个IP,提高集群节点的数据传输