目录
Linux性能度量标准
处理器度量标准
1.CPU使用率
2.用户进程消耗CPU的时间
3.内核操作消耗CPU的时间,包括IRQ和softirq时间
4.等待,等待上的时间总量,比如io等
5.CPU空闲时间
6.nice消耗CPU时间
7.平均负载,正在处理的进程和不可中断进程综合的平均值
8.可运行的进程,可运行的进程数量不应超过处理器数量的10倍
9.阻塞的进程
10.上下文切换
11.中断
内存度量标准
1.空闲内存,从已使用used的内存中减去缓冲buffer和缓存cache的内存数量即空闲的
2.使用的swap,需要关注in和out的值,每秒200-300换入换出就有瓶颈了
3.Slab,内核使用的内存数,内核的分页不能移出磁盘
4.活跃和非活跃内存,非活跃内存可能是kswapd守护进程swap out到磁盘的候选者
块设备度量标准
1.I/O等待
2.平均队列长度,未完成的I/O请求数量,磁盘有2-3个队列是最佳的
3.平均等待时间,服务一个IO请求所测量的平均时间
4.每秒传输,每秒钟多少个I/O操作被执行(读和写)
5.每秒读取/写入块的数量
6.每秒读取/写入的字节
网络接口度量标准
1.接收和发送的数据包
2.接收和发送的字节
3.每秒钟冲突的数量,如果持续冲突则要关注网络基础设施而不是服务器
4.丢弃的数据包
5.溢出,网络接口溢出缓冲区空间的次数,集合数据包被丢弃的值使用,来确定网络缓冲区或是网络
队列长度出现瓶颈
6.错误,通常是网络不匹配或是网络电缆中断导致的
了解系统的硬件配置
CPU
1.CPU(S)模式是什么,处理器的架构是哪一个,使用什么主板芯片?
2.有多少个插口,每个CPU有多少核心?如果支持超线程那么每个核心上有多少线程,每个插口socket如何连接
的,数据速率是多少 QPI HyperTransport FBS
3.CPU的每个层级的cache有多大,cache是核心私有的还是与socket上的其他核心共享的,或者与一个系统中
其他socket共享的,cache是如何被组织和访问的?
4.处理器支持哪些特征,处理器支持硬件虚拟化吗,处理器的架构是32bit还是64bit?是否有其他的特殊
指令或者功能?
内存
1.系统有多少内存?硬件允许的最大数量的内存是多少?
2.系统使用的内存技术是什么?它有什么带宽和延迟?
3.系统的内存是如何被连接的,荣国一个Northbridge和前端总线或者直接接到CPU,是SMP或NUMA吗?
如果是NUMA节点使用什么技术,当访问不用渔区的内存时会有什么影响
存储
1.附加在系统上的存储设备是什么类型的,实际设备是什么模型?他们是基于旋转的磁盘片的传统硬件,
还是固态硬件solid-state diskSSD驱动器?
2.传统的硬盘,它们有没有寻址时间和旋转延迟?你期待的最大化带宽和延迟是多少,访问驱动器不同
分区的速度变化是多少?
3.SSD驱动器,他们使用的闪存是MLC还是SLC?他们支持TRIM吗,如何有效的对他们的耐久性和垃圾收集
系统进行测量?
4.磁盘阵列,已使用的硬件RAID级别是什么?在一个阵列里有多少个存储设备?RAID级别是条带,在
阵列中每个条带的大小是多少?
5.直连式存储使用什么进行互连SATA,SAS或其他,他是怎么连接主板到系统的其他部分呢,是否有充足的
带宽让所有的设备支持通讯的连接?
6.SAN设备,使用Fibre Channel或者iSCSI越过以太网?SAN设备的带宽和延迟是多少?多路径SAN设备,
基于可用路径的性能变化几何?
网络
1.系统上可用的网络接口卡是什么?使用的网络技术是什么?(以太网,无限带宽技术等)?
2.对机器来说什么网络是可用的或需要的?什么是VLAN?如何大量利用这些网络?他们有特殊用途
吗(存储网络,带外管理等)?他们运转的速度是多少?
3.我们需要特别的能力吗(列如I/O虚拟化可以将一个网卡划分成多少vNIC作为系统上的guest虚拟机)?
一些系统命令
通过查看dmesg缓冲区
1.回顾启动时的硬件检测
2.观察显示出的硬件连接或检测的信息
3.观察显示出的警告或错误情况发生的信息
当前dmesg缓冲区的内容到/var/log/dmesg中
lscpu -p 查看cache的共享信息
x86inifo 命令
查看机器硬件相关信息的命令 dmidecode
这些信息再 /sys/class/dmi/id 中
chkconfig 检测守护进程信息
service 启动/停止守护进程
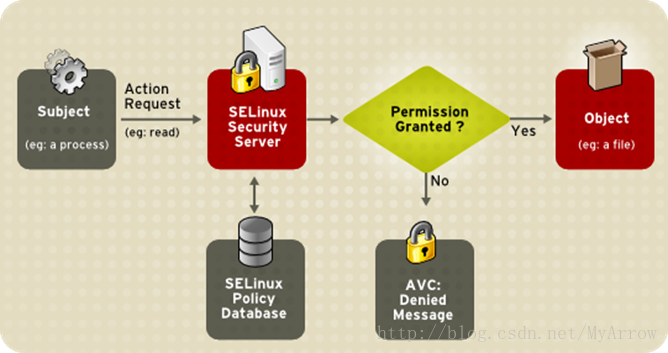
SELinux
Security Enhanced Linux,引入强制访问策略模式克服了linux使用的标准自主访问模式的局限性
在用户和进程级别上强制安全性,所以任何特定进程的安全漏洞,只影响分配给这个进程的资源,而不是整个系统
SELinux必须控制I/O是被,检查权限过程中会导致10%的开销
编辑grub.conf文件禁用SELinux
或者编辑/etc/selinux/config禁用
SELINUX=disabled
proc目录
1.数字1-X,运行的进程各自pid的目录
2.Acpi,现代桌面和笔记本系统支持的高级配置和电源接口
3.bus,综合子系统的信息,比如PCI总线或各自系统的USB接口
3.irq,中断相关的信息
4.scsi,各自系统的SCSI子系统信息
5.sys,可调整的内核参数,比如虚拟内存管理器或网络协议栈的行为
6.tty,虚拟中断和连接的物理设备的信息
/proc/sys/abi, 包含文件与应用程序二进制信息
/proc/sys/debug
/proc/sys/dev, 特定设备的信息
/proc/sys/fs, 特定的文件系统,文件句柄,inode,dentry和配额调优
/proc/sys/kernel,用来控制内核的参数
/proc/sys/net, 内核网络部分的调整
/proc/sys/vm, 内管管理调优,包括buffer和cache管理等
通过 sysctl 命令也可以调整参数
调整处理器子系统
chrt 命令用来调整进程的调度策略
nice和renice 调整进程的运行级别,从19(最底优先级) 到 -20(最高优先级)
taskset 设置进程的CPU亲和力
cgroup
cpuset.cpus 在cgroup中可以使用的CPU,可以是一个范围
cpuset.mems,可以使用哪一个NUMA内存区域
cpuset.{cpu,memory}+exclusive,如果希望这个cgroup中的CPU/内存是独有的可设置为1
中断interrupt
这是一个来自硬件或者软件的信息
中断有时候被称为IRQ interrupt request
/proc/interrupts 描述了再一个特定的CPU上处理特定的中断情况
确定内核在哪个CPU上执行特定的中断处理程序,可以查看/proc/irq/number/smp_affinity 掩码文件
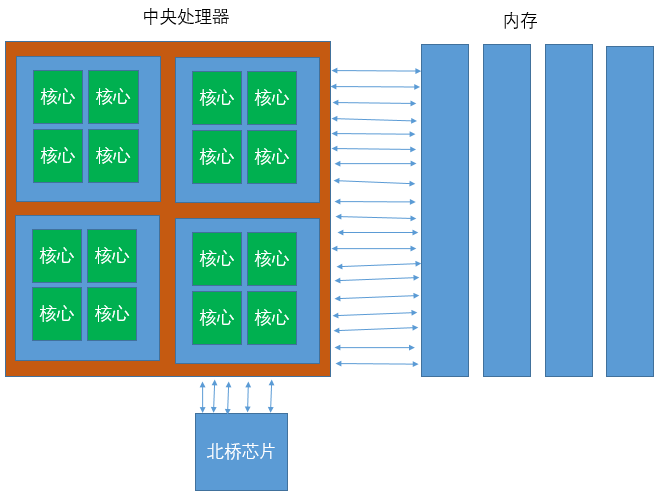
NUMA系统
最早的多处理器系统是就对称多处理器结构 Symmetric Multiprocessing SMP 设计的
每个CPU核心通过一个共享总线访问系统RAM
这就是一个统一的内存架构 Uniform Memory Architecture UMA系统
随着处理器增多这种系统就会出现瓶颈,下图是SMP系统的架构图
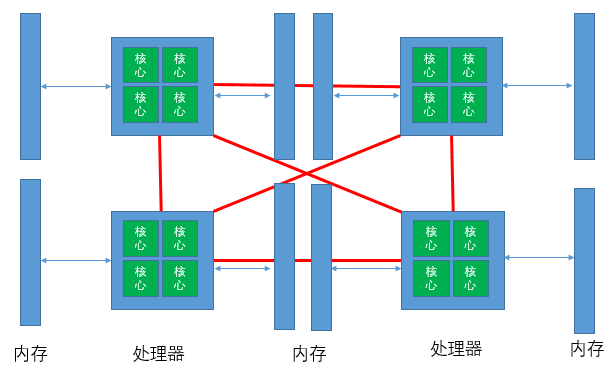
Non Uniform Memory Architecture NUMA 非统一内存架构
这些基于NUMA系统的主存储器通过单独的总线直接连接到单独的处理器或CPU封装
numastat 工具用于识别NUMA架构中处理困难的进程
/sys/devices/system/node/%{node_number}/numastat 文件中可以看到 numastat工具所提供的统计数据
另一个命令 numactl
调整内存子系统
大多数应用程序不会直接写入硬盘,他们通过虚拟内存写入到文件系统cache,最终将数据刷新出来
物理内存需要时不时被回收,以防止内存填满导致系统不可用
内存分页状态
| Free | 分页是有效的,可立刻分配 |
| Inactive Clean | 分页没有活跃使用,内容符合磁盘上的内容,因为它已经被写回或自读以来没有改变 |
| Inactive Dirty | 分页没有活跃使用,但是自从磁盘上读依赖分页内容已经被修改,还没有被写回 |
| Active | 分页在活跃使用中,并不能作为一个可释放的候选者 |
对于每个进程的视图可以查看 /proc/PID/smaps,这个文件描述了分配给一个进程的每个内存段,包含了Shared/Private clean大小,脏数据内存大小等当需要分配一个新的分页的时候,分页被标记为Inactive clean,即可以被视为空闲分页,但如果拥有该分页的进程之后再次需要分页,将会发生一个主要页错误(major page fault)
通过查看/proc/meminfo 可以得到整个系统的内存分配概况,我们关注的是Inactive(file)和Dirty
Anonymous page(那些与磁盘上的文件不相关的)不能轻易释放,并且需要换出到磁盘释放他们
相关脏数据内核参数
| vm.dirty_expire_centisecs | 经过多久(百分之一秒)脏数据才有资格写入到磁盘,防止仅仅因为进程修改了内存的一个字节,而导致内核快速连续的对相同分页进行多次写 |
| vm.dirty_writeback_centisecs | 内核多长时间唤醒flush线程来一次写入数据,设置0将完全禁用周期的写回 |
| vm.dirty_background_ratio | 脏数据达到系统总内存百分比,内核开始在后台写数据 |
| vm.dirty_ratio | 一个进程所拥有的臧姝达到系统总内存的百分比,该进程产生写阻塞,并写出脏页 |
/proc/PID/maps和/proc/PID/smaps都是关于进程内存段映射信息的
当内存不足时候 OOM killer会决定杀死哪个进程,每个进程都有一个运行不良分数
对应的是/proc/PID/oom_score 文件
有许多因素来计算这个分数,虚拟内存大小,进程包括所有子进程积累的虚拟内存大小,nice值,总共运行时间,运行的用户等
init对OOM killer是免疫的
可以调用/procPID/oom_adj 来调整 oom_score,最高是-17,最低是15
echo f > /proc/sysrq-trigger 会至少杀死一个进程,信息输出到 dmesg中
当内核想释放内存中的一个分页时,有两种选择
1.从进程的内存中换出一个分页
2.从分页cache中丢弃一个分页
内存计算方式如下
swap_tendency = mapped_ratio/2 + distress + vm_swappiness
如果swap_tendency低于100内核将从分页cache中回收一个分页
如果大于等于100,一个进程内存空间中的一部分将有资格获得交换
调整vm.swappiness可能会影响性能
mapped_ratio是物理内存使用的百分比,distress是衡量内核在释放内存中有多少开销
/proc/sys/vm/swappines 中的参数可以用来定于如何 将内存交换到磁盘上
机械硬盘应该避免过多交换,SSD可以多使用交换,但注意避免被频繁的写,以免写入放大
可以使用mkswap将磁盘上的空闲分区创建为一个swap分页,如果磁盘子系统没有空闲可用,可以创建一个swap文件
有限创建swap分区,这样I/O就绕过了文件系统和所有涉及写入一个文件的开销,mkswap 命令创建swap分区
可以创建多个swap分区,并行读取提高性能
cat /etc/fstab
swap空间分配参考
| 系统物理内存 | 建议最小swap空间 |
| 4G以内 | 至少2G |
| 4G-16G | 至少4G |
| 16G-64G | 至少8G |
| 64G-256G | 至少16G |
在分页表中有一个虚拟地址到物理地址的映射,这个转换是由一个专门的硬件完成的,叫TLB
CPU的旁路转换缓冲(Translation Lookaside Buffer)TLB是一个很小的cache,用来存储虚拟地址到物理地址的映射信息,但他的大小是固定的,更大的分页使得的TLB可以装下更多的映射条目
通过下面命令查看系统的TLB信息
x86info -a
通过/proc/meminfo查看大分页相关的信息
调整hugepage参数
/proc/sys/vm/nr_hugepages
通过命令调整
sysctl -w vm.nr_hugepage=512
新的Linux支持动态调整巨型分页
/sys/kernel/mm/redhat_transparent_hugepage/enabled
内存同页合并
通过后来进程将一些完全相同的分页到一个分页中,安装KSM服务并配置
调整磁盘子系统
一旦操作系统的cache和磁盘子系统的cache不能再容纳读/写请求的大小或数量,物理量磁盘就必须工作
假设一个磁盘驱动器每秒能处理200个I/O,有一个应用程序,在文件系统上执行4KB的随机位置写请求,因此不能
选择流或请求合并,最大的吞吐量是
200 * 4KB = 800KB
Linux分区和服务器环境
| 分区 | 内容和可能的服务器环境 |
| /home | 分理出home到自己的分区对于文件服务器有好处,这是系统上所有用户的根目录,如果没有实现磁盘配额,那么分离这个目录是为了隔离用户对磁盘空间的失控使用 |
| /tmp | 如果在高性能计算环境中运行,那么在计算时需要大量的临时空间,然后完成释放 |
| /usr | 这是防止内核源码树和Linux文档的位置,/usr/local目录存储的可执行文件必须可以被系统上的所有用户访问,并且是一个很好的位置用来存储为你环境开发的自定义脚本,如果他被分离到他自己的分区,那么在升级或重新安装时通过简单的选择不需要重新格式化的分区,文件不会被重新安装 |
| /var | 在邮件,网站,打印服务器环境中非常重要,他保护了这些环境的日志文件和整个系统的日志,长期的消息可以填满这个分区,如果发生这种情况,并且此分区没有从/ 中分离出来,则服务器可能会中断,根据不同的环境,可能要进一步分离这个分区,做法是在邮件服务器上分离出/var/spool/mail,或相关系统日志的/var/log |
| /opt | 安装的一些第三方软件,如Oracle数据库服务器默认使用这个分区,如果没有分离,安装将在/ 下继续,如果不能分配足够的空间,可能会失败 |
4种I/O调度算法相关的内核参数
| /sys/block/sda/queue/nr_requests | 磁盘队列长度。默认只有 128 个队列,可以提高到 512 个.会更加占用内存 ,但能更加多的合并读写操作,速度变慢,但能读写更加多的量 |
| /sys/block/sda/queue/read_ahead_kb | 这个参数对顺序读非常有用,意思是,一次提前读多少内容 |
| /proc/sys/vm/dirty_ratio | 这个参数控制文件系统的文件系统写缓冲区的大小,单位是百分比,表示系统内存的百分比,表示当写缓冲使用到系统内存多少的时候,开始向磁盘写出数 |
| /proc/sys/vm/dirty_background_ratio | 这个参数控制文件系统的pdflush进程,在何时刷新磁盘.单位是百分比,表示系统内存的百分比,意思是当写缓冲 使用到系统内存多少的时候,pdflush开始写磁盘 |
| /proc/sys/vm/dirty_writeback_centisecs | 这个参数控制内核的脏数据刷新进程pdflush的运行间隔.单位是 1/100 秒.缺省数值是500,也就是 5 秒 |
| /proc/sys/vm/dirty_expire_centisecs | 这个参数声明Linux内核写缓冲区里面的数据多“旧”了之后,pdflush进程就开始考虑写到磁盘中去.单位是 1/100秒.缺省是 30000,也就是 30 秒的数据就算旧了,将会刷新磁盘 |
使用 ionice 命令分配I/O优先级,支持3种优先级
1.Idle,分配给I/O优先级为idle的进程,只有在没有其他Best-effort(尽力而为)或更高优先级的进程请求
访问数据时,才给其授权访问磁盘子系统,这个设置对于人物非常有帮助,尤其当系统有空闲资源的时候
2.Best-effort,默认所有不要求特定I/O优先级的进程被分配到这一类,进程将继承他们各自的CPU的nice
优先级为8到I/O优先级
3.Real time,最高可以I/O优先级是realtime,这意味着进程各自将总在给定优先级下访问磁盘子系统,
real time优先级也可以设置优先级别为8,应小心适应,当给其分配一个线程real_time优先级的时候,这个
进程可能导致其他任务等待
访问时间也是一个开销,但禁用文件访问更新只会产生一个非常小的系统性能提升
使用noatime选项挂在文件系统防止访问时被封信
选择日志文件模式
data=journal,这个模式将文件数据和元数据全部记录到日志中,有最高一致性但开销也高
data=ordered(default),这个模式只记录元数据,但保证文件数据先被写入
data=writeback,提供最快的数据访问,但系统崩溃后可能出现数据不一致
通过mount命令可以修改
或者修改/etc/fstab 文件
默认的块大小是4KB
如果服务器处理大量小文件,那么小块将有效
如果是处理大量的大文件,则较大的块能提高性能
需要重新格式化后才能改变当前块大小,根据测试改变块大小提升性能并不大
虚拟化存储
调整网络子系统
网络子系统会影响到其他子系统
如果数据包太小,CPU使用率会受到明显的影响
如果有过多的TCP连接,内存使用会增加
网络绑定
通过使用bonding驱动程序,内核提供网络接口聚合的能力,这是一个与设备不相关的bonding驱动程序
可以实现负载均衡和容错,实现了更高层次的可用性和性能改善
支持模式
1.balance-rr,使用bond中所有的网卡,提供容错并基本负载均衡
2.active-backup,仅使用bond中的一个网卡,当活跃当地网卡出故障时,另外网卡接管
巨帧
一个普通的TCP连接使用的协议报头是40字节,默认的MTU是1500字节,有2.7%的容量损失
切换到UDP模式,报头从40减到28,容量损失是1.9%
有些设备可能不支持巨型帧
官方巨型帧最大是9000字节
40字节报头,9000字节MTU,容量损失是0.44%
速度与双工模式
网络吞吐量依赖于很多因素,使用的网卡,布线的类型,在一次连接中的跳数,发送的包大小
提高网络性能最简单的方法之一是检测网络接口的实际速度,因为问题可能在网络组件(比如交换机)和网络接口卡之间
通过命令
ethtool eth0 检查
增加网络缓冲区
| 基于系统内存自动计算出初始的整个tcp内存 | /proc/sys/net/ipv4/tcp_mem |
| 设置接收socket的内存默认值和最大值到一个更高的值 | /proc/sys/net/core/rmem_default /proc/sys/net/core/rmem_max |
| 设置发送socket的内存默认值和最大值搞一个更高的值 | /proc/sys/net/core/wmem_default /proc/sys/net/core/wmem_max |
| 调整内存buffers的最大值搞一个更高的值 | /proc/sys/net/core/optmem_max |
调整带宽延迟乘积 BDP(bandwidth delay product)
BDP = Bandwidth(bytes/sec) * Delay(or round trip time) (sec)
假设ping的往返延迟是10.509ms=0.010594s,假设网络速度是1Gb/s
1Gb/s * 10.509ms = 10^9b/s * 0.0105094s = 10594000 bits * 1/8 B/b
= 1324250Bytes = 1294.21KB
设置操作系统对于多个协议队列最大发送buffer大小wmem和接受buffer大小rmem
增加允许未处理数据包的数量
cat /proc/sys/net/core/netdev_max_backlog
增加传输队列长度,可以通过ip 命令调整
配置offload
一些网络操作可以从网络接口设备offload,使用
ethtool -k eth0查看
offload会使得CPU使用率降低,网络会计算大数据包的校验和
但网卡开启了offload之后对网卡本身也有影响,处理的数据包能力会下降
Netfilter对性能的影响
Netfilter提供TCP/IP连接跟踪和数据包过滤功能,在某些情况下可能产生较大的ing能影响
尤其是当连接建立的时候数量较高的时候
Netfilter的性能影响取决于以下因素
1.规则的数量
2.规则的顺序
3.规则的复杂性
4.连接跟踪级别(取决于协议)
5.Netfilter内核参数配置
流量特性的注意事项
网络性能优化最重要的考虑因素之一是要尽可能准确的了解网络流量模式
性能变化取决于网络流量特征
应该熟悉以下网络流量特征和要求
1.事务吞吐量的要求(峰值,平均值)
2.数据传输吞吐量的要求(峰值,平均值)
3.延迟的要求
4.传输数据的大小
5.发送和接受的比例
6.连接建立和关闭的频率或并发连接的数量
7.协议(TCP,UDP,应用程序协议,如HTTP,SMTP,LDAP等)
使用netstat,ss,tcpdump,wireshark分析
调整IP和ICMP行为
1.禁用参数,防止黑客针对服务器的IP地址进行欺骗攻击
2.忽略来自网关机器的重定向
3.不接受任何ICMP重定向,ICMP重定向是路由器传达路由信息到主机的一种机制
4.如果主机不充当路由器就不必发送重定向可以禁用
5.忽略广播ping和smurf攻击
6.忽略所有icmp类型的数据包或ping包
7.忽略无效的广播帧
8.设置IP碎片的最大和最小内存,碎片会被放到内存中被重新组装
调整TCP行为
1.对于WEB付我钱,TIME-WAIT 可以被连接重新使用
2.服务器关闭socket时,tcp_fin_timetou参数设置在FIN_WAIT-2状态下保存socket的时间
3.减小keepalive的时间
4.调整backlog队列大小
5.启动TCP SYN cookies
调整TCP选项
1.对于局域网可以禁用tcp_sack和tcp_dsack
2.每一个以太网帧被转发到内核网络堆栈时,会接受一个时间戳,对时间不敏感的服务可以禁用这个时间戳
3.窗口缩放可以是扩大传输窗口的一个选项,但系统遇到非常高的负载时窗口缩放不合适,可以禁用或手动调整
限制资源使用
如何通过最简单的设置来实现最有效的性能调优,如何在有限资源的条件下保证程序的运行,限制某些用户或进程访问资源,对性能优化来说就成为了很有用的策略
使用 ulimit命令限制资源
通过ulimit -a查看能限制的资源和资源当前状态
通过pam_limits.so 资源限制模块,并修改 /etc/security/limits.conf 文件
CGroup
Control Group提供一种机制将任务(进程)和子任务(子进程)聚合/划分到有特定行为的层次组中,在控制器中细分资源(如CPU时间,内存,磁盘I/O等),再层次化地分开
cgroup也是LXC为实现虚拟化所使用的资源管理手段,没有cgroup就没有LXC
cgroup针对一个或多个子系统将一组任务与一组参数关联在一起
子系统是一个模块,利用cgroup提供的任务分组功能以特定的方式视其为任务组,子系统通过是一个资源控制器,调度一个资源或按cgroup应用限制,他可能是想要作用于进程租上的任何事,如一个虚拟化子系统
所谓层次结构就是以树形结构对一组cgroup进行分组,这样系统中的每个人物将正确的位于层次结构中的其中一个cgroup和一组子系统,在层次结构中每个子系统将特定的系统状态附加到每个cgroup中,每个层次结构都有一个cgroup虚拟文件系统的实例与其相结合
cgroup子系统
| Blkio | 对块设备的I/O进行控制 |
| Cpu | 用来控制进程调度,设置进程占用CPU资源(时间片)的比重 |
| cpuacct | 使用cgroups分组任务,并统计这些任务的CPU使用 |
| Cpuset | 提供了为一组任务分配一组CPU和内存节点的机制 |
| devices | 实现了跟踪和执行open和mknod设备文件的限制 |
| freezer | 对于批处理作业管理是很有用的,可以根据管理员的需求启动和停止任务,从而调度机器的资源 |
| Memory | 隔离并限制进程租对内存资源的使用 |
| net_cls | 使用类登机识符(classid)标记网络数据包,可使用流量控制器TC 为来自不同cgroups的数据包分配不同的优先级 |
相互关系
1.每次在系统中穿件新层次结构时,该系统中的所有任务都是该层次结构的默认cgroup,称之为root cgroup,此cgroup在创建层次结构时自动创建,后面在该层次结构中创建的cgroup都是此cgroup的后代
2.一个子系统最多只能附加到一个层次结构
3.一个层次结构可以附加到多个子系统
4.一个任务可以是多个cgourp的成员,但是这些cgroup必须在不同的层次结构
5.当系统中的进程(任务)创建子进程(任务)时,该子任务自动成为其父进程所在cgroup的成员,然后可以根据需要将该子任务移动到不同的cgroup中,但开始时他总是继承其父任务的cgroup
使用cgcreate创建cgroups
使用mkdir创建cgroup,通过rmdir或cgdelete移出
使用mount挂在一个虚拟cgroups文件系统
在/etc/cgconfig.conf中配置cgconfig建立cgroup层次结构
为cgroup设置限制
给cgroup分配进程
参考
Linux NUMA引发的性能问题?linux上swap的查看与调整