最近在做给新闻分词。为了保证给文章贴的标签的准确度高,决定做一个标签库。但发现给新闻打标签网站就只有今日头条打的比较好,网易一般,其他根本不能看,决定写一个爬取今日头条文章标签的爬虫。
一:解析参数
 今日头条的数据全部都是ajax异步加载的。谷歌浏览器按f12选择network点击XHR会得到如上图所示,上图请求的url中有如下几个参数会变化:
今日头条的数据全部都是ajax异步加载的。谷歌浏览器按f12选择network点击XHR会得到如上图所示,上图请求的url中有如下几个参数会变化:
① category
② max_behot_time
③ max_behot_time_tmp
④ as
⑤ cp
⑥ _signature
其中只需要category,max_behot_time,_signature这个三个参数就可以获取到数据。这是我自己亲自试验过的。
category根据你请求不同的栏目会变化,比如你请求科技栏目category为news_tech:

请求热点栏目category为news_hot:

max_behot_time会动态变化最开始为0,下一次变化为这次请求到的json数据中max_behot_time的值:
当前max_behot_time请求的json数据中的max_behot_time的值为1544445969

第二次请求的max_behot_time为1544445969。 
第三个参数为_signature,它是由一个很复杂的js代码生成的,这个js代码通过TAC.sign(max_behot_time)来生成,就是上面的那个参数max_behot_time的值:


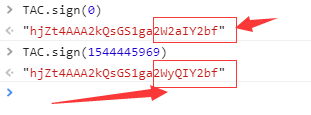
仔细看哦,他们可不是一样的哦。

三个参数到此解析完毕:
接下来就是撸代码,只需复制粘贴,改动一点即可使用。
pacong.py
#coding:utf-8
from selenium import webdriver
from time import ctime,sleep
import threading
import requests
import time
import json
import sys
import random
import Two
reload(sys)
sys.setdefaultencoding('utf-8')
# 进入浏览器设置
def run(ajax):
name = "word-{a}-".format(a=ajax) + time.strftime("%Y-%m-%d") + ".txt"
print name
options = webdriver.ChromeOptions()
# 设置中文
agent=Two.get_agent()
options.set_headless()
options.add_argument('lang=zh_CN.UTF-8')
options.add_argument(
'user-agent={}'.format(agent))
# --我使用了浏览器去获取_signature的值,你们需要修改这个地方,详细信息去简单百度一下即可
brower = webdriver.Chrome(chrome_options=options,
executable_path='C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
#brower.get('https://www.toutiao.com/ch/news_hot/')
brower.get('https://www.toutiao.com/ch/{t}/'.format(t=ajax))
print 'https://www.toutiao.com/ch/{t}/'.format(t=ajax)
sinature = brower.execute_script('return TAC.sign(0)')
print(sinature)
"""获取cookie"""
cookie = brower.get_cookies()
print cookie
cookie = [item['name'] + "=" + item['value'] for item in cookie]
cookiestr = '; '.join(item for item in cookie)
time1=0
last=0
while 1:
header1 = {
'Host': 'www.toutiao.com',
'User-Agent': agent,
'Referer': 'https://www.toutiao.com/ch/{}/'.format(ajax),
"Cookie": cookiestr
}
#print cookiestr
url = 'https://www.toutiao.com/api/pc/feed/?category={t}&utm_source=toutiao&widen=1&max_behot_time={time}&_signature={s}'.format(t=ajax,time=time1,s=sinature)
print(url)
#设置了动态代理好像没什么用
o_g = ["213.162.218.75:55230",
"180.180.152.25:51460",
"79.173.124.194:47832",
"50.112.160.137:53910",
"211.159.140.111:8080",
"95.189.112.214:35508",
"168.232.207.145:46342",
"181.129.139.202:32885",
"78.47.157.159:80",
"112.25.6.15:80",
"46.209.135.201:30418",
"187.122.224.69:60331",
"188.0.190.75:59378",
"114.234.76.131:8060",
"125.209.78.80:32431",
"183.203.13.135:80",
"168.232.207.145:46342",
"190.152.5.46:53281",
"89.250.149.114:60981",
"183.232.113.51:80",
"213.109.5.230:33138",
"85.158.186.12:41258",
"142.93.51.134:8080",
"181.129.181.250:53539"]
a = 0
for a in range(0, 1):
#跑了17个线程,请求太快会被封的
sleep(30)
c = random.randint(0, 23)
proxies_l = {'http': o_g[c],}
try:
html = requests.get(url, headers=header1, verify=False,proxies=proxies_l)
print html.cookies
html.encoding
data = html.content
print(data)
if(len(data)==51):
print "被禁了"
sleep(3600)
try:
s1 = json.loads(data)
try:
time1 = s1["next"]["max_behot_time"]
except Exception as e:
print e
print time1
#根据max_behot_time获取signature的值
sinature = brower.execute_script('return TAC.sign({})'.format(time1))
print(sinature)
f = open(name, 'a')
res = ""
for i in range(len(s1["data"])):
try:
#我需要的文章的label值。
l = s1["data"][i]["label"]
except Exception as e:
print e
continue
for j in range(len(l)):
res = l[j] + "\n"
f.write(res)
#print l[j]
f.close()
#last=time1
break
except Exception as e:
print("解析错误")
continue;
except Exception as e:
print('no proxies')
continue
#print html.content
threads = []
#热点news_hot
t1 = threading.Thread(target=run,args=("news_hot",))
threads.append(t1)
#科技 https://www.toutiao.com/ch/news_tech/
t2 = threading.Thread(target=run,args=("news_tech",))
threads.append(t2)
# #娱乐 https://www.toutiao.com/ch/news_entertainment/
t3 = threading.Thread(target=run,args=("news_entertainment",))
threads.append(t3)
#游戏 https://www.toutiao.com/ch/news_game/ 没撒用
t4 = threading.Thread(target=run,args=("news_game",))
threads.append(t4)
#体育https://www.toutiao.com/ch/news_sports/
t5 = threading.Thread(target=run,args=("news_sports",))
threads.append(t5)
#汽车https://www.toutiao.com/ch/news_car/
t6= threading.Thread(target=run,args=("news_car",))
threads.append(t6)
#财经https://www.toutiao.com/ch/news_finance/
t7= threading.Thread(target=run,args=("news_finance",))
threads.append(t7)
#军事https://www.toutiao.com/ch/news_military/
t8= threading.Thread(target=run,args=("news_military",))
threads.append(t8)
#时尚https://www.toutiao.com/ch/news_fashion/
t9= threading.Thread(target=run,args=("news_fashion",))
threads.append(t9)
#国际https://www.toutiao.com/ch/news_world/
t10= threading.Thread(target=run,args=("news_world",))
threads.append(t10)
#探索https://www.toutiao.com/ch/news_discovery/
t11= threading.Thread(target=run,args=("news_discovery",))
threads.append(t11)
#养生https://www.toutiao.com/ch/news_regimen/
t12= threading.Thread(target=run,args=("news_regimen",))
threads.append(t12)
#历史https://www.toutiao.com/ch/news_history/
t13= threading.Thread(target=run,args=("news_history",))
threads.append(t13)
#美食https://www.toutiao.com/ch/news_food/
t14= threading.Thread(target=run,args=("news_food",))
threads.append(t14)
#旅游https://www.toutiao.com/ch/news_travel/
t15= threading.Thread(target=run,args=("news_travel",))
threads.append(t15)
#育儿https://www.toutiao.com/ch/news_baby/
t16= threading.Thread(target=run,args=("news_baby",))
threads.append(t16)
#美文https://www.toutiao.com/ch/news_essay/
t17= threading.Thread(target=run,args=("news_essay",))
threads.append(t17)
if __name__ == '__main__':
for t in threads:
t.setDaemon(True)
t.start()
time.sleep(1080000)
print "all over %s" %ctime()
#coding:utf-8
import requests
import random
import json
import re
def get_agent():
ua_list = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
user_agent = random.choice(ua_list)
print user_agent
return user_agent
上面这个是随机生成agent,好让爬虫不那么容易被禁
结果如下:

希望能帮到有需要的朋友。