万年老掉牙的头条街拍爬取,不过用来练习还是可以的,也有很多资料查询
1.获取总页面的代码
在头条的右上角搜索选项内搜索街拍,我们看见街拍首页了,然后看看是不是js加载的发现还真是,头条全部都是js加载的,这里可以用Toggle JavaScript(Chrome插件),这个可以去Chrome的插件网上下载,就是点一下js部分就会被禁止执行,方便点
2.找js请求
- F12打开开发者选项
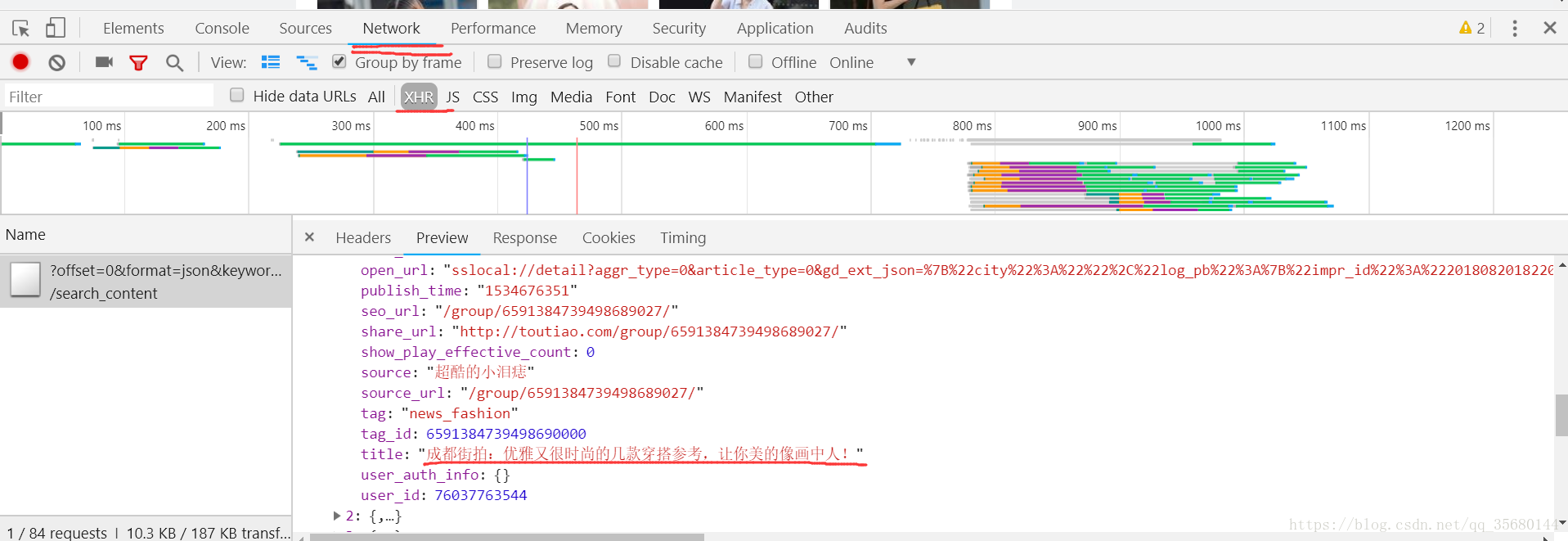
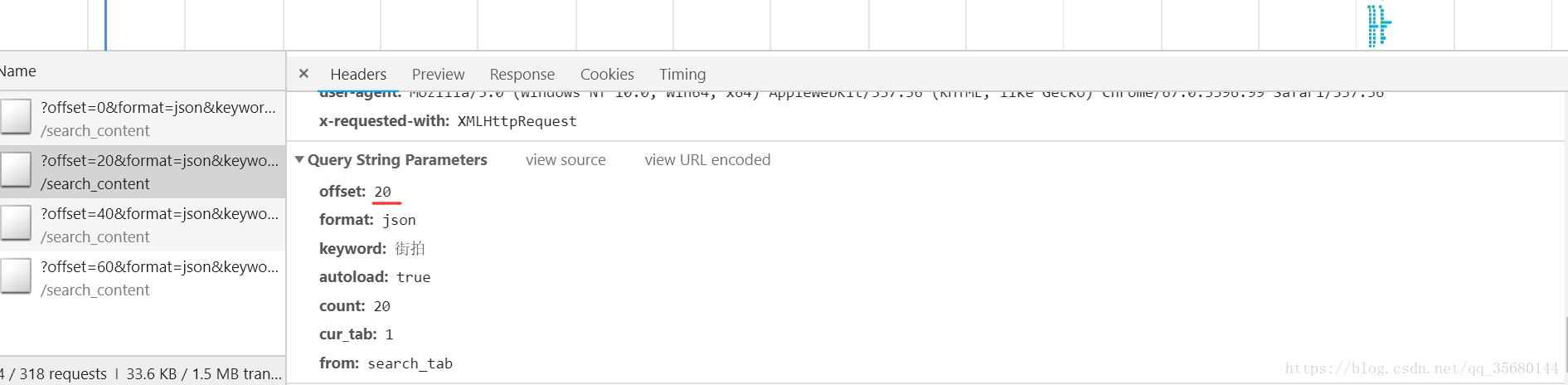
在XHR中就一个请求,点进去一看发现就是我们想要的,再看看headers
Query String Parameters是构成url请求的数据,就是url的?后面的数据码出代码
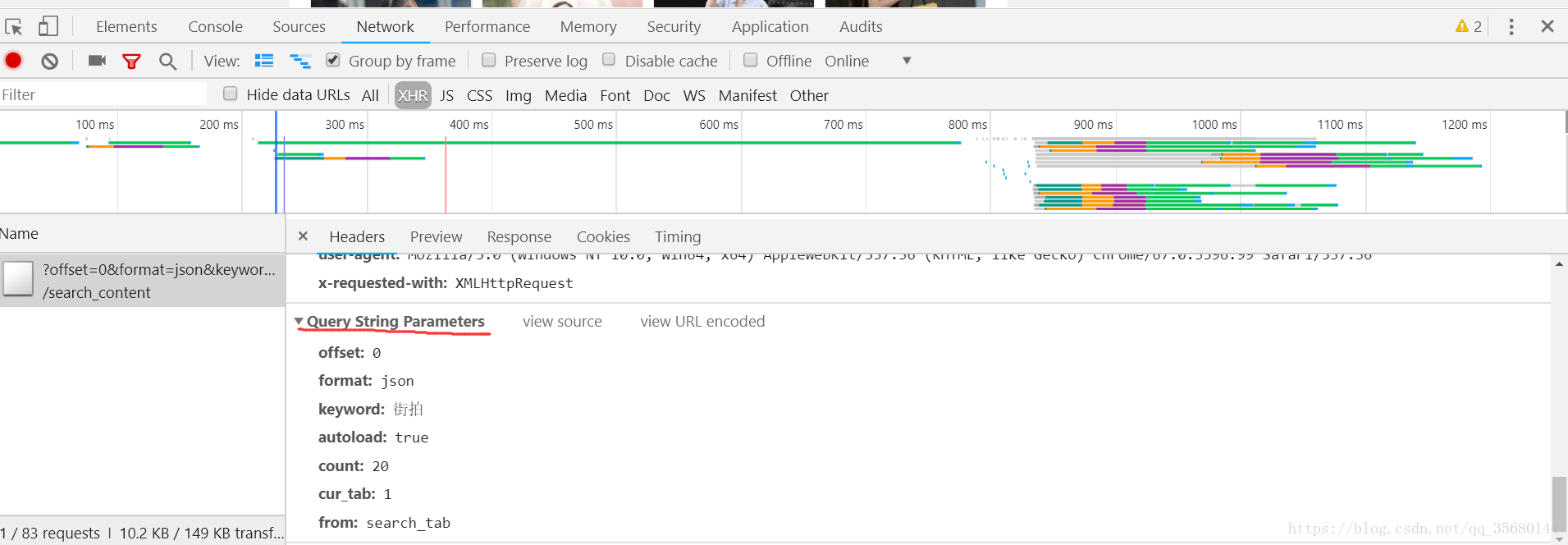
def get_bhtml(self,keyword,offset): #获取总页面的代码
data = { #为了方便更改所以变成字典样式
"offset": offset,
"format": "json",
"keyword": keyword,
"autoload": "true",
"count": 20,
"cur_tab": 1,
"from": "search_tab"
}
url = 'https://www.toutiao.com/search_content/?'+urlencode(data)#urlencode用于把自典变成url形式
response = requests.get(url,headers=self.headers).text
return response #返回页面的代码
3.获取详情页的url
打开刚才的到的请求看看
data的第二个字典是我们想要东西的第一个,share_url就是我们要的详情页的url,似乎大功告成,但是头条还有ajax,我们不可能只爬他刚加载的部分ajax的爬取
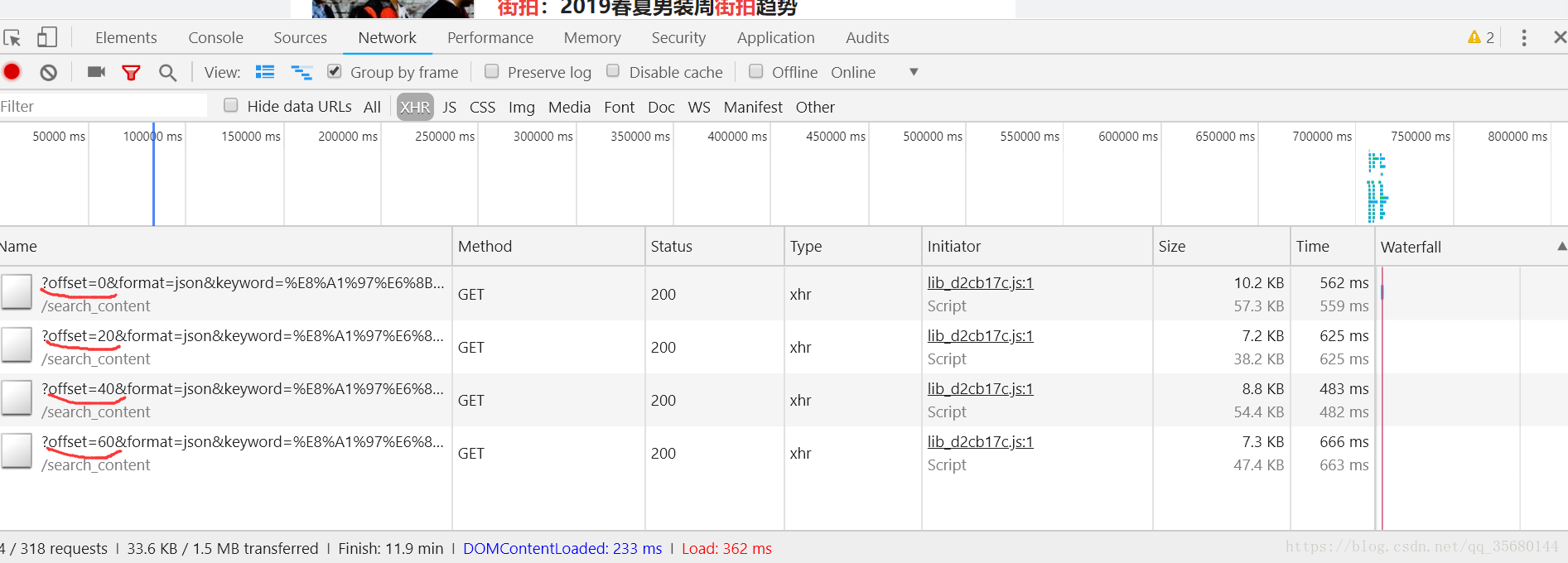
打开F12,然后不断往下翻,就多出来几个请求
offset的作用看出来了
也就offset变了代码

def get_xurl(self,html): #传入总页面的网页代码
url = re.compile('"share_url": "(.*?)",')
urls = url.findall(html,re.S)
url_list = [i for i in urls]
return url_list #返回各个详情页的url的列表