- 衔接上一篇
4.获取图片的url
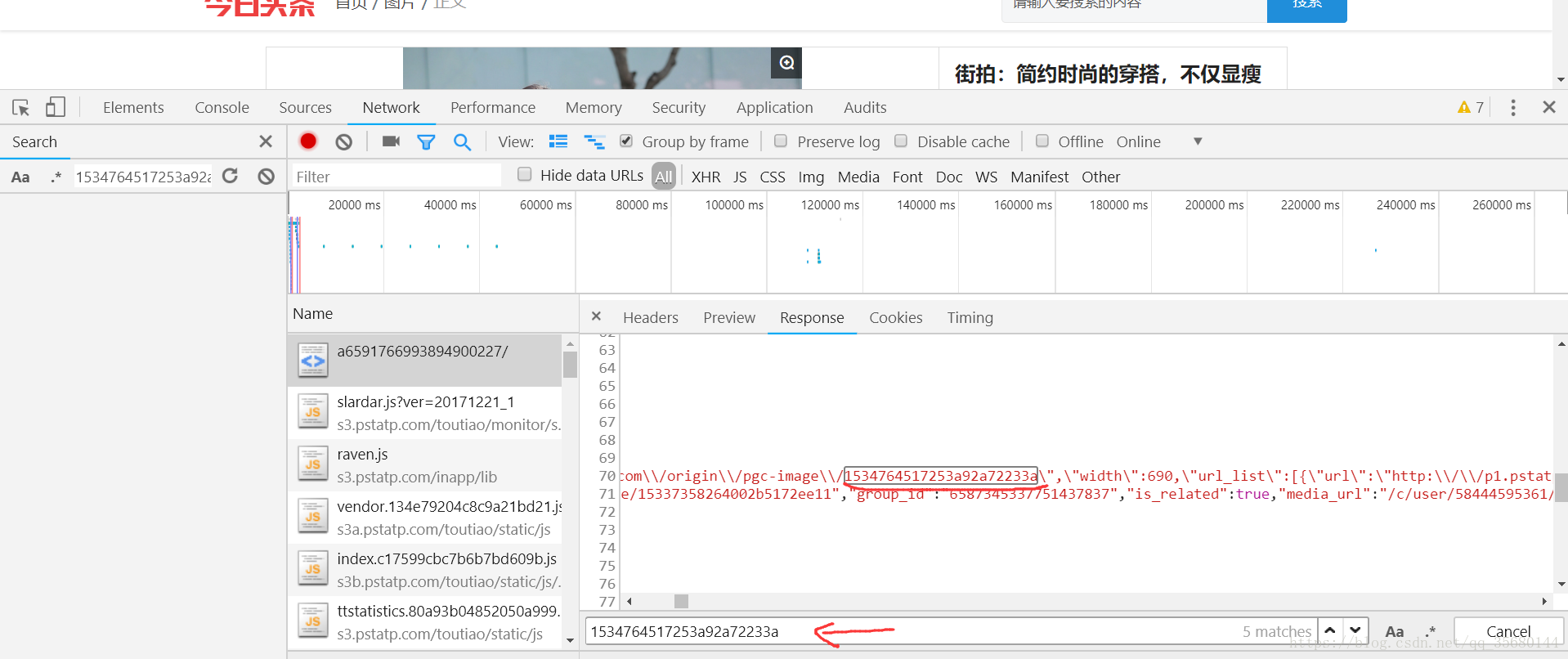
先看看图片
我们目的就 是找到这个url,多点几个发现就是后面的数字变变,这就好办了找id
详情页也是全部js渲染出来的,我们继续f12
在XHR里死活找不到,就跑到ALL里面看看然后一把就搞到了,这个请求其实就 是详情页的url,所以我们爬图片id就衔接上一步爬到的详情页url了代码

def get_image(self,url): #传入详情页的url
html = requests.get(url,headers=self.headers).text
image_link = re.compile(r'pgc-image\\\\/(.*?)\\')
image = set(image_link.findall(html,re.S)) #set去重
url_list = [self.base_url+i for i in image]
#base_url就是所有图片url的相同部分即id前面那部分
return url_list#返回图片的url列表5.保存图片
def save_image(self,image_url):#传入图片url
lens = len(self.base_url)
i = image_url[lens::] #图片的Id
image = requests.get(image_url)
with open('G:/paphotos/%s.jpg'%i,'wb') as f:
f.write(image.content) #保存文件全部代码
import requests
from urllib.parse import urlencode
import re
from concurrent.futures import ThreadPoolExecutor#线程池
class JinRi:
def __init__(self,start,end):
self.start = start
self.end = end
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
self.base_url = 'http://p3.pstatp.com/origin/pgc-image/'
def get_bhtml(self,keyword,offset): #获取总页面的代码
data = { #为了方便更改所以变成字典样式
"offset": offset,
"format": "json",
"keyword": keyword,
"autoload": "true",
"count": 20,
"cur_tab": 1,
"from": "search_tab"
}
url = 'https://www.toutiao.com/search_content/?'+urlencode(data)#urlencode用于把自典变成url形式
response = requests.get(url,headers=self.headers).text
url_list = self.get_xurl(response)
return url_list #返回的是详情页的url列表
def get_xurl(self,html): #传入总页面的网页代码
url = re.compile('"share_url": "(.*?)",')
urls = url.findall(html,re.S)
url_list = [i for i in urls]
return url_list #返回各个详情页的url的列表
def get_image(self,url): #传入详情页的url
html = requests.get(url,headers=self.headers).text
image_link = re.compile(r'pgc-image\\\\/(.*?)\\')
image = set(image_link.findall(html,re.S)) #set去重
url_list = [self.base_url+i for i in image]
#base_url就是所有图片url的相同部分即id前面那部分
return url_list#返回图片的url列表
def save_image(self,image_url):#传入图片url
lens = len(self.base_url)
i = image_url[lens::] #图片的Id
image = requests.get(image_url)
with open('G:/paphotos/%s.jpg'%i,'wb') as f:
f.write(image.content) #保存文件
def main(self):
offset = [i*20 for i in range(self.start,self.end)]
for a in offset:
url_list = self.get_bhtml('街拍',a) #详情页的url列表
for j in url_list:
url_l = self.get_image(j)#列表
with ThreadPoolExecutor(max_workers=8) as pool:
pool.map(self.save_image,url_l)#map方式是传个列表
if __name__ == '__main__':
pa = JinRi(0,1)
pa.main()