hashtable概述
Hash_table可提供对任何有名项(named item)的存取、删除和查询操作。由于操作对象是有名项,所以hash_table可被视为是一种字典结构(dictionary)。
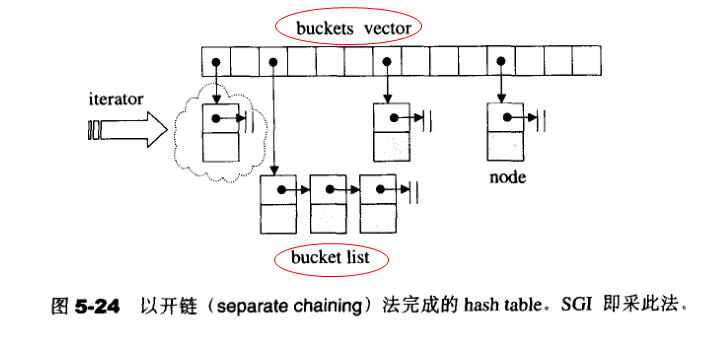
Hash_table使用名为hash faction的散列函数来定义有名项与存储地址之间的映射关系。使用hash faction会带来一个问题:不同的有名项可能被映射到相同的地址,这便是所谓的碰撞(collision)问题,解决碰撞问题的方法主要有三种:线性探测(linear probing)、二次探测(quadratic probing)、开链(separate chaining)。
SGI STL的hash table采用的是开链法。即在每个表格元素中维护一个list;hash function为我们分配某一个list,然后就可以在那个list上执行元素的插入、搜寻、删除等操作。
hashtable的节点
buckets所维护的linked list ,并不采用STL的list 或 slist,而是自行维护上述的hash table node。至于buckets 聚合体,则以vector完成,以便有动态扩充能力。
//其实就是个单链表
template <class Value>
struct __hashtable_node
{
__hashtable_node* next;
Value val;
};hashtable的迭代器
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc>
struct __hashtable_iterator {
typedef hashtable<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc>
hashtable;
typedef __hashtable_iterator<Value, Key, HashFcn,
ExtractKey, EqualKey, Alloc>
iterator;
typedef __hashtable_const_iterator<Value, Key, HashFcn,
ExtractKey, EqualKey, Alloc>
const_iterator;
typedef __hashtable_node<Value> node;
......
node* cur;//迭代器目前指向哪个节点
hashtable* ht;//保持对容器的连结关系(因为需要从bucket跳到另一个bucket)
__hashtable_iterator(node* n, hashtable* tab) : cur(n), ht(tab) {}
__hashtable_iterator() {}
reference operator*() const { return cur->val; }
#ifndef __SGI_STL_NO_ARROW_OPERATOR
pointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */
iterator& operator++();
iterator operator++(int);
bool operator==(const iterator& it) const { return cur == it.cur; }
bool operator!=(const iterator& it) const { return cur != it.cur; }
};迭代器的前进
注意:hash table的迭代器没有后退操作(operator--())。
template <class V, class K, class HF, class ExK, class EqK, class A>
__hashtable_iterator<V, K, HF, ExK, EqK, A>&
__hashtable_iterator<V, K, HF, ExK, EqK, A>::operator++()
{
const node* old = cur;
//如果当前链表不为空
cur = cur->next;
if (!cur) {
//得到当前是在哪个桶子
size_type bucket = ht->bkt_num(old->val);
//移到下一个桶子,桶子的地址也就是首元素的地址
while (!cur && ++bucket < ht->buckets.size())
cur = ht->buckets[bucket];
}
return *this;
}hashtable的数据结构
buckets是以vector为基础完成的。
hashtable 的模板参数相当多,包括:
(1)Value:节点的实值型别;
(2)Key:节点的键值型别;
(3)HashFcn:hash function的函数型别;
(4)ExtractKey:从节点中取出键值的方法(函数或仿函数);
(5)EqualKey:判断键值相同与否的方法(函数或仿函数);
(6)Alloc:空间配置器,缺省使用std::alloc。
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey,
class Alloc>
class hashtable {
...
}虽然开链法并不要求表格大小(也就是vector的大小)必须为质数,但SGI STL 仍然以质数来设计表格大小,并且先将28个质数(逐渐呈现大约两倍的关系)计算好,已备随时访问,同时提供一个函数__stl_next_prime(unsigned long n),用来查询在这28个质数之中,“最接近某数并大于某数”的质数。
hashtable的构造与内存管理
插入操作
//插入元素,不允许重复
pair<iterator, bool> insert_unique(const value_type& obj)
{
resize(num_elements + 1);//判断是否需要重建表格
return insert_unique_noresize(obj);
}
//插入元素,允许重复
iterator insert_equal(const value_type& obj)
{
resize(num_elements + 1);
return insert_equal_noresize(obj);
}判断时候需要重建表格,如果不需要,立刻返回。否则进行重建。
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::resize(size_type num_elements_hint)
{
const size_type old_n = buckets.size();
//拿插入以后所有的元素数量与vector的大小也就是桶数的大小做比较
//如果比现有的vector的size()大,则重建
if (num_elements_hint > old_n) {
const size_type n = next_size(num_elements_hint);
if (n > old_n) {
vector<node*, A> tmp(n, (node*) 0);
__STL_TRY {
//处理每一个旧的bucket
for (size_type bucket = 0; bucket < old_n; ++bucket) {
node* first = buckets[bucket];
while (first) {
//找出每个节点落在哪个桶子内
size_type new_bucket = bkt_num(first->val, n);
buckets[bucket] = first->next;
first->next = tmp[new_bucket];
tmp[new_bucket] = first;
first = buckets[bucket];
}
}
buckets.swap(tmp);
}
}
}
}复制和整体删除
整个hash table 由vector 和 linked-list 组合而成,因此,复制和整体删除,都需要特别注意内存的释放问题。hashtable提供了两个相关函数:clear()和copy_from()。
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::clear()
{
//针对每一个bucket
for (size_type i = 0; i < buckets.size(); ++i) {
node* cur = buckets[i];
//每个bucket中的每个节点
while (cur != 0) {
node* next = cur->next;
delete_node(cur);
cur = next;
}
buckets[i] = 0;
}
num_elements = 0;
buckets vector并未释放调空间,仍保持原来的大小,只是将list的内存进行了析构
}