前言
是的,你没看错Hashtable确实怎么写的,在Java中,基本上是不可能出现这种不符合命名规范的Hashtable。我也很纳闷Java是如何容忍这个问题的存在呢?Jajaja...上一篇文章中我们阐述了HashMap的数据结构和扩容机制。今天我们来一起学习常与HashMap一同提起的Hashtable——这个长的像怪胎一样的类的源码。
- * 概述
- * Hashtable存储的内容是键值对(key-value)映射,其底层实现是一个Entry数组+链表;
- * Hashtable和HashMap一样也是散列表,存储元素也是键值对;
- * HashMap允许key和value都为null,而Hashtable都不能为null,Hashtable中的映射不是有序的;
- * Hashtable和HashMap扩容的方法不一样,Hashtable中数组默认大小11,扩容方式是 old*2+1。
- * HashMap中数组的默认大小是16,而且一定是2的指数,增加为原来的2倍。
- * Hashtable继承于Dictionary类(Dictionary类声明了操作键值对的接口方法),实现Map接口(定义键值对接口);
- * Hashtable大部分类用synchronized修饰,证明Hashtable是线程安全的。
1.8版本Hashtable的重要属性
| private transient Entry<?,?>[] table; |
私有Entry数组 |
| private transient int count; |
元素数量 |
| private int threshold; |
阈值 |
| private float loadFactor; |
加载因子 |
| private transient int modCount = 0; |
用来实现"fail-fast"机制的(也就是快速失败)。所谓快速失败就是在并发集合中,其进行迭代操作时,若有其他线程对其进行结构性的修改,这时迭代器会立马感知到,并且立即抛出ConcurrentModificationException异常,而不是等到迭代完成之后才告诉你(你已经出错了)。 操作计数 |
| private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; |
规定的最大数组容量 |
从上面的Hashtable中的属性来看,1.8版本的Hashtable与HashMap有很大的不同,(或者说他俩本来也不是一家人)。接下来我们来看一看Hashtable的构造函数。
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
public Hashtable() {
this(11, 0.75f);
}
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}额,上面的代码应该没有什么难度了吧。如果还没看过HashMap代码的先看HashMap,看过之后就会觉得这段代码易于理解。另外,从上面的第二段代码来看Hashtable是以默认长度为11的Entry数组构成,默认的加载因子没有变化。第三段代码中阈值的生成是与HashMap所不同的。HashMap调用了transSizeFor生成阈值,保证了阈值比为当前容量大小的最小的2的自然数幂。Hashtable只是简单的使用加载因子和当前容量乘积与最大容量之间的最小值。
举例说一下吧:
HashMap:如果指定容量大小为10,调用transSizeFor后返回16(16>10 && 8<10).
Hashtable:如果指定容量大小为10,返回阈值为7.
接下来我们开始从put、get方法了解掌握Hashtable
/**
* 设置键值对,key和value都不可为null,设置顺序:
* 如果Hashtable含有key,设置(key, oldValue) -> (key, newValue);
* 如果Hashtable不含有key, 调用addEntry(...)添加新的键值对;
*
* @param key the hashtable key
* @param value the value
* @return the previous value of the specified key in this hashtable,
* or <code>null</code> if it did not have one
* @throws NullPointerException if the key or value is
* <code>null</code>
* @see Object#equals(Object)
* @see #get(Object)
*/
public synchronized V put(K key, V value) {
// value为空抛出空指针异常
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
//key的hashCode是调用Object的hashCode()方法,
//是native的方法,如果为null,就会抛出空指针异常
int hash = key.hashCode();
//因为hash可能为负数,所以就先和0x7FFFFFFF相与
//在HashMap中,是用 (table.length - 1) & hash 计算要放置的位置
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
//遍历链表,找到与之key的哈希值相同的节点,新值替换旧值,然后返回旧值
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
// 如果key对应的值不存在,就调用addEntry方法加入
addEntry(hash, key, value, index);
return null;
}从以上代码来看,HashMap与Hashtable生成Key的索引是不相同的,插入结点也不会进行转化,所以Hashtable是一个基于Entry数组+Entry链表的数据结构。相对于HashMap的红黑树结构,比较好掌握。从另一方面来看,Hashtable并没有很好的处理哈希冲突,链表过长时,还会造成查找数据困难。
/**
* 当键值对个数超过阈值,先进行rehash然后添加entry,否则直接添加entry
*/
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?, ?> tab[] = table;
// 当前元素大于等于阈值,就扩容并且再计算hash值
if (count >= threshold) {
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K, V> e = (Entry<K, V>) tab[index];
// 和HashMap不同,Hashtable选择把新插入的元素放到链表最前边,而且没有使用红黑树
tab[index] = new Entry<>(hash, key, value, e);
count++;
}感觉HashMap处理哈希冲突要积极的多
/**
* 当Hashtable中键值对总数超过阈值(容量*装载因子)后,内部自动调用rehash()增加容量,重新计算每个键值对的hashCode
* int newCapacity = (oldCapacity << 1) + 1计算新容量 = 2 * 旧容量 + 1;并且根据新容量更新阈值
*/
@SuppressWarnings("unchecked")
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
// 新的大小为 原大小 * 2 + 1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
// 拷贝每个Entry链表
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
// 重新计算每个Entry链表的表头索引(rehash)
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
// 开辟链表节点
e.next = (Entry<K,V>)newMap[index];
// 拷贝
newMap[index] = e;
}
}
}扩容后的Hashtable,重新计算旧Hashtable中每个元素的哈希值,并放入到新的Hashtable中,此后将元素插入到链表最前方。现在还是画个大致图形吧!以便加深理解。
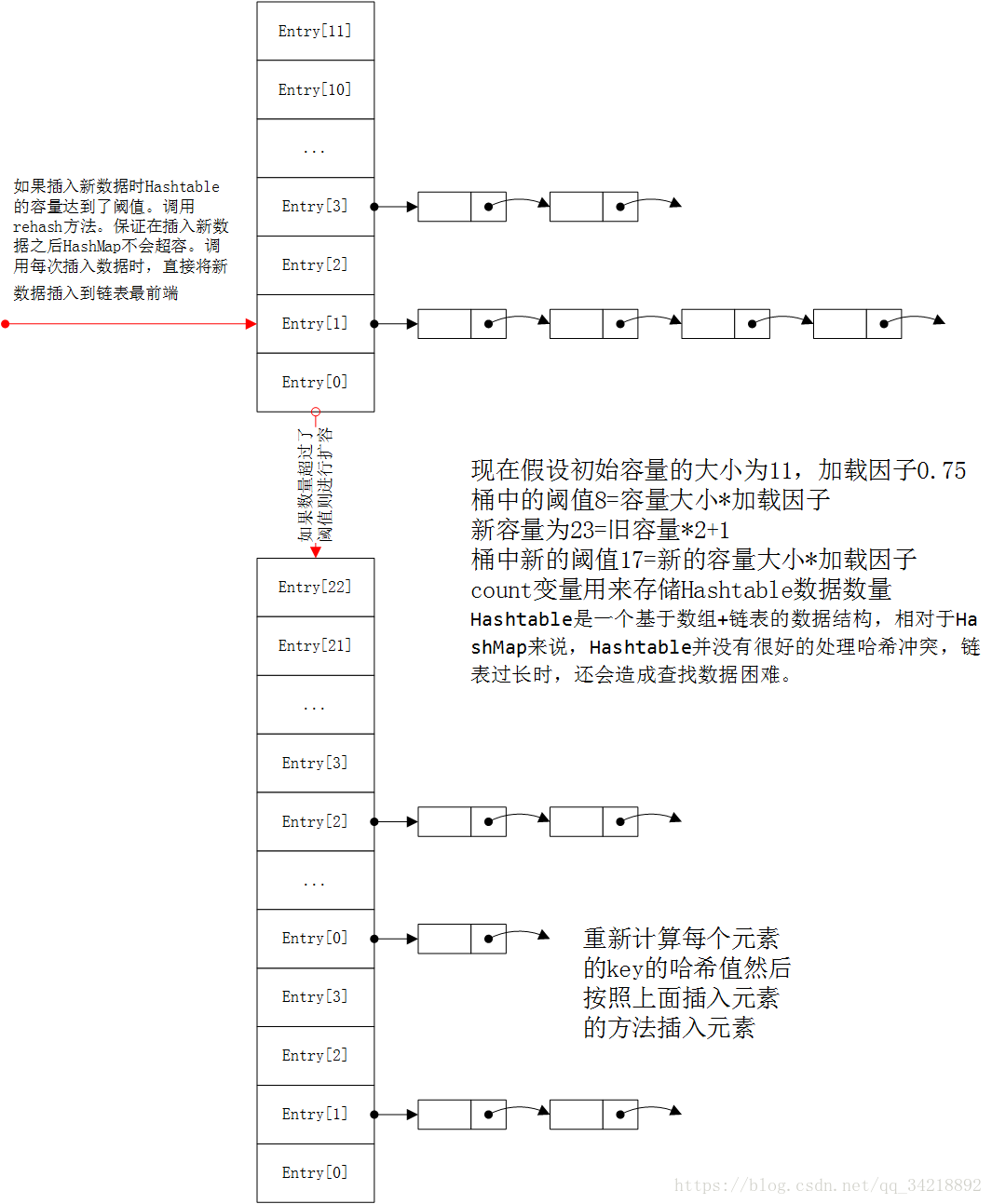
在看过了HashMap源码后,是不是现在看Hashtable的源码感觉轻松了不少呢?
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}Hashtable的get方法就是先求出元素的索引,然后遍历索引处的链表并将值返回出来。
Hashtable对并发的处理
Hashtable并没对并发做太多处理,只是使用重量级锁synchronied封装了方法。重量级锁的特点就是,如果当前存在锁竞争,那么其他线程都被阻塞,只有一个线程能够执行方法。显然,这并没有充分思考高并发的情景。
按理说到这里我应该做一个HashMap与Hashtable的区别的比较表。但是我们还要继续看ConcurrentHashMap的源码,我觉得到时候在一起比较会最好。