1.工具使用
python的request包和json包
fiddle抓包工具
2.请求分析
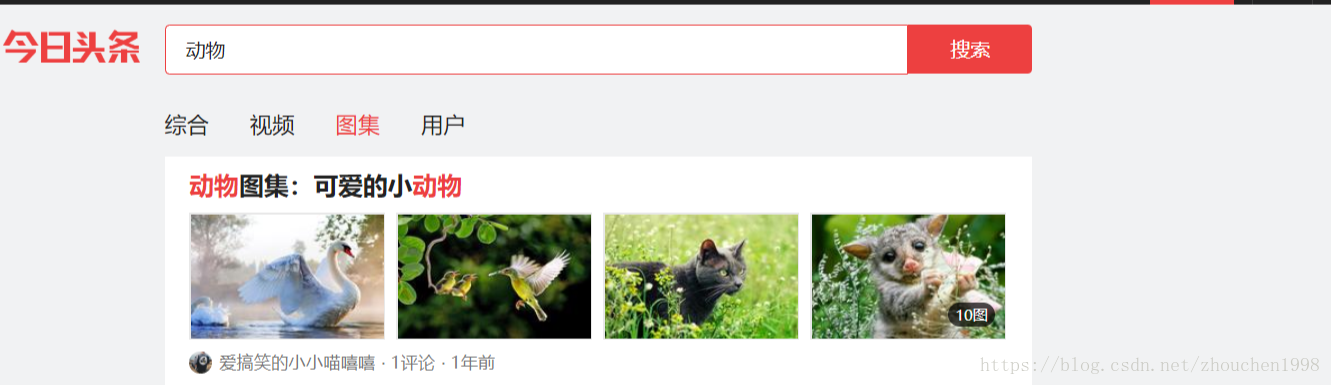
我们访问该页面,抓取请求,得到如下结果。
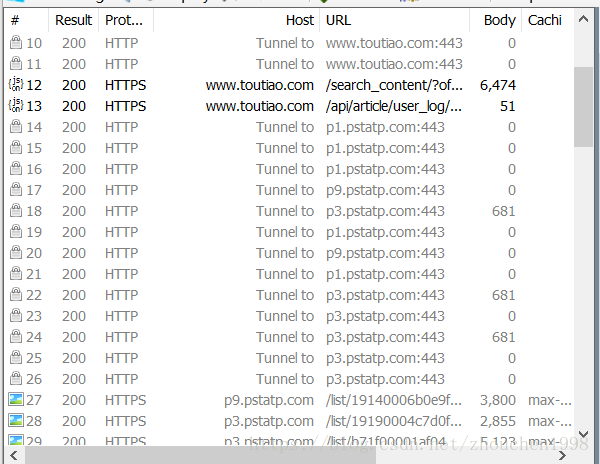
不难发现,在图片加载之前数据量最大的就是search_content请求,其实了解后端开发的知道这是一个带参数的请求且参数之一就是搜索关键词,而且还有一个参数format=json,不妨猜测这是一个json请求,然后网页利用这个json文件进行渲染。
3.文件获取
我们尝试解包,成功。
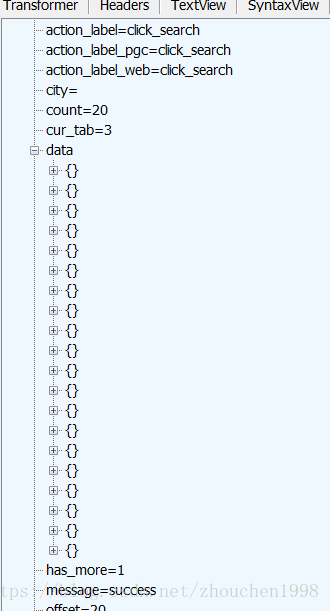
发现有20个结构相同的数组,而之前的请求包含数量和页码就是第一页的20个,如此不难通过循环控制url来访问每一页的json文件。
4.json分析
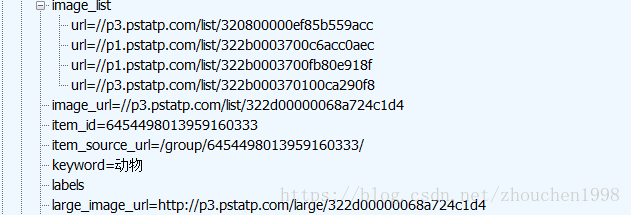
不难发现,每一个帖子的图片集合在image_list中,但是这些url访问得到的图都是很小的,我们看到image_list下面出现了large_image_url不难知道大图的url结构,进行一个字符串替换即可。(也就是list替换为large)
5.文件存储
利用二进制存储到本地。由于尝试需要,这里就不进行异常处理。
6.完整代码
import requests
import json
base_url = "https://www.toutiao.com"
def get_pics(number):
target_url = "https://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E7%BE%8E%E5%A5%B3&autoload=true&count=20&cur_tab=3&from=gallery"
target_url = target_url.replace("xxx", str(number))
return target_url
if __name__ == '__main__':
url_list = []
for i in range(0, 1000, 20):
url_list.append(get_pics(i))
headers = {'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': 'http://www.xicidaili.com/nn/',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
rsp_list = []
for item in url_list:
rsp_list.append(requests.get(item, headers=headers, verify=False))
pic_list = []
for item in rsp_list:
j = json.loads(item.text)['data']
for item in j:
try:
for i in item['image_list']:
pic_list.append("http:"+i['url'].replace("list", "large"))
except Exception as e:
pass
import os
number = 0
os.chdir("zc2")
for i in pic_list:
s = requests.get(i, headers=headers).content
with open(str(number)+".jpg", 'wb') as f:
f.write(s)
print(" 第{}张图片下载完成".format(number))
number += 1