本博客是我看《基于高斯混合模型的频带扩展算法的研究》_于莹莹论文的心得,大家可以通过知网或邮件我获取。
摘要
现状:传统的电话语音带宽范围是300Hz~3400Hz,当带宽扩展到300~8000Hz是,语音在自然度、立体感方面会有明显的提升。
问题:高斯混合模型进行高频参数估计时过度平滑,频谱细节严重丢失。
原因:GMM估计的协方差参数的不准确造成的,尤其GMM估计的协方差矩阵是全矩阵而非对角矩阵。
创新一:提出基于用自组织特征映射和高频或者模型(SOFM-GMM)相结合的语音带宽扩展算法,
在练阶段,先采用自组织特征映射映射将训练数据进行无监督聚类,相似度高的特征参数将被聚到同一类;
训练完成后,对每一类训练数据分别进行高斯混合模型的训练,建立 GMM 模型,这样每个 GMM 模型能更精确的表征特征参数之间关系。
创新二:提出了基于码本映射和高斯混合模型相结合的频带扩展方法。码本映射的过程是基于 GMM 参数和特征参数的偏移矢量数据进行的。通过码本映射估计获得的高频特征参数,调整系数与高斯混合模型估计部分组合即得到待估的高频特征参数。
最后对两种改进方法进行了仿真,主观和客观评估。
绪论
选题意义
频带扩展的发展历史
常用的语音质量评估方法
客观评价方法
主观评价方法
第2章 语音信号产生模型以及特征参数
2.1 语音信号的源-滤波器模型
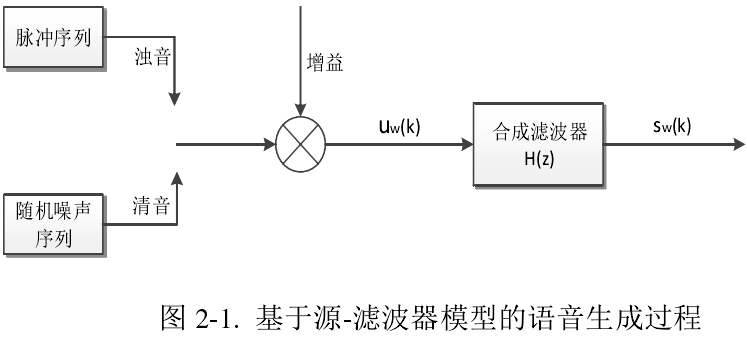
首先建立一个源-滤波器模型来描述语音的产生过程。他把语音分为两个部分,一部分是由源生成的激励信号,另一部分是由激励信号通过滤波器用来产生语音。
人类语音的生成过程涉及的主要器官包括肺、气管、喉、咽、口腔、鼻腔,肺部负责产生空气,自胸腔发出,把咽、口腔合起来称为声道,空气经过声道经过舌、唇、鄂而改变形状,不同形状的空气流决定着不同的语音,产生得特定的空气流类似脉冲波的就是激励信号,滤波器来模拟嘴唇、腔体、舌、下颚。下图是基于滤波器模型的语音生成过程:
参考文献: