一、CPU上下文切换
1、CPU上下文
Linux是多任务操作系统,支持远大于CPU数量的任务同时运行。在每个任务运行前,CPU需要知道任务从哪里加载、从哪里开始运行,即需要系统事先为CPU设置好CPU寄存器和程序计数器(Program Counter,PC)。CPU寄存器是CPU内置的容量小、但速度极快的内存,程序计数器是用来存储CPU正在执行的指令位置、或者即将执行的下一条指令位置。CPU寄存器和程序计数器是CPU运行任何任务前必须的依赖环境,即CPU上下文。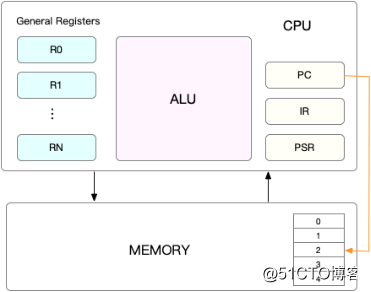
CPU上下文会存储在系统内核中,并在任务重新调度执行时再次加载进来,保证任务原来状态不受影响,保持多任务的连续运行。
CPU上下文切换是先把前一个任务的CPU上下文(CPU寄存器和程序计数器)保存起来,然后加载新任务的上下文到CPU寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
根据任务的不同,CPU上下文切换分为进程上下文切换、线程上下文切换、中断上下文切换。
2、进程上下文切换
Linux按照特权等级把进程运行空间分为内核空间和用户空间,分别为CPU特权等级的Ring 0和Ring 3。内核空间(Ring 0)具有最高权限,可以直接访问所有资源;用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问特权资源。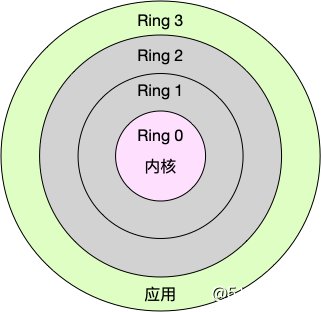
进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时称为进程的用户态,而陷入内核空间时称为进程的内核态。
进程从用户态切换到内核态需要通过系统调用来完成,会发生进程上下文切换(特权模式切换),当进程从内核态切换回用户态时也会发生上下文切换。每次进程上下文切换都需要几十纳秒到数微秒的CPU时间,如果切换频繁会导致CPU时间的浪费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,导致系统平均负载升高。
3、线程上下文切换
线程是调度的基本单位,而进程是资源拥有的基本单位。内核任务调度对象是线程,进程是给线程提供虚拟内存、全局变量等资源。当进程拥有多个线程时,线程间共享相同的虚拟内存和全局变量等资源。共享资源在上下文切换时不需要修改,线程自己的私有数据,比如栈和寄存器等,在上下文切换时需要保存。线程上下文切换分为两种:第一种,两个线程属于不同进程,因为资源不共享,线程切换过程跟进程上下文切换相同;第二种,两个线程属于同一个进程,因为虚拟内存共享,在线程切换时,虚拟内存等资源保持不动,只需要切换线程的私有数据、寄存器等不共享数据。进程内的线程切换比多进程间的进程切换消耗更少的资源。
4、中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其它进程时,需要将进程当前状态保存下来,在中断结束后,进程仍然可以从原来状态恢复运行。中断上下文切换不涉及进程用户态,因此即便中断过程打断一个正处在用户态的进程,也不需要保存和恢复进程的虚拟内存、全局变量等用户态资源。中断上下文只包括内核态中断服务程序执行所必需的状态,包括CPU寄存器、内核堆栈、硬件中断参数等。
对同一个CPU,中断处理比进程拥有更高的优先级,因此中断上下文切换不会与进程上下文切换同时发生。因为中断会打断正常进程调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。中断上下文切换需要消耗CPU,切换次数过多也会耗费大量CPU,严重降低系统整体性能。
5、系统调用
系统调用时,CPU寄存器中原来用户态的指令位置需要先保存起来;为了执行内核态代码,CPU寄存器需要更新为内核态指令的新位置,跳转到内核态运行内核任务;而系统调用结束后,CPU寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程发生了两次CPU上下文切换。系统调用过程中不会涉及虚拟内存等进程用户态资源,也不会切换进程。
进程上下文切换是指从一个进程切换到另一个进程运行,而系统调用过程中一直是同一个进程在运行。系统调用过程通常称为特权模式切换,而不是上下文切换。系统调用过程中,CPU上下文切换无法避免。进程是由内核来管理和调度的,进程切换只能发生在内核态。进程上下文不仅包括虚拟内存、栈、全局变量等用户空间的资源,还包括内核堆栈、寄存器等内核空间的状态。因此,进程上下文切换比系统调用时多一步:在保存当前进程的内核状态和CPU寄存器前,需要先把进程的虚拟内存、栈等保存下来;而加载下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
进程上下文切换需要内核在CPU上运行才能完成。
每次上下文切换都需要几十纳秒到数微秒的CPU时间,在进程上下文切换频繁时,容易导致CPU将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短真正运行进程的时间。
Linux通过TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB也需要刷新,内存访问会随之变慢。在多处理器系统上,L3缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器进程,还会影响共享缓存的其它处理器进程。
进程切换时才需要切换上下文,即只有在进程调度时才需要切换上下文。Linux为每个CPU都维护一个就绪队列,将活跃进程(即正在运行和正在等待CPU的进程)按照优先级和等待CPU的时间排序,然后选择最需要CPU的进程,即优先级最高和等待CPU时间最长的进程来运行。
触发进程调度的场景如下:
(1)为了保证所有进程可以得到公平调度,CPU时间被划分为一段段时间片,时间片再被轮流分配给各个进程。当某个进程的时间片耗尽,就会被系统挂起,切换到其它正在等待CPU的进程运行。
(2)进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,进程会被挂起,并由系统调度其它进程运行。
(3)当进程通过睡眠函数sleep方法将自己主动挂起时,会重新调度。
(4)当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
(5)发生硬件中断时,CPU上的进程会被中断挂起,转而执行内核中的中断服务程序。
6、CPU上下文切换指标
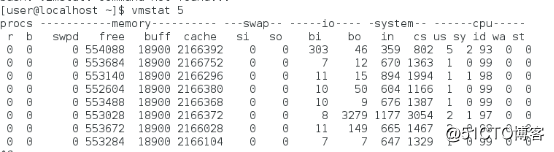
cs(context switch):每秒上下文切换的次数。
in(interrupt):每秒中断的次数。
r(Running or Runnable):就绪队列的长度,即正在运行和等待 CPU的进程数。
b(Blocked):处于不可中断睡眠状态的进程数。
vmstat只给出系统总体的上下文切换情况,使用pidstat可以查看进程的具体CPU上下文切换。
pidstat -w 5可以查看每个进程上下文切换情况。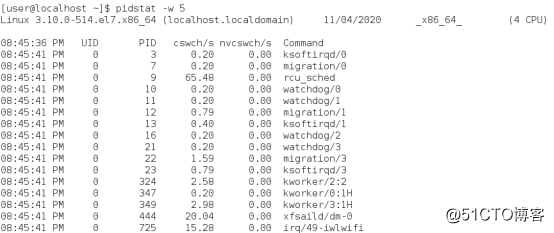
cswch:每秒自愿上下文切换(voluntary context switches)的次数
nvcswch:每秒非自愿上下文切换(non voluntary context switches)的次数。
自愿上下文切换是指进程无法获取所需资源而导致的上下文切换,如IO、内存等系统资源不足时会发生自愿上下文切换。自愿上下文切换变多,说明进程都在等待资源,可能发生IO等其它问题。
非自愿上下文切换是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。如大量进程都在争抢CPU时容易发生非自愿上下文切换。非自愿上下文切换变多,说明进程都在被强制调度,都在争抢CPU。
中断次数变多,说明CPU被中断处理程序占用,还需要通过查看/proc/interrupts文件来分析具体的中断类型。
二、CPU平均负载
1、进程状态
R是Running或Runnable缩写,表示进程在CPU的就绪队列中,正在运行或者正在等待运行。
D是Disk Sleep缩写,即不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且交互过程不允许被其它进程或中断打断。D状态的进程会导致平均负载升高。
Z是Zombie缩写,表示僵尸进程,进程已经结束,但父进程还没有回收资源(比如进程的描述符、PID 等)。
S是Interruptible Sleep缩写,即可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,会被唤醒并进入R状态。
I是Idle缩写,即空闲状态,用在不可中断睡眠的内核线程上。I状态的进程却不会。
T是Stopped或Traced缩写,表示进程处于暂停或者跟踪状态。向一个进程发送SIGSTOP信号,会因响应SIGSTOP信号变成暂停状态(Stopped);再向进程发送SIGCONT信号,进程又会恢复运行(如果进程是终端里直接启动的,则需要用fg命令,恢复到前台运行)。
X是Dead缩写,表示进程已经消亡,因此不会在top或者ps命令中显示。
当iowait升高时,进程很可能因为得不到硬件的响应,而长时间处于不可中断状态。不可中断状态是为了保证进程数据与硬件状态一致,并且正常情况下,不可中断状态在很短时间内就会结束。所以,短时的不可中断状态进程一般可以忽略。但如果系统或硬件发生故障,进程可能会在不可中断状态保持很久,甚至导致系统中出现大量不可中断进程。
正常情况下,当一个进程创建子进程后,应该通过系统调用wait或者waitpid等待子进程结束,回收子进程的资源;而子进程在结束时,会向父进程发送SIGCHLD信号,所以,父进程还可以注册SIGCHLD信号的处理函数,异步回收资源。如果父进程没这么做或是子进程执行太快,父进程还没来得及处理子进程状态,子进程就已经提前退出,子进程就会变成僵尸进程。通常,僵尸进程持续的时间都比较短,在父进程回收资源后就会消亡;或者在父进程退出后,由init进程回收后也会消亡。一旦父进程没有处理子进程的终止,还一直保持运行状态,子进程就会一直处于僵尸状态。大量的僵尸进程会用尽PID 进程号,导致新进程不能创建,必须避免。
2、CPU平均负载简介
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,即平均活跃进程数,与CPU使用率没有直接关系。
可运行状态进程是指正在使用CPU或者正在等待CPU的进程,即处于R状态(Running 或 Runnable)的进程。
不可中断状态进程是正处于内核态关键流程(不可中断)中的进程,如常见的等待硬件设备的I/O响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为Disk Sleep)的进程。
当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,进程是不能被其它进程或者中断打断,此时进程处于不可中断状态。如果此时进程被打断,容易出现磁盘数据与进程数据不一致问题。
可中断状态是系统对进程和硬件设备的一种保护机制。
平均负载实际是平均活跃进程数,因此平均负载指标需要和当前计算机系统的逻辑CPU数量一起参考。理想条件下,每个CPU都刚好运行一个进程时,每个CPU都可以得到充分利用。
平均负载指标可以使用top或uptime命令进行查看。
uptime观察的三个平均值分别为最近1min、5min、15min的平均负载,三个不同时间间隔的平均负载,提供了分析系统负载趋势的数据来源,能够更全面、更立体地理解目前的系统负载状况。
(1)如果1分钟、5分钟、15分钟的平均负载值基本相同,说明系统负载很平稳。
(2)如果1分钟平均负载值远小于15分钟平均负载值,说明系统最近1分钟的负载在减少,而过去15分钟内却有很大的负载。
(3)如果1分钟的平均负载值远大于15分钟的皮冠军负载值,说明最近1分钟的负载在增加,可能只是临时性的,也有可能会持续增加,所以需要持续观察。一旦1分钟的平均负载接近或超过逻辑CPU个数,则表明当前系统正在发生过载问题。
三、CPU使用率
1、CPU使用率简介
平均负载是指单位时间内处于可运行状态和不可中断状态的进程数。因此平均负载不仅包括正在使用CPU的进程,还包括等待CPU和等待IO的进程。
CPU使用率是单位时间内CPU使用情况的统计,以百分比的方式展示。
CPU使用率是单位时间内CPU繁忙情况的统计,跟平均负载并不一定完全对应。CPU密集型进程,使用大量CPU会导致平均负载升高,此时平均负载与CPU使用率是一致的;IO密集型进程,等待IO也会导致平均负载升高,但CPU使用率不一定很高;大量等待CPU的进程调度也会导致平均负载升高,此时的CPU使用率也会比较高。
平均负载是一个快速查看系统整体性能的指标,反映了系统的整体负载情况。但平均负载指标并不能定位系统的性能瓶颈。
平均负载高有可能是CPU密集型进程导致的;
平均负载高并不一定代表CPU使用率高,可能是IO等待时间较长;当发现平均负载高时,可以使用mpstat、pidstat辅助分析定位负载来源。
2、CPU使用率定义
CPU使用率是除了空闲时间外的其它时间占总CPU时间的百分比。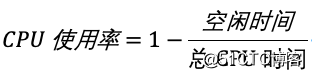
通过/proc/stat数据计算得到的CPU使用率是开机以来的平均CPU使用率。
为了计算CPU使用率,性能分析工具通常会取间隔一段时间(比如 3 秒)的两次值,作差后,再计算出时间段内的平均CPU使用率。
Linux为每个进程提供了运行情况的统计信息,即/proc/[pid]/stat。性能分析工具会根据/proc/stat和/proc/[pid]/stat计算出间隔一段时间的平均CPU使用率,不同的性能分析工具默认使用的时间间隔可能不同,因此使用多个性能分析工具对比分析时,一定要保证使用相同的间隔时间。如top默认使用3秒时间间隔,而ps使用的是进程的整个生命周期。
3、CPU使用时间
Linux作为一个多任务操作系统,将每个CPU的时间划分为很短的时间片,再通过调度器轮流分配给各个任务使用,因此造成多任务同时运行的错觉。为了维护CPU时间,Linux通过事先定义的节拍率(内核中表示为HZ),触发时间中断,并使用全局变量 Jiffies记录开机以来的节拍数。每发生一次时间中断,Jiffies值就加1。节拍率HZ是内核的可配选项,可以设置为100、250、1000等。不同的系统可能设置不同数值,可以通过查询/boot/config内核选项来查看。grep 'CONFIG_HZ=' /boot/config-$(uname -r)
节拍率HZ是内核选项,用户空间程序不能直接访问。为了方便用户空间程序,内核提供了一个用户空间节拍率USER_HZ,固定为100HZ。Linux通过/proc虚拟文件系统,向用户空间提供了系统内部状态的信息,而/proc/stat提供的是系统的CPU和任务统计信息。cat /proc/stat | grep ^cpu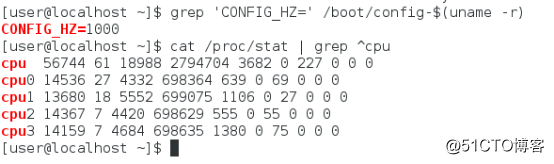
第一列是CPU编号,第一行没有编号的CPU表示所有CPU的累加。其它列表示不同场景下CPU的累加节拍数,单位是USER_HZ,即10ms(1/100 秒)。
proc/stat指标如下:
user(简写us)代表用户态CPU时间,不包括nice时间,但包括guest时间。
nice(简写ni)代表低优先级用户态CPU时间,进程的nice值被调整为1-19间时的CPU时间。nice可取值范围是-20到19,数值越大,优先级反而越低。
system(简写sys)代表内核态CPU时间。
idle(简写id)代表空闲时间,不包括等待IO的时间(iowait)。
iowait(简写wa)代表等待IO的CPU时间。
irq(简写hi)代表处理硬中断的CPU时间。
softirq(简写si)代表处理软中断的CPU时间。
steal(简写st)代表当系统运行在虚拟机中的时候,被其他虚拟机占用的CPU时间。
guest(简写guest)代表通过虚拟化运行其它操作系统的时间,即运行虚拟机的CPU时间。
guest_nice(简写gnice)代表以低优先级运行虚拟机的时间。
top输出%Cpu行是系统的CPU使用率,默认显示是所有CPU的平均值,按下数字1可以切换查看每个CPU使用率。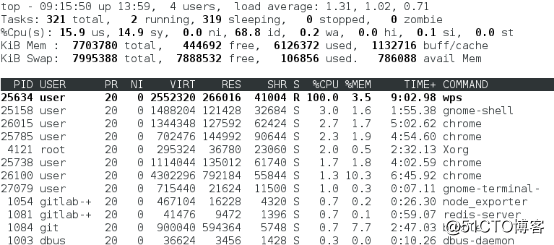
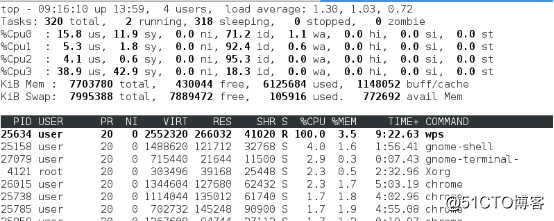
进程实时信息中每个进程都有一个%CPU列,表示进程的CPU使用率,是用户态和内核态CPU使用率的总和,包括进程用户空间使用的CPU、通过系统调用执行的内核空间CPU 、就绪队列等待运行的CPU。在虚拟化环境中还包括了运行虚拟机占用的CPU。
进程的具体CPU使用率使用pidstat查看: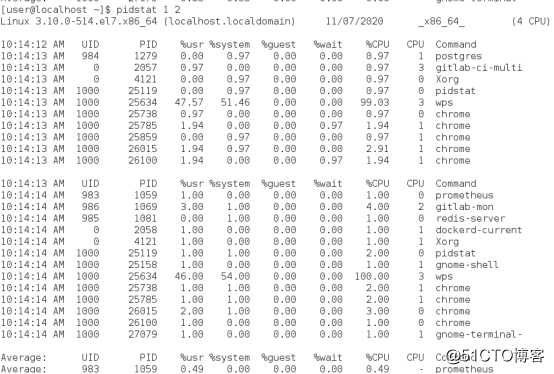
%usr指标:用户态CPU使用率
%system:内核态CPU使用率
%guest:运行虚拟机CPU使用率
%wait:等待CPU使用率
%CPU:总的CPU使用率
Average部分会计算2组数据的平均值。
4、异常CPU使用率
对于某些无法解释的高CPU使用率情况时,有可能是短时应用导致的问题。
(1)应用里直接调用了其它二进制程序,但运行时间比较短,通过 top等工具不容易发现。
(2)应用不停地崩溃重启,而启动过程的资源初始化可能会占用大量CPU资源。
短时进程查看可以使用execsnoop工具进行查看。
四、中断
1、中断简介
中断是一种异步的事件处理机制,可以提高系统的并发处理能力。由于中断处理程序会打断其它进程的运行,所以为了减少对正常进程运行调度的影响,中断处理程序就需要尽可能快地运行。如果中断服务程序运行时间较长,特别是中断处理程序在响应中断时,还会临时关闭中断,导致上一次中断处理完成前,其它中断都不能响应,即中断有可能会丢失。
为了解决中断处理程序执行过长和中断丢失的问题,Linux将中断处理过程分成两个阶段,上半部用来快速处理中断,在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作,下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
上半部直接处理硬件请求,即硬中断,特点是快速执行;而下半部则是由内核触发,即软中断,特点是延迟执行。硬件中断会打断CPU正在执行的任务,然后立即执行中断处理程序;软件中断以内核线程方式执行,并且每个CPU都对应一个软中断内核线程,名字为 ksoftirqd/C编号,CPU0对应的软中断内核线程的名字是 ksoftirqd/0。软中断不只包括硬件设备中断处理程序的下半部,一些内核自定义的事件也属于软中断,比如内核调度和RCU锁(Read-Copy Update,RCU是Linux内核中最常用的锁之一)等。
网卡接收到数据包后,会通过硬件中断方式通知内核有新的数据,内核就调用中断处理程序把网卡数据读到内存中,并且更新硬件寄存器状态(表示数据已经读好),最后再发送一个软中断信号,通知下半部做进一步的处理。而下半部被软中断信号唤醒后,需要从内存中找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,直到把它送给应用程序。
Linux中软中断包括网络收发、定时、调度、RCU锁等各种类型,proc文件系统中的/proc/softirqs可以观察软中断的运行情况。
在Linux中,每个CPU都对应一个软中断内核线程,名字是ksoftirqd/CPU编号。当软中断事件频率过高时,内核线程会因为CPU 使用率过高而导致软中断处理不及时,进而引发网络收发延迟、调度缓慢等性能问题。软中断CPU使用率过高也是一种最常见的性能问题。
2、中断查看
proc文件系统是内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构或者动态修改内核配置。
/proc/softirqs提供了软中断的运行情况。
/proc/interrupts提供了硬中断的运行情况。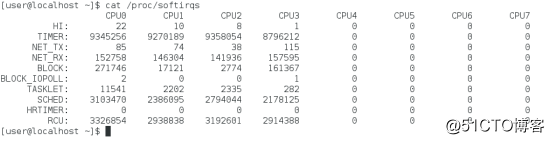
第一列内容是软中断类型,软中断包括10个类别,分别对应不同的工作类型。NET_RX表示网络接收中断,NET_TX表示网络发送中断。通常同一种中断在不同CPU上的累积次数是同一个数量级,相差不大。
/proc/softirqs内容是系统运行以来累积中断次数,生产中通常关注中断次数的变化速率,因此使用watch -d cat /proc/softirqs查看软中断变化情况。
TIMER(定时中断)、NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU锁)等软中断都在不停变化。NET_RX、NET_TX软中断类型需要使用sar工具查看网络数据收发。
第一列是表示报告的时间。
第二列IFACE表示网卡。
第三列rxpck/s表示每秒接收的网络帧数量,PPS。
第四列txpck/s表示每秒发送的网络帧数,PPS。
第五列rxkB/s表示每秒接收的千字节数,BPS。
第六列txkB/s表示每秒发送的千字节数,BPS。
3、不可中断进程
不可中断状态表示进程正在跟硬件交互,为了保护进程数据和硬件的一致性,系统不允许其它进程或中断打断处于不可中断状态的进程。进程长时间处于不可中断状态,通常表示系统存在IO性能问题。
4、僵尸进程
僵尸进程表示进程已经退出,但其父进程还没有回收子进程占用的资源。短暂的僵尸状态通常不必理会,但进程长时间处于僵尸状态表示可能有应用程序没有正常处理子进程退出。