1、Dual Contrastive Loss and Attention for GANs
使用大规模图像数据集时,生成对抗网络 (GAN) 在无条件图像生成方面效果非常不错。但生成的图像仍然很容易被甄别出来,尤其是在具有高方差的数据集(例如卧室、教堂)上。
本文提出一种新的双重对比损失,并表明通过这种损失,判别器可以学习更通用和可区分的表示来激励生成质量。此外,重新审视了注意力并在生成器中对不同的注意力块进行了广泛的实验。发现注意力仍然是成功生成图像的重要模块,即使它在最近的先进模型中未使用。最后,研究了判别器中不同的注意力架构,并提出了一个参考注意力机制。通过结合这些措施,在几个基准数据集上将FID提高了至少 17.5%,在合成场景上获得了更显著的提升(在 FID 中高达 47.5%)。
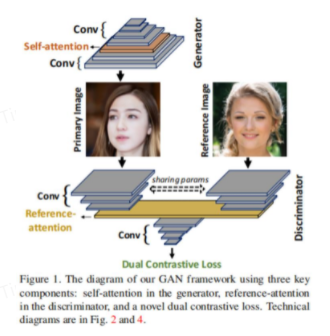
2、Dual Projection Generative Adversarial Networks for Conditional Image Generation
条件生成对抗网络 (cGAN) 扩展了无条件 GAN ,可以从样本中学习联合数据标签分布,是能够生成高保真图像的强大生成模型。训练的挑战在于将类信息合理地注入到它的生成器和判别器中。
提出了一个双投影 GAN (Dual Projection,P2GAN)学习在数据匹配和标签匹配之间取得平衡的模型;提出了一种改进的、带辅助分类的 cGAN 模型,通过最小化 f-divergence 来直接对齐假和真条件 P(class|image)。多个数据集(包括 CIFAR100、ImageNet 和 VGGFace2)的实验证明了有效性。
3、Focal Frequency Loss for Image Reconstruction and Synthesis
生成模型的不断发展,让图像重建和合成取得了显著进步。尽管如此,真实图像和生成图像之间仍可能存在差距,特别是在频域。
本研究表明缩小频域差距可以进一步改善图像重建和合成质量,提出一种新的focal frequency loss,可以作为现有空间损失的补充。
实验表明它可以在感知质量和定量方面改进流行模型(如 VAE、pix2pix 和 SPADE),在 StyleGAN2 上同样潜力极大。
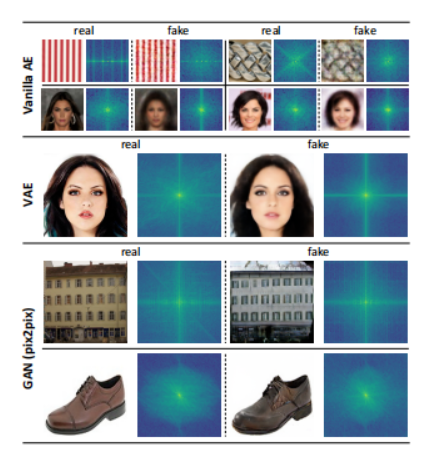
4、Gradient Normalization for Generative Adversarial Networks
本文提出一种新的归一化方法:梯度归一化(GN),以解决生成式对抗网络(GANs)梯度不稳定问题。与现有的梯度惩罚和谱归一化等不同,本文的GN算法只对判别器函数施加梯度范数约束;在4个数据集上进行的大量实验表明,方法在Frechet Inception Distance和Inception Score两方面都可以有优越性。

5、F-Drop&Match: GANs with a Dead Zone in the High-Frequency Domain
生成式对抗网络缺乏精确复制自然图像高频成分的能力。为了缓解这个问题,本文引入了两种新的训练技术,称为频率下降(F-Drop)和频率匹配(F-Match)。实验证明F-Drop和F-Match的结合提高了gan在频域和空间域的生成性能。
6、Latent Transformations via NeuralODEs for GAN-based Image Editing
高保真语义图像编辑的最新进展里,很多研究工作依赖于生成模型(例如 StyleGAN)解耦的潜在空间。最近的工作表明,可通过线性移动和潜在方向来实现人脸属性的可控编辑。对于许多更复杂的变化因素,本文工作展示了可训练神经 ODE 流的非线性潜码操作的优越性。毕竟大量数据集某些属性操作仅通过线性移位操作并不简单。

7、Detail Me More: Improving GAN’s photo-realism of complex scenes
生成模型可以合成单个物体对象的逼真图像。例如,对于人脸,算法学习对人脸局部形状和阴影进行建模,即眉毛、眼睛、鼻子、嘴巴、下巴线等的变化。这是可能的,因为所有的人脸都有两个眉毛,两个眼睛、鼻子和嘴巴,大致在同一位置。然而,复杂场景的建模更具挑战性,因为场景组件及其位置因图像而异。例如,起居室包含属于许多可能类别和位置的不同数量的产品,例如,一盏灯可能存在也可能不存在于无数可能的位置。
扫描二维码关注公众号,回复: 13719816 查看本文章
本文提出在生成对抗网络(GAN)中添加一个“代理”模块来解决这个问题。代理任务是在图像区域中调解多个判别器的使用。例如,如果在场景的特定区域检测到或需要一盏灯,代理会为该图像块分配一个细粒度的灯判别器。这可以促使生成器学习灯的形状和阴影模型。由此产生的多细粒度优化问题能够合成具有与单个对象图像几乎相同的真实感水平的复杂场景。在几种 GAN 算法(BigGAN、ProGAN、StyleGAN、StyleGAN2)、图像分辨率(2562 到 10242)和数据集上证明了所提出的方法的通用性。方法比当下 GAN 算法有了显著改进。

8、EigenGAN: Layer-Wise Eigen-Learning for GANs
生成对抗网络 (GAN) 的不同层有不同的图像语义。很少有 GAN 模型具有明确的维度来控制特定层中表示的语义属性。
本文提出EigenGAN,能够无监督地从不同的生成器层挖掘可解释和可控的维度。代码:https://github.com/LynnHo/EigenGAN-Tensorflow

9、Omni-GAN: On the Secrets of cGANs and Beyond
条件生成对抗网络 (cGAN) 是生成高质量图像的强大工具,但现有方法大多性能不令人满意或存在模式坍塌的风险。
本文介绍 OmniGAN,是 cGAN 的一种变体,针对训练合适判别器的问题。关键是要确保判别器接受强监督并适度正则化以避免坍塌。在 ImageNet 数据集上创造了新的记录,对于 128 和 256 的图像大小,Inception 分数分别为 262.85 和 343.22,比之前的记录高出 100 多个点。
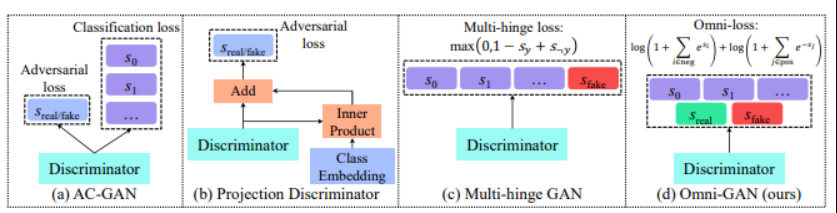
10、Towards Discovery and Attribution of Open-world GAN Generated Images
随着生成对抗网络 (GAN) 的最新进展,媒体和视觉取证需要识别生成图像。现有工作仅限于封闭集场景,无法推广到不存在训练期间的 GAN。提出一种迭代算法,由多个组件组成,包括网络训练、分布外检测、聚类、合并和细化步骤。
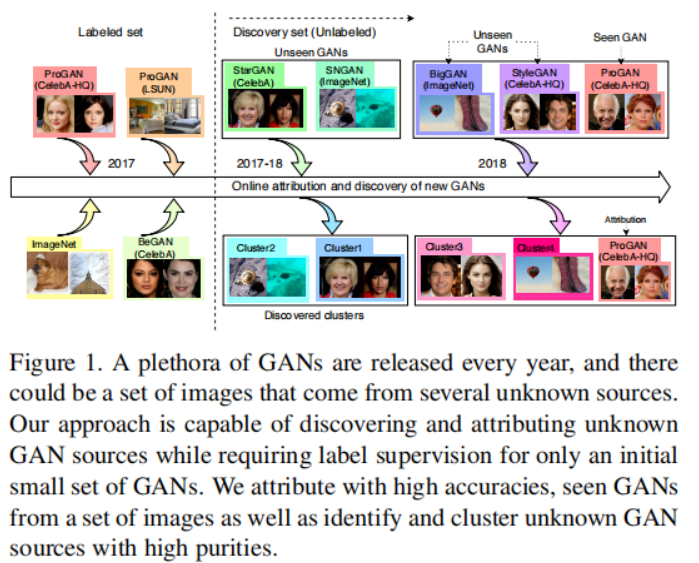
11、Unsupervised Image Generation with Infifinite Generative Adversarial Networks
图像生成在计算机视觉中得到大量研究,其中一项核心挑战是无监督图像生成。生成对抗网络 (GAN) 作为一种隐式方法在这个方向上取得了巨大的成功,被广泛采用。
GAN 存在模式坍塌、非结构化潜在空间、无法计算似然等问题。本文提出一种新的无监督非参数方法,称为infinite conditional GANs 或 MIC-GANs,一起解决几个 GAN 问题,旨在用简约的先验知识生成图像。github.com/yinghdb/MICGANs。
-------------END-------------
往期阅读

如果觉得有用,就点个“在看”吧 