大数据(Big Data)是指那些超过传统数据库系统处理能力的数据。它的数据规模和转输速度要求很高,或者其结构不适合原本的数据库系统。为了获取大数据中的价值,我们必须选择另一种方式来处理它。
数据中隐藏着有价值的模式和信息,在以往需要相当的时间和成本才能提取这些信息。如沃尔玛或谷歌这类领先企业都要付高昂的代价才能从大数据中挖掘信息。而当今的各种资源,如硬件、云架构和开源软件使得大数据的处理更为方便和廉价。即使是在车库中创业的公司也可以用较低的价格租用云服务时间了。
对于企业组织来讲,大数据的价值体现在两个方面:分析使用和二次开发。对大数据进行分析能揭示隐藏其中的信息,例如零售业中对门店销售、地理和社会信息的分析能提升对客户的理解。对大数据的二次开发则是那些成功的网络公司的长项。例如Facebook通过结合大量用户信息,定制出高度个性化的用户体验,并创造出一种新的广告模式。这种通过大数据创造出新产品和服务的商业行为并非巧合,谷歌、雅虎、亚马逊和Facebook,它们都是大数据时代的创新者。
随着互联网时代的发展。大数据化时代的到来给很多企业带来本质的改变。在制造系统和商业环境变得日益复杂的今天,利用大数据去解决某些问题和积累知识或许是更加高效、便捷的方式。“大数据的目的并不是追求数据量大,而是通过系统式的数据收集和分析手段,实现价值的最大化。所以推动智能制造的并不是大数据本身,而是大数据的分析技术,”数据本身不会说话,也不会直接创造价值,真正为企业带来价值的是数据经过实时分析后及时地流向决策链的各个环节,或是成为面向客户创造价值服务的内容和依据。大数据技术的快速发展,也将用户的行为追踪变得更为便利。
如何利用好大数据的首先一步是如何获取到这些数据,由于数据低值性及数据量的庞大,获取数据事实上是一个十分困难的过程。有没有什么高效的办法可以帮助我们获取这些高价值的数据,毕竟人工的复制黏贴不仅复杂而且非常的低效,因此后羿工程师团队不断的摸索和开发,终于研究出一款基于人工智能技术的爬虫工具,只需要在软件中输入网址就能够自动识别网页数据,无需配置即可完成数据采集,是业内首家支持三种操作系统(包括Windows、Mac和Linux)的采集软件。同时这是一款真正免费的数据采集软件,对采集结果导出没有任何限制,即使是没有编程基础的小白用户也可轻松实现数据采集要求。
我们以拉勾网为例,为大家介绍如何采集拉勾网上的职位招聘信息。
首先,复制需要采集的网址,打开软件输入网址,新建智能采集任务。
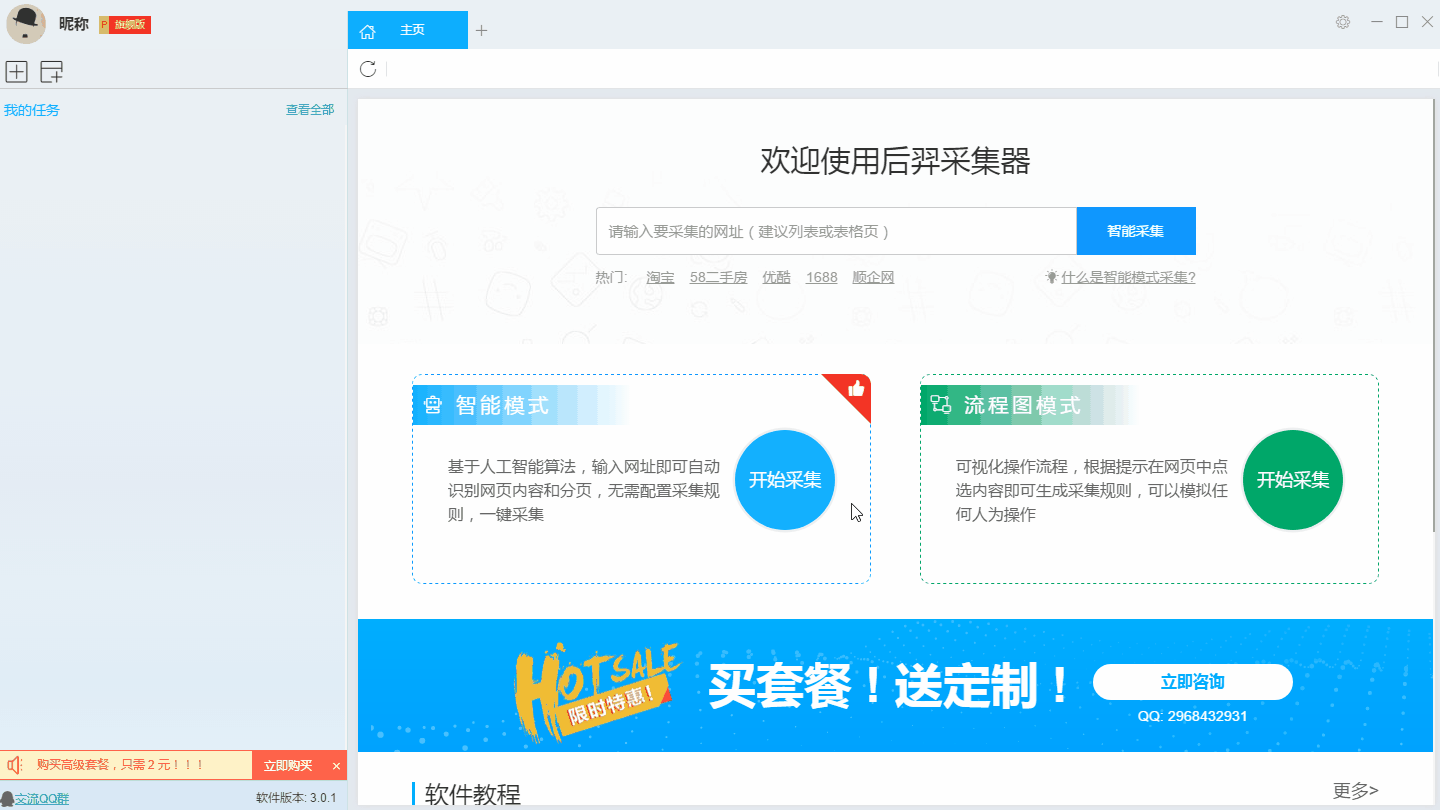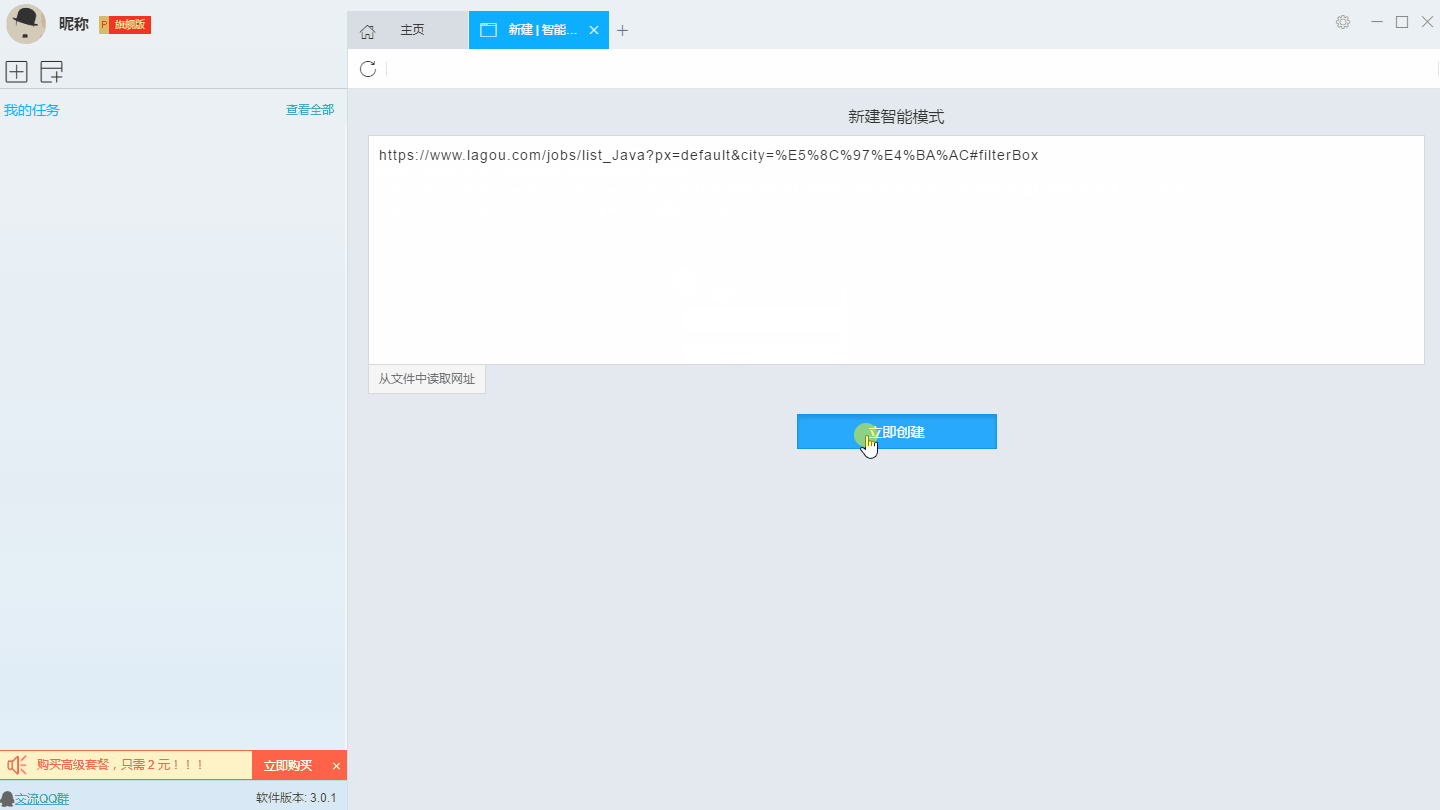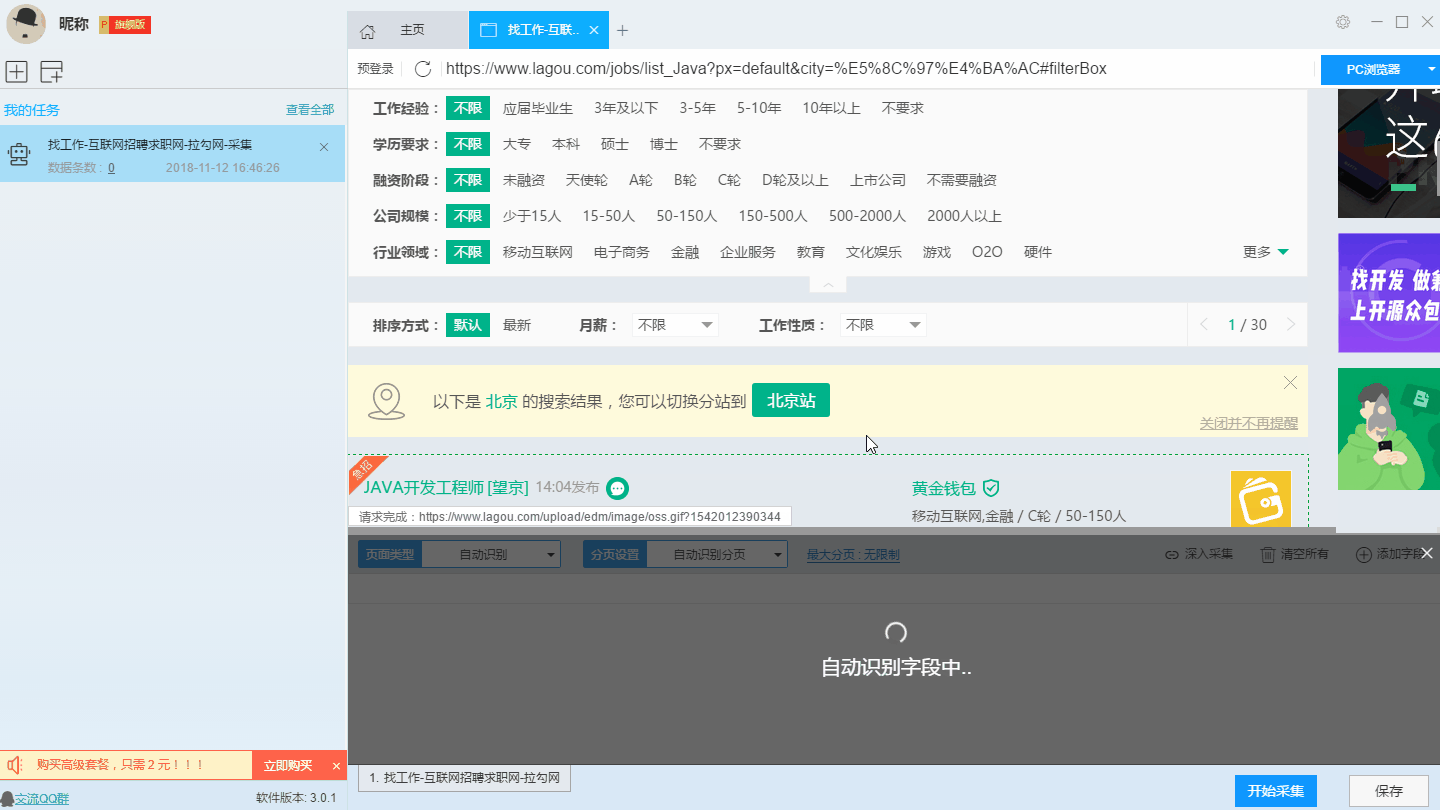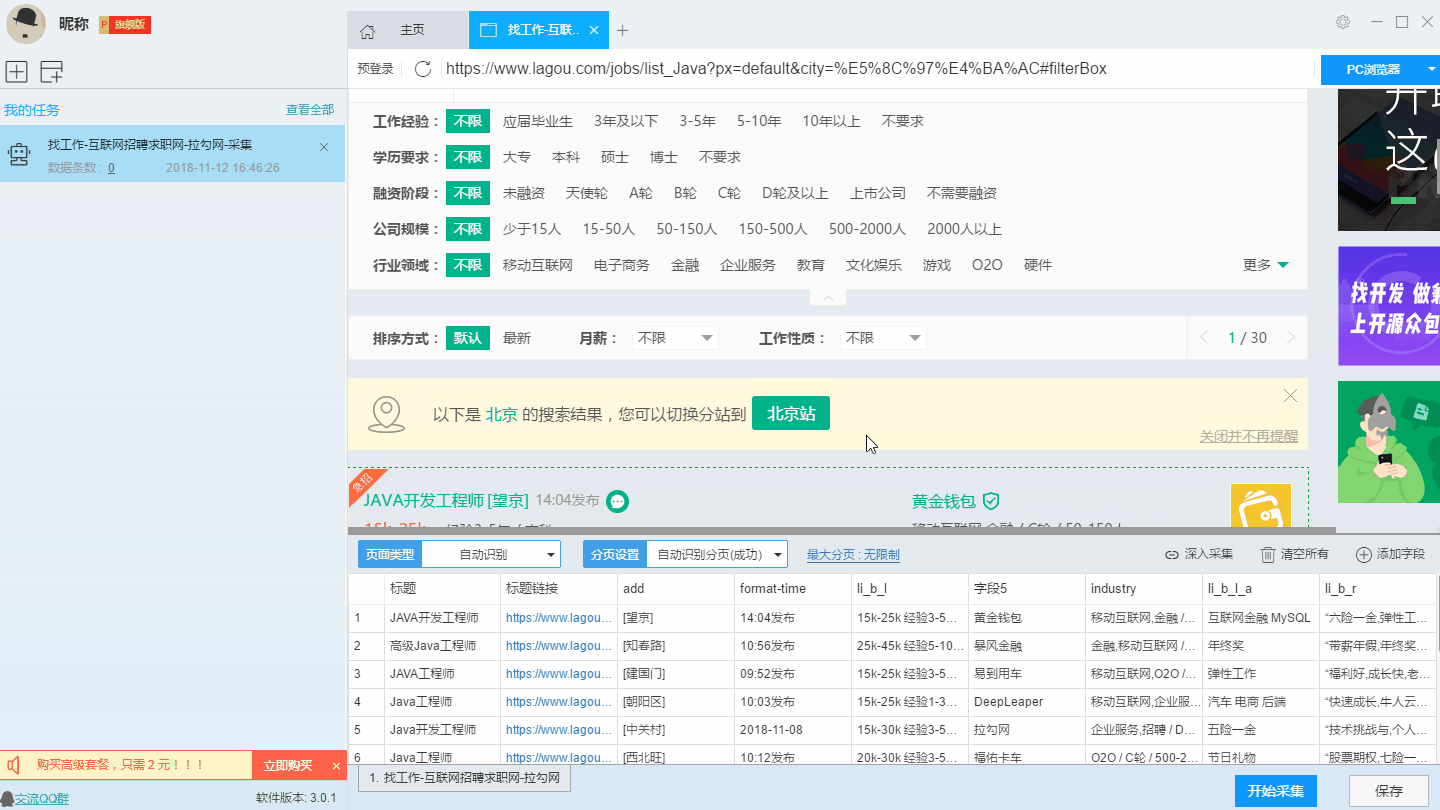
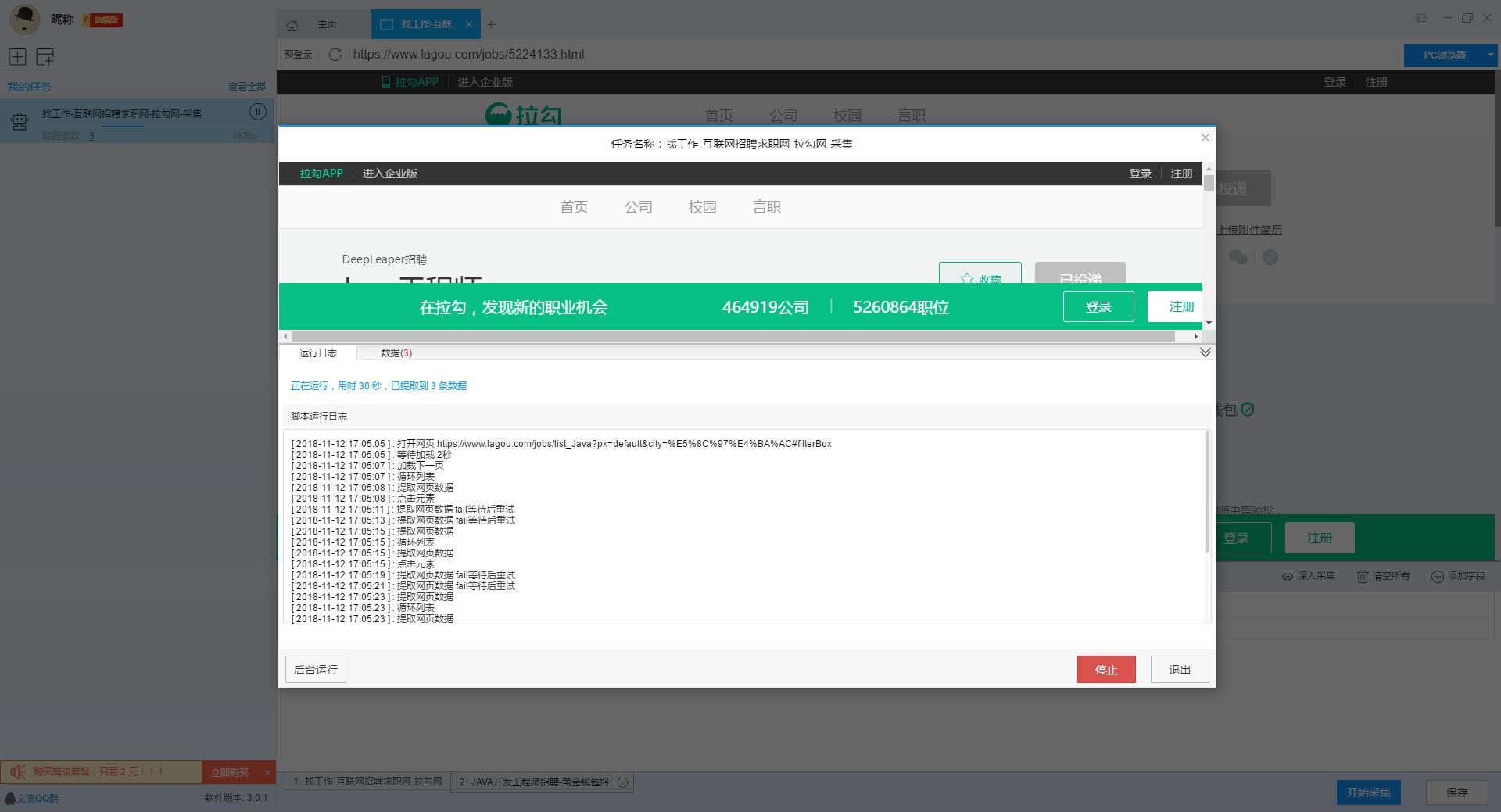
在智能模式下,我们输入网址后软件即可自动识别出页面上的数据并生成采集结果,每一类数据对应一个采集字段,我们可以右击字段进行相关设置,包括修改字段名称、增减字段、处理数据等。
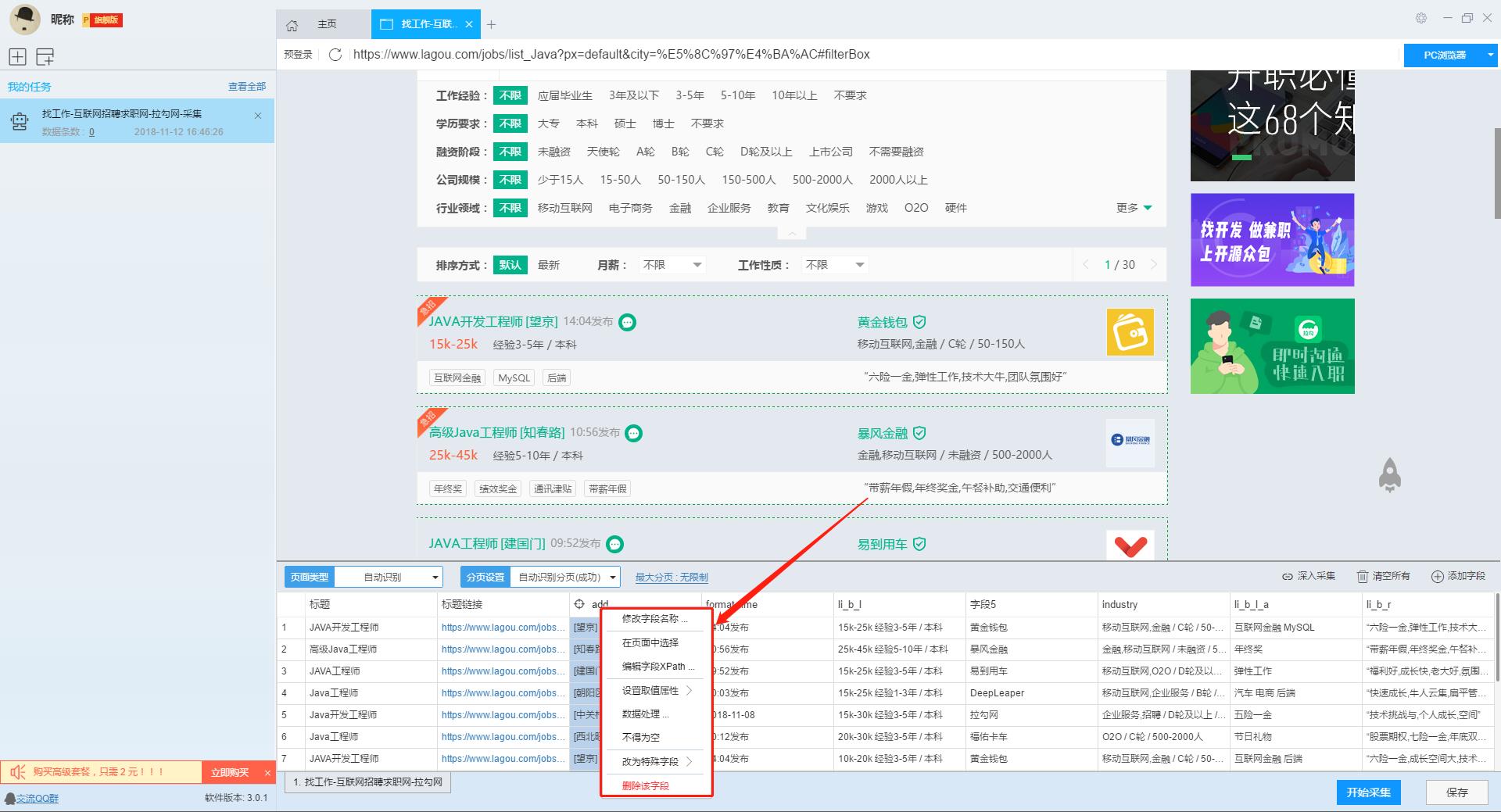
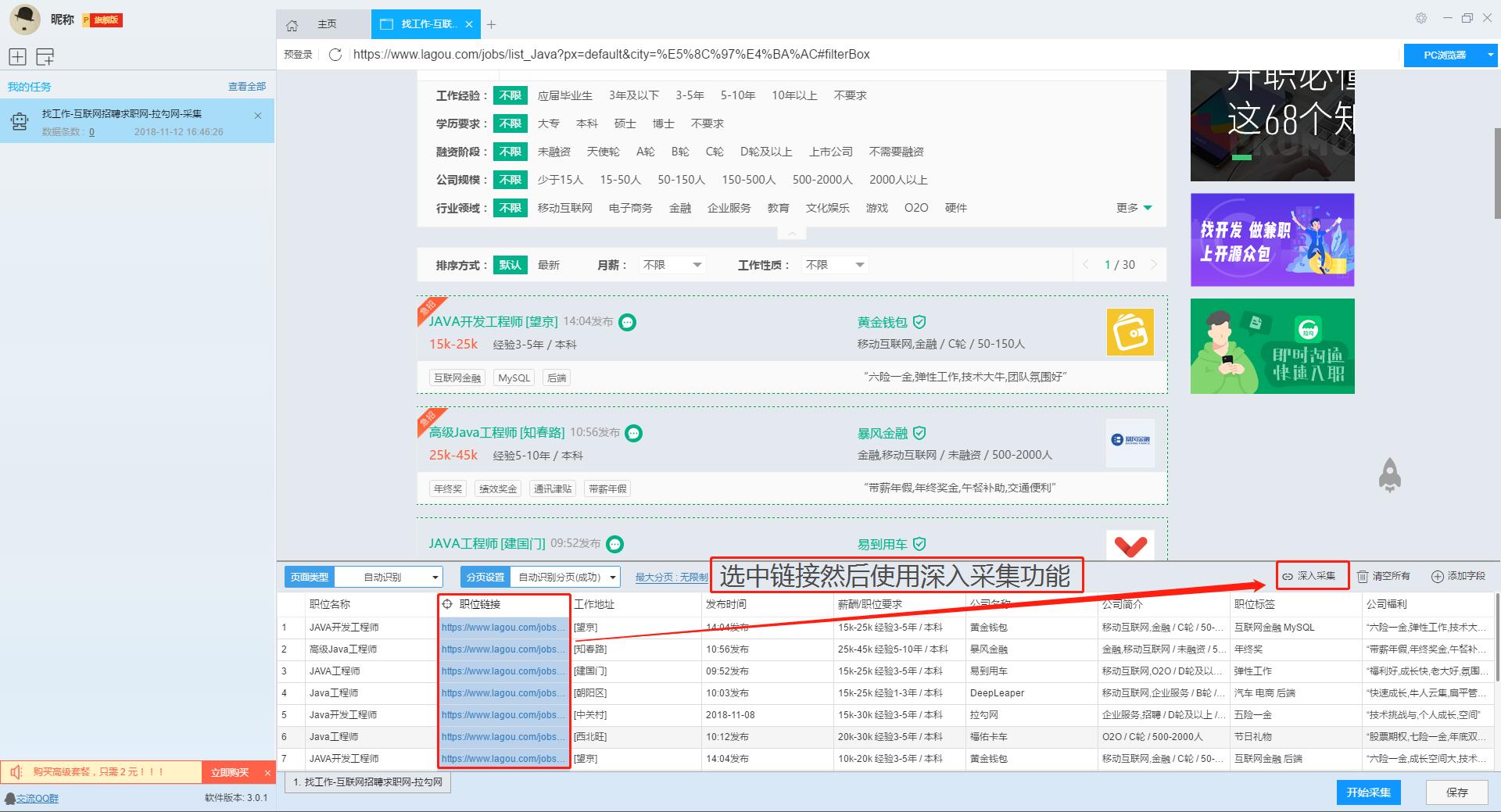
在列表页上展示出了大部分信息,如果需要采集招聘职位的具体要求及公司情况的话,我们需要右击职位链接使用“深入采集”功能,跳转到详情页进行采集。
接着我们点击“保存并启动”按钮,可在弹出的页面中进行一些高级设置,包括定时启动、自动入库和下载图片,本次示例中未使用到这些功能,直接点击“启动”运行爬虫工具。

数据采集完毕后,我们可以导出数据,软件提供多种导出方式,大家可以自由选择导出方式。
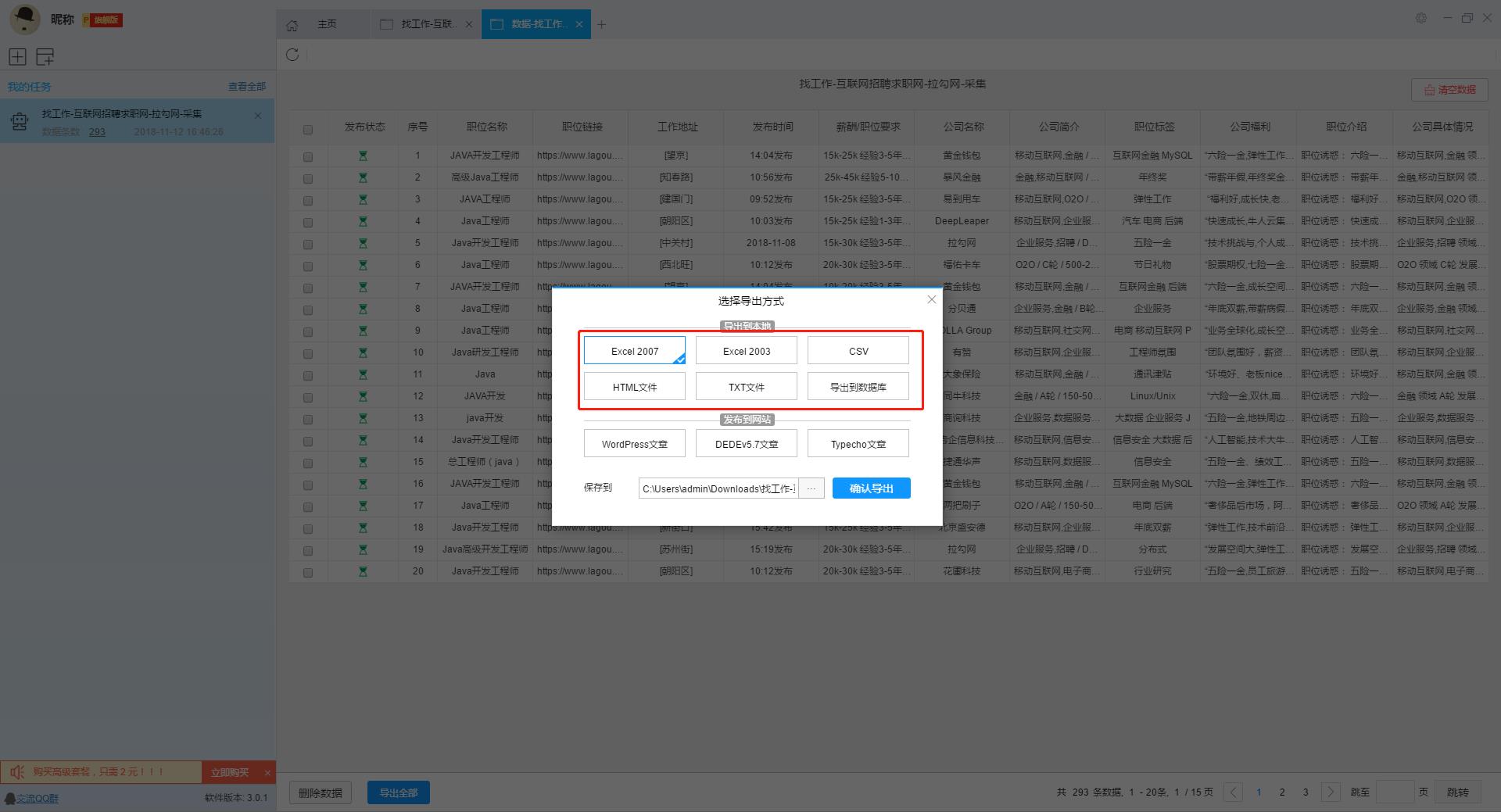
我们导出了一个Excel表格的文件,在这个表格上我们可以看到数据都完整的采集出来了,大家可以直接使用这些数据,也可以在这个基础上对数据进行加工处理。