1.二叉查找树&平衡二叉树
- B+树由二叉查找树+平衡二叉树演化而来
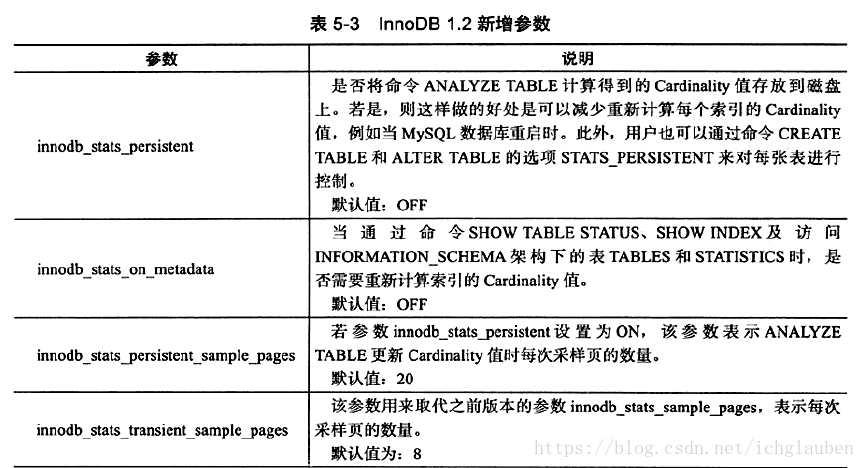
1.1下面来简单介绍一下二叉查找树 - 例子:
上图中:数字代表每个节点的键值
特点: - 1.左子树的键值总是<右子树的键值
- 2.右子树的键值总是>左子树的键值
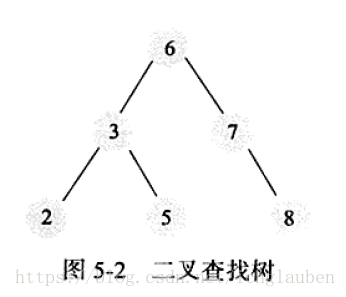
若对该树进行查找,如查键值为5的记录,先找到根6 因为6>5 往左子树找 得到3 < 5 再找右子树 找到键值 共需要3次
缺点
如果像上图一样查找的效率就低下了
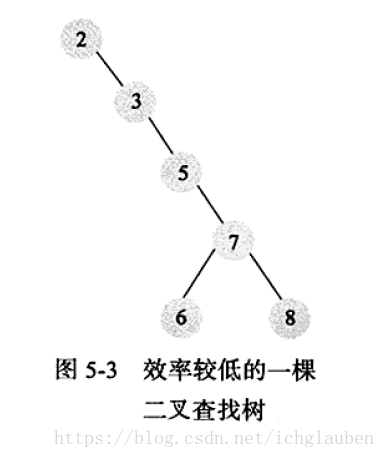
由此引入1.2AVL平衡二叉树
AVL定义:
- 1.首先符合二叉查找树定义
- 2.满足任何节点的两个子树高度差最大是1
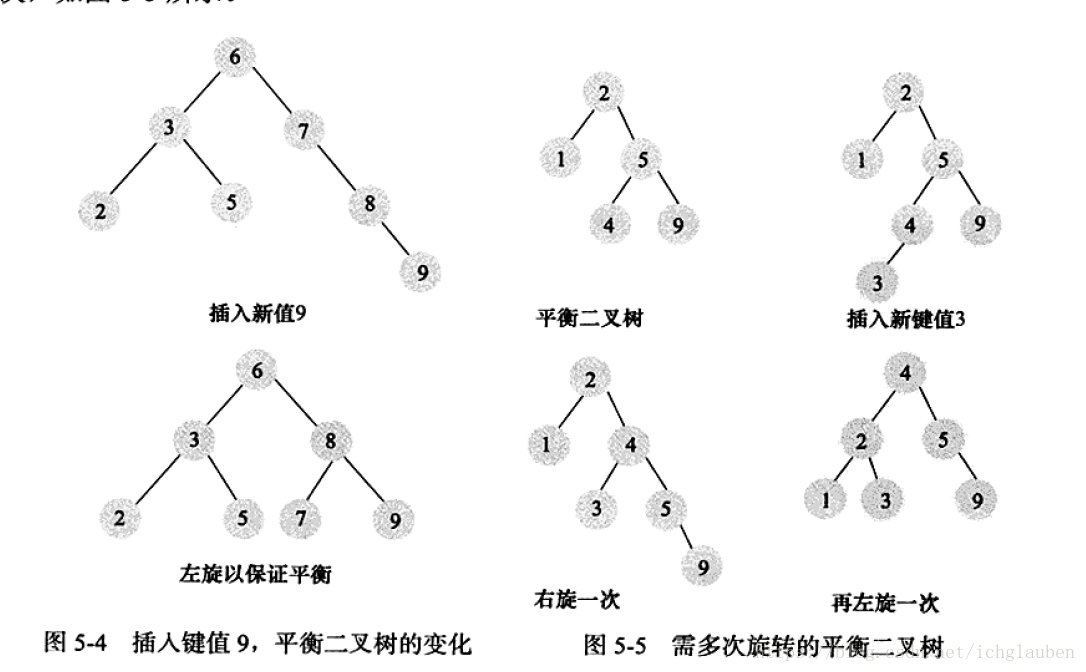
缺点:需要维护的代价非常大,一般需要1次或者多次左旋和右旋来得到插入或更新后树的平衡性
– 示例:
平衡树多用于内存结构对象中,因此维护的开销相对较小。
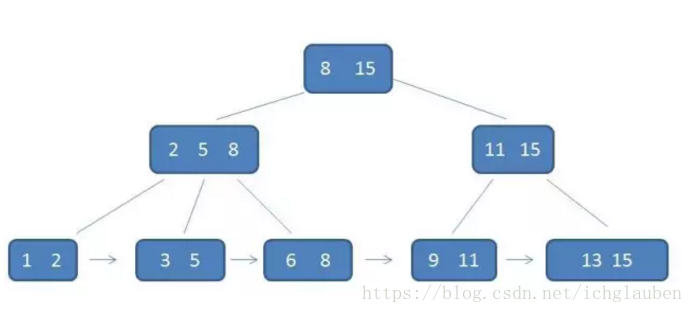
2.B+树
一颗B+树要满足以下特点:
- 1.有k个子树其中间的节点就包含了k个元素 每个元素不存数据 只是索引(指针) 所有值都保存在叶子节点中
- 2.所有的叶子节点都包含了全部的元素信息,包括指向该元素的指针,同时 叶子节点依照关键字的大小自小而大链接。
- 3.所有中间节点元素都同时存在于子节点,在子节点元素中最大(最小)的
简单概括: - 1.子树个数=非叶子节点数
- 2.非叶子节点仅是索引不存值 可以有重复的元素
- 3.叶子节点存值 用指针连接在一起
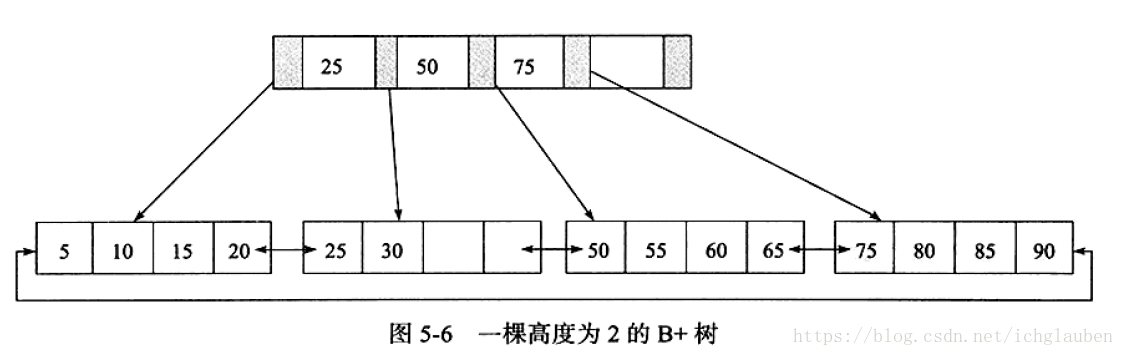
2.1B+树的插入情况
插入的时候要保证插入后叶子节点依然排序 需要考虑以下三种情况:
举例分析:

-
1.插入键值28 leaf page& index page都没有满 符合第一种情况 直接插入就可以
-
2.插入键值70 Leaf Page值满 Index Page未满 符合第二种情况
虽然没有显示,依然是双向链表指针 存在的
-
3.插入键值95 Leaf Page & Index Page都满了 需要做两次拆分
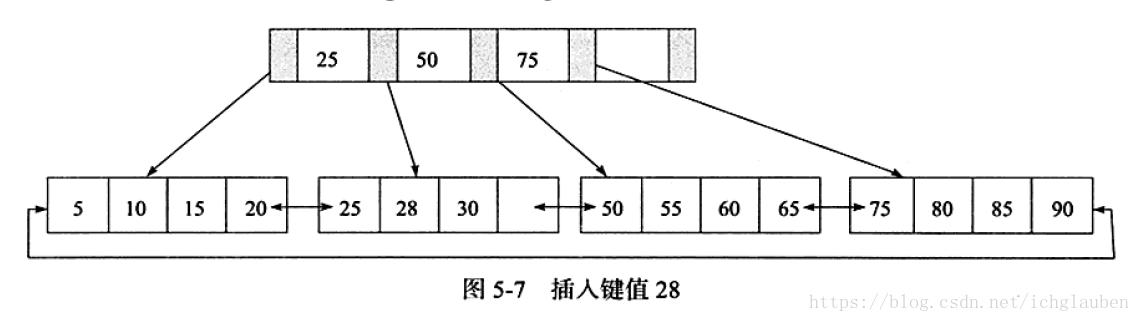
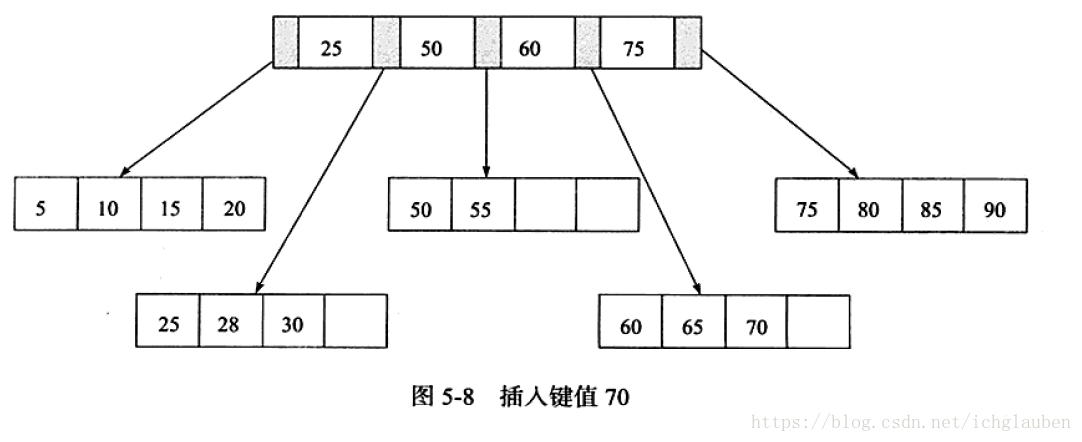
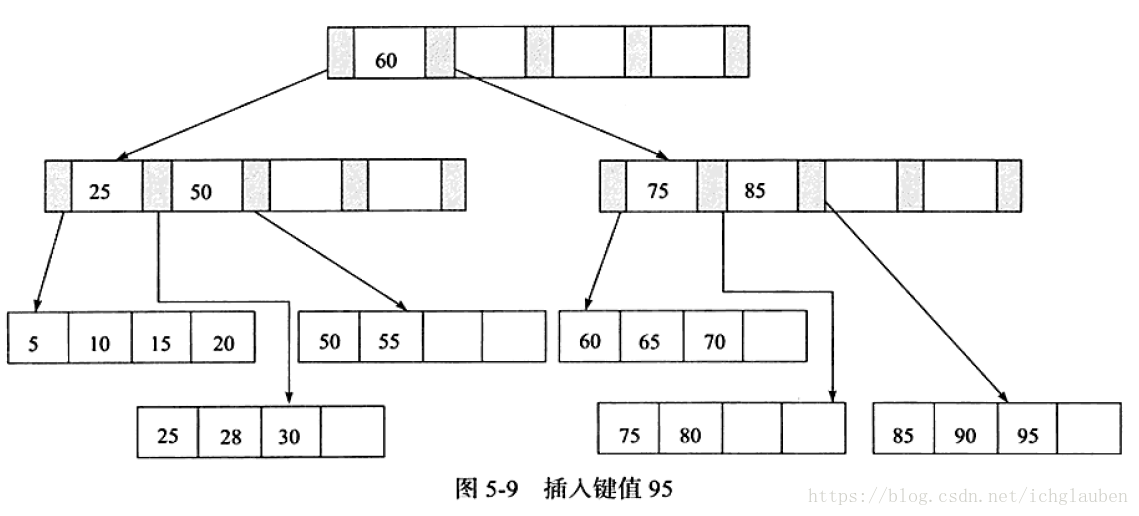
为了保持平衡对于新插入的键值需要做大量的拆分页(split)操作。
由于B+树主要用于磁盘,页的拆分表示磁盘的操作,所以尽量减少页的拆分操作。提供了旋转操作(Rotation)
看一下旋转发生的条件:
- 1.Leaf Page已满 左右兄弟节点没有满
- 2.不做拆分 而是将记录移到所在页的兄弟节点上
- 示例:插入70

2.2B+树的删除操作
同样也是满足三种情况 B+树的删除操作同样也要保证排序,根据其填充因子(fill factor 也就是非叶子节点部分 50%是最小值)的变化而衡量

示例
-
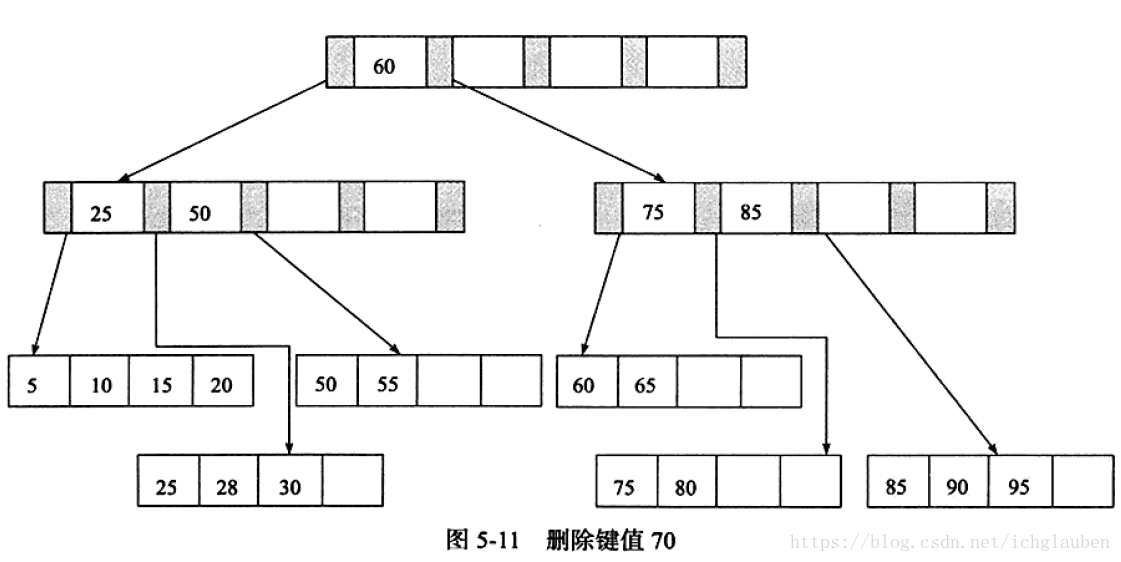
1.删除键值70 符合第一种情况
-
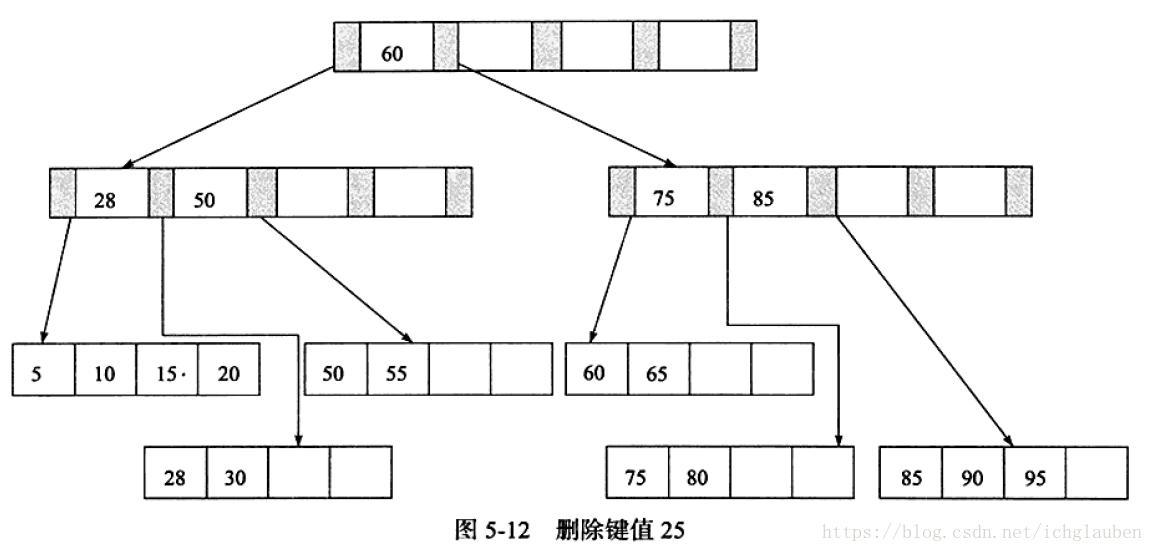
2.删除键值25 同时是Index Page节点
-
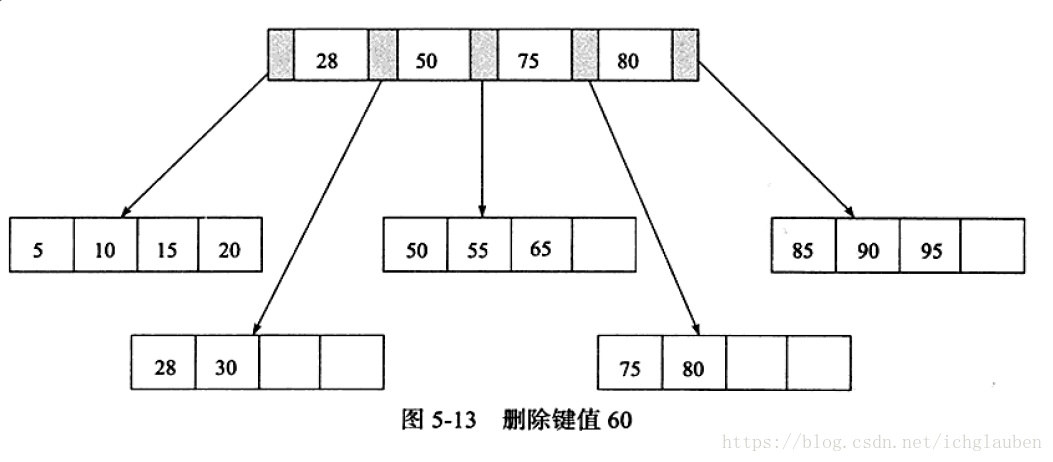
3.删除键值60 Fill Factor<50% 删除Index Page后 再次需要合并 Index Page
3.B+树索引
在DB中的特点:高扇出性,B+树的高度一般都是在2-4层 (查找某键值只需要2-4次IO)
B+索引分类
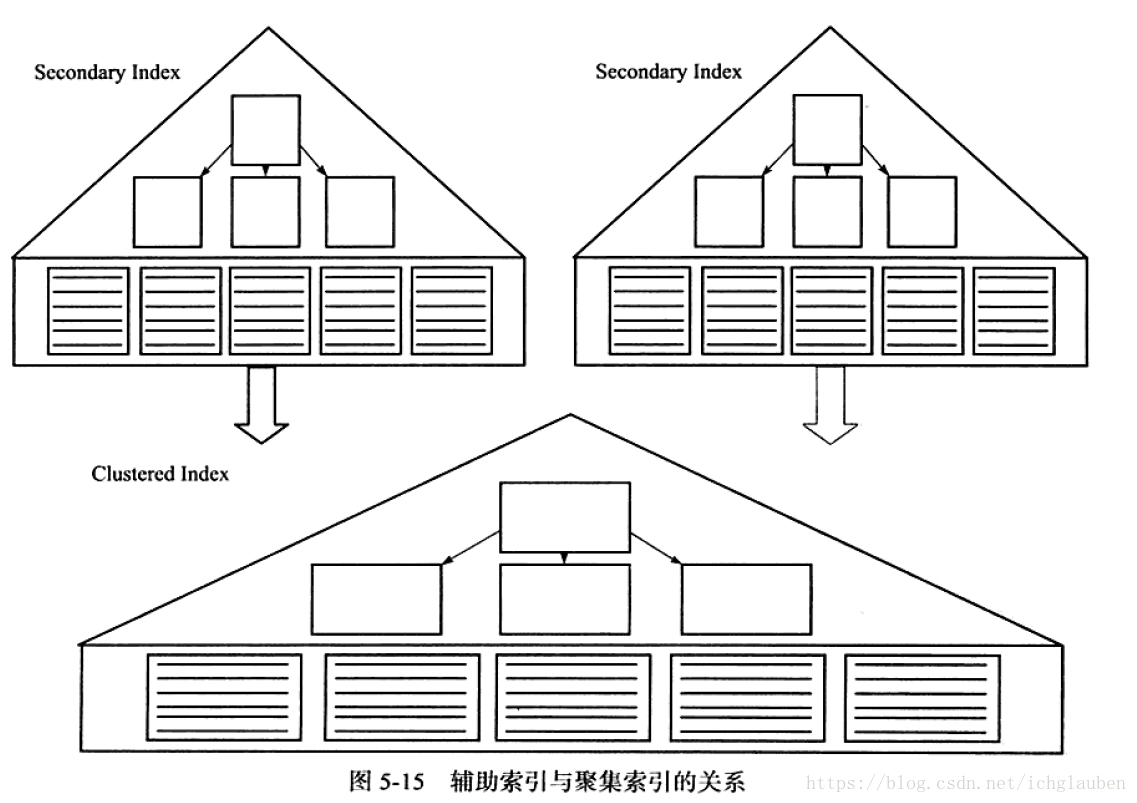
- 1.聚集索引(clustered index)
聚集索引就是按照每张表的主键构造一颗B+树,而且叶子节点就存放了表的所有行记录数据,也称聚集索引的叶子节点是数据页。每个数据页都由双向链表进行链接。**每个表只能有一颗B+数进行排序 只有一个聚集索引 **。
(接下来的表空间存储分析只能以后补上了 目前还没弄懂) - 2.辅助索引(Secondary Index 非聚集索引)
叶子节点并不包含全部数据。叶子节点包含了键值&&书签(bookmark)书签带领指向与索引相对应的行数据
和聚集索引的关系
辅助索引不影响数据在聚集索引中的组织,每张表可以有多个辅助索引。
InnoDB引擎遍历辅助索引找到主键索引的主键,再通过主键索引找到行记录。
3.1B+树索引的管理
3.1.1B+树索引的管理
创建和删除有两种:1.ALTER TABLE 2.CREATE | DROP INDEX
- 1.ALTER TABLE
- 2.CREATE | DROP INDEX


如果要查看:show index from tb
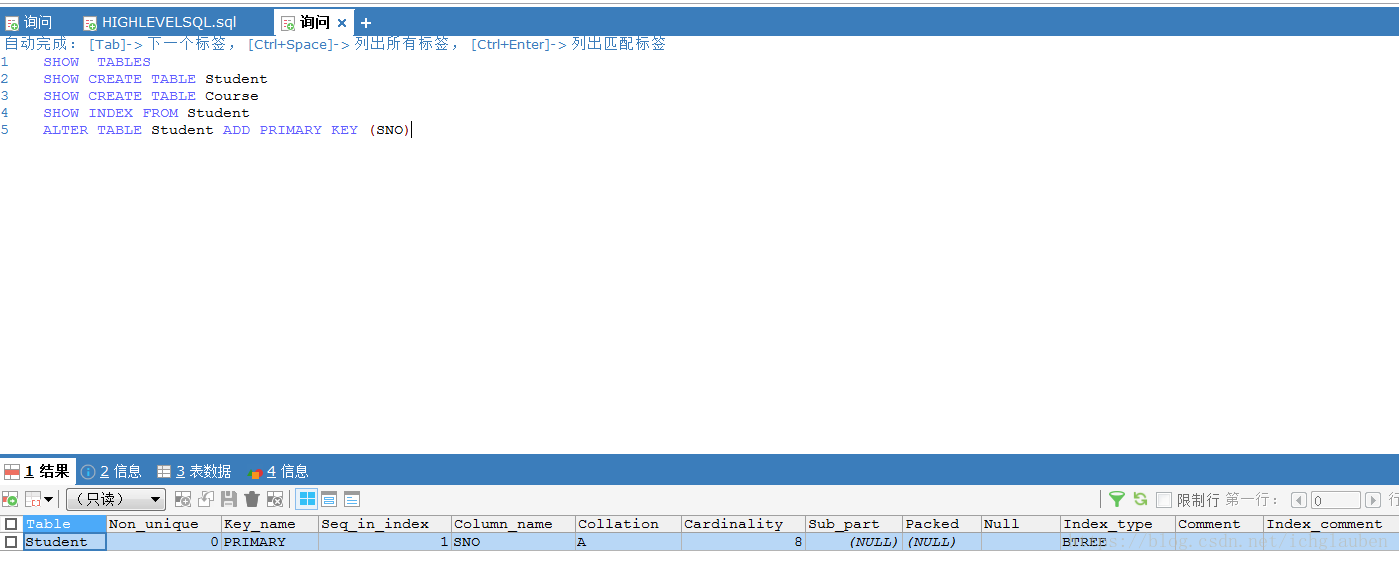
接下来分析每个参数的具体含义
- 1.Table:索引所在的表名
- 2.Non_unique:非唯一索引 如果聚集索引(primary key = 0)
- 3.Key_name:索引名字
- 4.Seq_in_index:索引中该列的位置
- 5.Column_name:索引列的名称
- 6.Collation:列以什么方式存储在索引中。两种结果 A | NULL A:B+树索引 表示排序的 NULL:如果使用了Heap存储引擎 建立Hash索引 显示NULL.HASH根据Hash桶存放索引数据 不对数据排序
- 7.cardinality :很关键的值 表示索引中唯一值的数目的估计值。 行数应尽可能为1.若非常小 考虑是否删除该索引
- 8.Sup_part:是否是列的部分索引(列只有部分被索引)NULL:整列被索引
- 9.Packed:关键字如何被压缩
- 10.NULL:是否索引列含有NULL值
- 11.Index_type:索引类型 InnoDB只支持B+树 显示为BTREE
- 12.Comment:注释
单独介绍一下Cardinality: 该值优化器根据该值判断是否使用这个索引 问题:不是实时更新(每次更新索引不会更新这个值) 建议更新完后使用 ANALYZE TABLE 命令。
- 1)Cardinality为NULL,在某些情况下可能发生索引建立了确没有用 同样的语句 一种走索引 另一种走全表扫描。建议:在非高峰时期,对应用程序下的几张核心表做ANALYZE TABLE操作。
3.1.2Fast Index Creation(FIC):
一般建索引的DDL操作过程:

总结一下:1)新建临时表(表结构用alter table实现) 2)把数据导入到tmp表中 3)删原表 4)把临时表重名为原来的表
这种方式非常繁琐 — 引入了FIC(快速索引建立)
辅助索引创建|删除流程:
- 1)存储引擎对建索引的表上加s锁 不需要删表 重建表 快速了 数据库可用性得到提高
- 2)删除辅助索引 需要更新内部视图 将辅助索引的空间标记为可用 同时删除DB内部视图上对该表索引定义即可
3.1.3Online Schema Change(有空要做个实验了!!!)
MySQL 大表在线DML神器–pt-online-schema-change
pt-online-schema-change的实现原理
OSC实现过程:


3.1.4DDL在线操作
MySQL5.6版本支持Online DDL操作,允许辅助索引创建同时 还允许其他INSERT DELETE UPDATE (DML)操作
以下几类DDL可以通过在线方式进行操作:
- 1.辅助索引的创建和删除
- 2.改变自增长
- 3.添加或删除外键约束
- 4.列的重命名
语法:

ALGORITHM:指定了创建或删除索引的算法。
COPY(按照5.1版本前工作 即要复制表进行创建删除) INPLACE(不需要创建临时表) DEFAULT(根据old_alter_table来判断是通过INPLACE | COPY算法 默认值为OFF 使用inplace的方式)
LOCK:索引创建或删除时对表添加锁的情况。
(1)NONE:执行索引或者删除操作时 对目标表不添加任何的锁 即事务仍然可以进行读写操作 不会收到阻塞。 可以获得最大并发度。
(2)SHARE:类似FIC 创建或删除索引加S锁。对于并发读事务依然可以执行 遇到写事务 会发生等待操作。如果存储引擎支持SHARE模式 会返回一个错误信息。
(3)EXCLUSIVE:执行索引创建或删除操作时,对目标表加上一个X锁 读写事务不能进行 所以会阻塞所有的线程,和COPY方式运行得到的状态类似,但不需要像COPY方式那样创建一张临时表。
(4)DEFAULT:首先判断当前操作是否可以用NONE模式,不能就判断是否使用SHARE模式了,最后判断是否可以使用EXCLUSIVE模式
实现Online DDL的原理:在执行创建或者删除操作的同时,将INSERT UPDATE DELETE这类DML操作日志写入到一个缓存中。待完成索引后重新应用到表上,达到数据一致性。
4.Cardinality值:
- 添加索引的条件:在访问表中很少使用一部分时使用B+树索引有意义。具有高选择性的 并且抽取小字段的数据可以建B+树索引
- 高选择性:取值范围大 如姓名 ID等大范围 (低选择性: 取值范围小 如性别字段 地区字段 类型字段 类型字段 可取值的范围很小)
4.1统计Cardinality值:
考虑统计的因素:(1)统计频率 触发更新为update & insert 更新一次就统计的话 频繁了(2)统计表数量级过大 统计时间长不好
- 更新Cardinality策略:
- 1.表中1/16的数据已发生过变化
- 2.stat_modified_counter>2000 000 000(防止更新次数只在一行 若更新了该次数 也需要更新统计)
采样过程 默认InnoDB存储引擎对8个叶子节点进行采样:
- 取得B+树索引中叶子节点的数量 记为A
- 随机取得B+树索引中的8个叶子节点 统计每个页不同记录的个数 即为P1,P2…P8
- 根据采样信息给出Cardinality的预估值:Cardinality=(P1+P2+…P8)*A/8
可以得到统计采样值不是精确值 可能每次得到的值都不一样