前序:
当你把你知道的东西,写下来,让人看明白是一种境界;当你能把自己写下来的东西给人讲明白,又是另一种境界。在这个过程中,我们都需要历练。
基于hadoop集群下海量离线数据存储和挖掘分析架构:
架构图采用主流的Hadoop+Hive+Hbase集群架构平台。最简单的利用,包含了基本的基于hadoop集群下的日志分析过程。但此架构图,又不仅局限于简单的基于日志数据处理。我们可以把它定位到,把基于传统数据挖掘技术,移植到Hadoop集群平台上,提高计算效率,节省时间,降低开发成本。说到这里就必须多说一点,传统数据挖掘和基于Hadoop集群下的数据分析过程有什么区别?
我想这也是一直困扰大家的问题。旁人看热闹,行人看门道。把基于传统数据挖掘的过程移植到hadoop集群中,好在哪儿?问题在于:传统数据挖掘过程,基于单机或放在内存比较大的小型机上去跑数据,去建模型,7-8GB的数据,在参数不多的情况下,建模的过程,我想稍微熟悉建模过程的人,会有一个时间上的概念,10几个小时或者上天已经是好的了。太耗时了,太耽误时间了。而当数据越来越大,就面临这一瓶颈。自此,分布式的概念提出来了,分布式出来了,自然就会引入集群的概念。集群就是一群机器处理一个问题,或集群中不同的机器处理不同阶段的问题。除此时间问题之外,还有什么优势?其实,也一直困扰着我,我一有机会就会向那些大牛去请教,还有什么优点,他们也是堂堂不知其所言。
这里再多说两句还有什么优势:1、非关系型数据(Nosql),类日志文件数据。2、实时性。但这两点又不是传统数据挖掘的核心。其实,一个时间节省的问题,就足可以为之探究了。
这里没有采用现主流基于内存计算引擎Spark集群架构。后续如有涉及,再细讨论。
1、数据存储层
功能:数据收集、处理、存储、装载
包含:数据集成、ETL、数据仓库
工具:Sqoop、Flume、Kettle、Hive。
简介:
(1)Sqoop:数据收集工具,用于把相关数据导入Hadoop集群中。
(2)Flume:分布式日志收集工具,适用于网站、服务器等日志文件的收集。
(3)Kettle:一种开源免费的ETL工具。还有很多收费的ETL工具。在中国这都免费。
(4)Hive:基于Hadoop集群架构下的数据仓库的建立工具。主要是为了,类SQL与SQL之间的转换。
数据存储层,是前提。而前提的前提,就是数据的收集与ETL,在前面的博客中提到前期数据搜集和ETL过程可能会占整个项目工程的75%甚至以上的时间。可见,前期的工作多么的重要,没有前面,后面无从谈起。
2、集群架构层
功能:离线数据分析系统
核心:大数据存储和集群系统:Hive0.12.0 & Hadoop2.2.0 & HBase0.96.1
简介:
(1)Hadoop:开源集群分布式架构平台。2.2.0为最新版本。
(2)HBase:面向列的分布式数据库,适合构建低并发延时性数据服务系统。
(3)HDFS:分布式文件系统,是海量数据存储的标准。
集群架构层:说的是,也是集群平台的核心。我们常说的搭建hadoop平台,一般指的就是Hive+Hadoop+HBase。这需要自己去按照说明文档,在linux下搭建平台。其实,在我们配置Hadoop相关系统文件的时候,我们已经可以测试数据了,我们可以通过上传一个不是很大数据,测试hadoop是否运行成功。HBase+Hive是为大数据处理准备的。这里不介绍如何去配置系统文件,综合网上相关的文档,配置安装应该都没有问题。
目的在于,梳理一下整个大数据挖掘整体的流程。在脑海里梳理一下,有一张架构图。
3、分布式计算引擎层
功能:针对密集型数据计算
核心:Yarn、MapReduce
简介:
(1)Yarn:分布式资源管理框架,也可以理解为管理类MapReduce这种分布式处理平台的框架。
(2)Map/Reduce:基于密集型离线数据分析框架。这区别于现在很火的基于内存数据处理的Spark架构。
这里可能涉及到数据处理的过程,在上一篇博客中,谈到MapReduce的内部机理。其实就是把数据分块分发到不同机器上并发处理数据,最后把处理完的数据整合到一起,输出。其实看似简单,细分到每一块,我们就会看到,数据是如何在单机上去走的。这里逃不掉到的是数据还是一行行的读取,你也没有别的办法。这里你要做的工作就是,去写MapReduce函数,这个是根据数据的类型,业务需求,去写相应的函数。
4、算法合成层
功能:集成数据挖掘算法
核心:HiveQL、R语言、Mahout
简介:
(1)HiveQL:上面提到,类SQL,这也是选择Hive的原因,有利于传统数据库操作员到NoSql数据库操作之间的转型。
(2)R语言:主要用与统计分析、绘图的语言等。提供了一套完整的数据处理、计算和制图软件系统,也为下面的数据可视化提供了前提。
(3)Mahout:主要是集成机器学习等相关经典算法的实现。可以更有效的提供,挖掘数据背后隐藏的规律。
算法合成层,其实是数据挖掘,数据规律之间挖掘的核心。通过这些经典的或优化过的算法,为我们在海量数据面前,挖掘出有用价值的数据提供了方面。如果大家,了解一些数据挖掘和机器学习的一些内容的话,我们会知道两个概念:一、训练集。二、测试集。这里我们也会更多的提到建模,而构建模型的两个范畴就是,构建训练集合测试集的过程。训练集,是把原始数据抽取一部分用来构建模型,找到其中的一些规律。然后用剩下的数据,当测试集,去测试模型构建的准确率。其实更深入讨论一下,我们就会面临一个业界头疼的问题,准确率问题。因为我们所有的测试都是针对线下的数据去构建模型,这种方式对离线数据分析没有太大的影响,原因在于:离线数据,是不可变的,在很大情况下满足,在训练集测试的规律满足测试集的规律。而在更多的情况下,如基于实时线上数据的机器学习,这要求就非常的高了。这就会遇到一个通用的诟病:如何解决线下测试准确了极高的模型,如何保证在线上准确率却很差。他们给出的办法:就是没有办法,调参数,不断的测试,提高准确率。
这里不再多说,先梳理整个架构。
5、数据可视化层
其实上面已经讲到了一个可视化集成工具,就是R语言。当我们把通过Hadoop集群,业务梳理后的数据再写回HDFS中时候,这些数据有些已经是有规律的数据了。有些数据是提取出来制作报表、饼图或柱状图等。其实对上面已经处理完的数据还有下一步的处理过程就是:把HDFS或Hive数据仓库中的数据导入传统关系型数据库。用传统可视化工具进行展示,这是目前很主流的方法。当数据导入传统关系型数据库中,最后一步就是BI,传统BI。大家都在忙着吵大数据概念,可不要把传统的优势忘记,不然也只是丢了西瓜,捡了芝麻。
说了这么多废话,其实就是为了引出,基于传统离线数据存储和挖掘架构图。这是为我们自己接下来的工作,提前梳理好要做的内容。
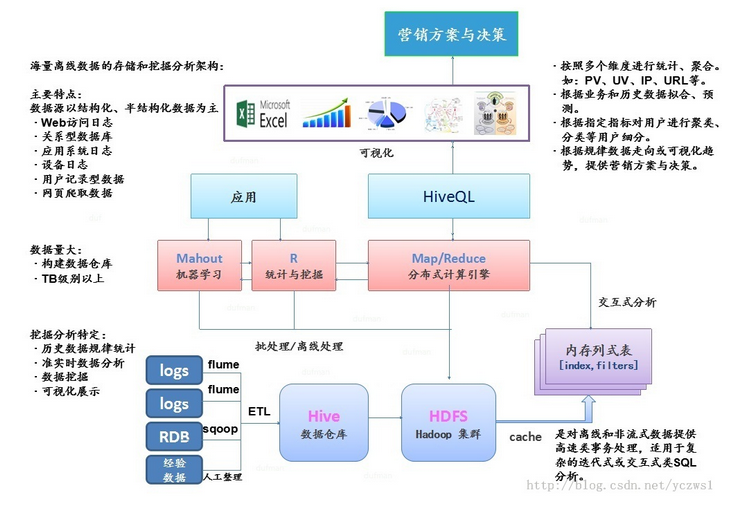
总结:
上面的架构图基本已经涉及基于传统数据挖掘移植到Hadoop集群的一些流程。为不清楚或初学者提供一个解决方案,知道一个流程应该从哪方面入手。对于熟悉整个流程的Hadoop工程师来说,可能上面的工作是多此一举。但是能整理出来,在时间上的消费,为后来者提供一个解决方案。
长按识别关注我们,每天都有技术和精彩内容分享哦!~