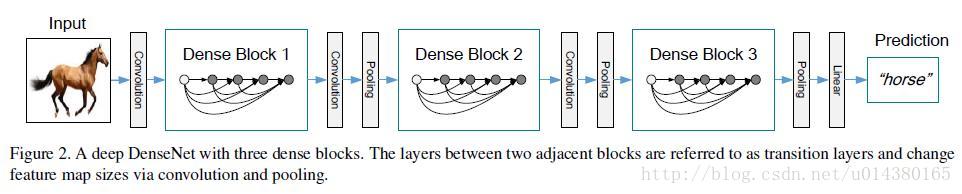
网络基本结构
我们放大一下Dense Block
Dense Block
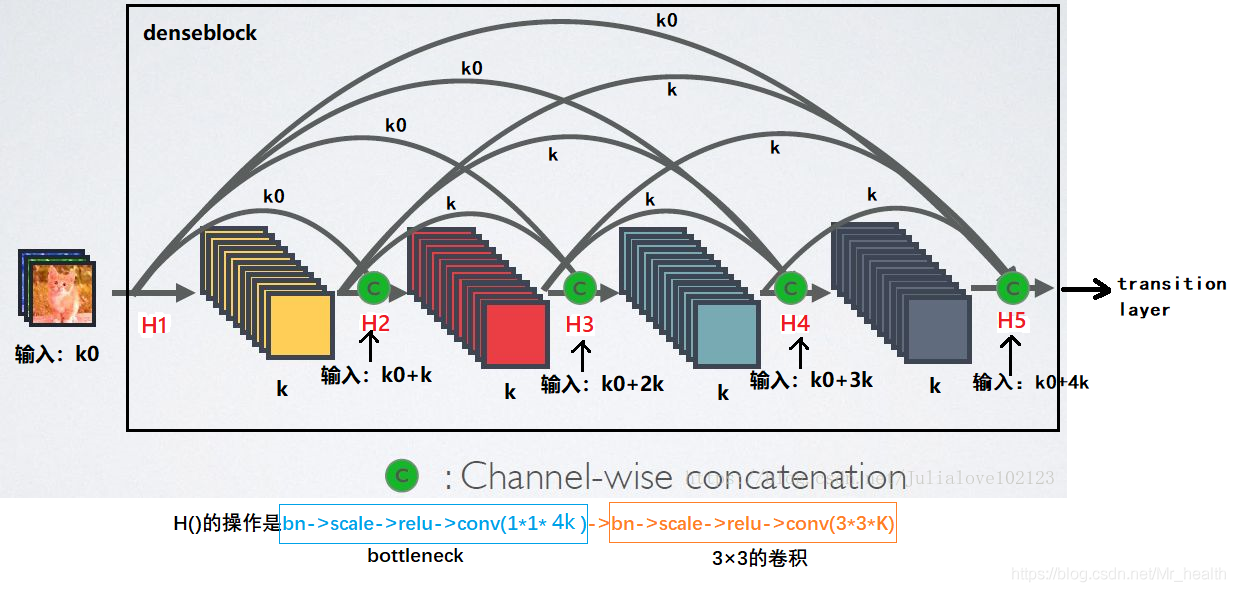
上图中每一次的输入都是经过Channel-wise concatenation后的,如k0+k,k为growth rate。
denseblock一个核心的点就是:每一层的输入来自前面所有层的输出。如下,
H2的输入 = 最开始的输入 + H1的输出 = k0 + k
H3的输入 = 最开始的输入 + H1的输出 + H2的输出 = k0 + k + k = H2的输入 + H2的输出
H4的输入 = 最开始的输入 + H1的输出 + H2的输出 + H3的输出 = k0 + k + k + k = H3的输入 + H3的输出
H5的输入 = 最开始的输入 + H1的输出 + H2的输出 + H3的输出 + H4的输出 = k0 + k + k + k + k= H4的输入 + H4的输出
单看上面四个式子黑色加粗的部分,可以总结:
- 假定输入层的特征图的channel数为k0,那么L层输入的channel数为k0+k(L-1)
再看后面蓝色加粗的部分,可知
- 每一层的输入 = 前一层的输入+前一层的输出
从densenet的caffe结构图也可以看出来:
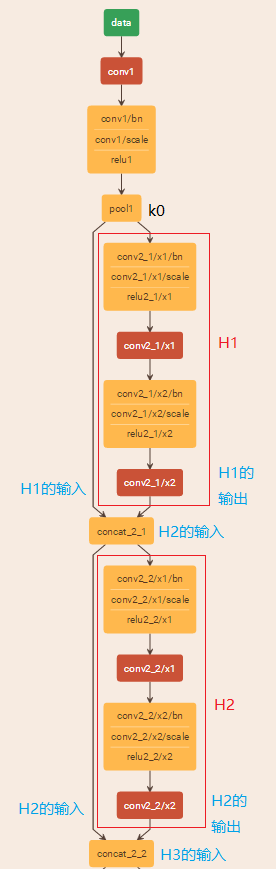
从fig2可以看到,dense block中每个H操作3*3卷积前面都包含了一个1*1的卷积操作,称为bottleneck layer,目的是减少输入的feature map数量,一方面降维减少计算量,又能融合各个通道的特征。那为什么要减少特征图的数量呢?
假设一个denseblock,有32个子结构,也就是有32个H操作,第32个子结构的输入是前面31层的输出结果,每层输出的channel是k(growth rate,这里假设k=32),那么如果不做bottleneck操作,第32层的H操作的输入就是31*32,近1000了。而加上1*1的卷积,代码中的1*1卷积的channel是growth rate*4,也就是128,然后再作为3*3卷积的输入。这就大大减少了计算量,这就是bottleneck。
block与block之间的连接采用transition layer
由于每个Dense Block结束后的输出channel个数很多,需要降维。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。为什么需要降维呢?
还按照我们刚刚的假设,第32层的3*3卷积输出channel只有32个(growth rate),但是紧接着还会像前面几层一样有通道的concat操作,即将第32层的输出和第32层的输入做concat,前面说过第32层的输入是1000左右的channel,所以最后每个Dense Block的输出也是1000多的channel,所以需要减少维度。
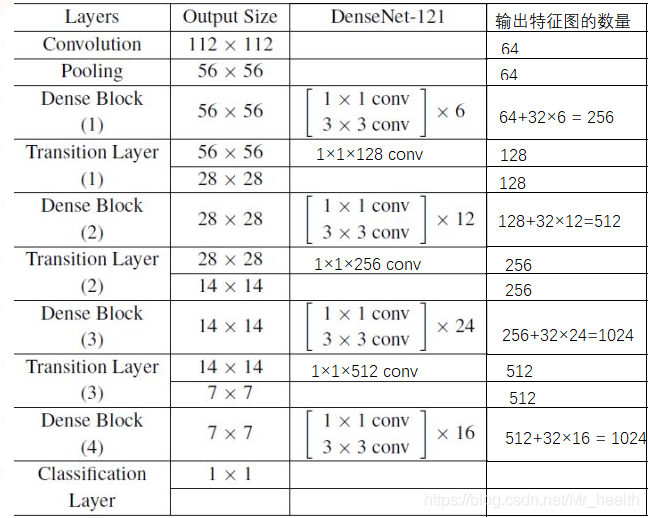
这里以densenet121为例(k=32),可以看到每一层transition layer的卷积核个数是不一样的,经过transition layer层后,上个dense block的输出特征图数量就会减少。